
LLMni ishda qoʻllashda boshida prompt'ni qanchalik qisqa va aniq yozish muhimligini his qilyapsiz. Men ham dastlab tokenlarni tejash uchun kiritayotgan jumlamni qisqartirishim kerak deb o'yladim.
Lekin Codex kabi agent tarzidagi dasturlash vositalarini ishlatish bilan fikrim o'zgardi. Aslida tokenlarni behuda sarflash ishchi tomonidan yozilgan jumlalar emas, balki vositadan qaytarilgan ma'lumotlardan ko'proq yuz berishi mumkin. MCP, fayl qidirish, kod o'qish, terminal natijalari kabi tashqi vositalar bog'langanda modelning konteksti foydalanuvchining prompt'i emas, vosita chiqishi bilan tezda to'ldiriladi.
Bu muammoni shaxsan his qilganim Figma va Storybook'ni sinxronlashtirish jarayonida bo'ldi. Figma dizaynini Storybook komponentlariga moslashtirish uchun Figma MCP'ni chaqirdim, lekin menga kerak bo'lgan ma'lumotlar layout, rang, tipografiya, masofa, variant darajasidanoq iborat edi. Biroq haqiqiy javobda Figma komponentlarining o'zgaruvchanlari, takrorlangan metama'lumotlar, aloqador bo'lmagan ichki xususiyatlar ko'p miqdorda kiritilgan edi.
Codex shaxsiy foydalanish muhitida API kabi input token, output token, cached token'ni to'g'ridan-to'g'ri ko'rish qiyin bo'lganligi sababli aniq tokenlar sonini tekshira olmadim. Biroq Figma MCP'ni chaqirishda shaxsiy Plus hisobimning 5 soatlik foydalanish ko'rsatkichi taxminan 91% dan 38% gacha keskin tushdi va haqiqiy amalga oshirishni boshlashdan oldin kontekst befoydali ma'lumotlar bilan to'sildi.
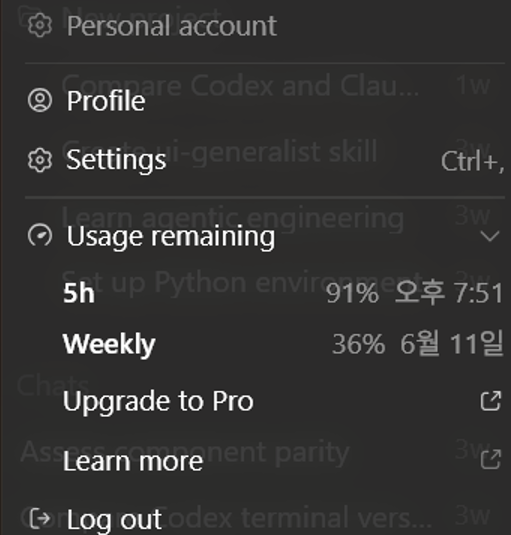
Rasm 1. Figma MCP chaqirishdan avval foydalanish ko'rsatkichi
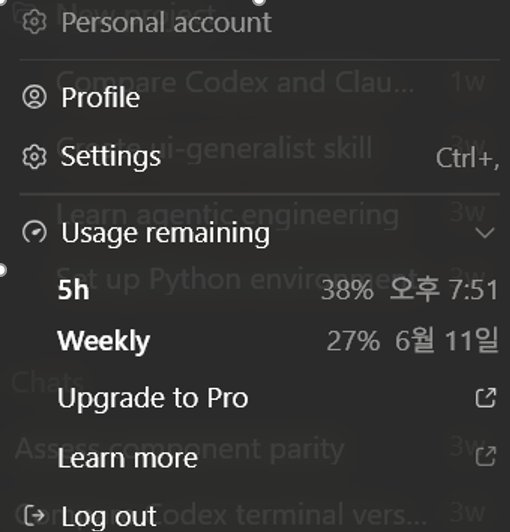
Rasm 2. Figma MCP chaqirishdan keyin foydalanish ko'rsatkichi
Boshida MCP natijasini olgandan so'ng agentga qisqartirishni aytaman deb o'yladim. Lekin bu usul asosiy yechim emas edi. Katta hajmdagi MCP javoblari allaqachon model kontekstiga kiritilgan bo'lsa, birinchi xarajat allaqachon yuz berdi. Keyinchalik qisqartirish keyingi ishning yukini kamaytirishi mumkin, lekin befoydali ma'lumotlarning boshidan modelga kirishini to'xtatmaydi.
Natijada yechim qisqartirish emas, balki oldindan filtratsiya edi. Men agentni use-figma vositasi orqali JavaScript kodini bajarishga majbur qildim va Figma tugunidan amalga oshirish uchun zarur bo'lgan maydonlarni ajratib oldim. Butun Figma ob'ektini to'g'ridan-to'g'ri o'tkazish o'rniga, zarur ma'lumotlarni tartibga solib kontekstga joylashtirdim.
|
Ta'rif |
Mavjud usul |
Yaxshilangan usul |
|---|---|---|
|
Ma'lumotlarni qayta ishlash |
MCP javobini butunlay modelga yo'llash |
JavaScript yordamida zarur maydonlarni ajratib olish |
|
Kontekst mazmuni |
O'zgaruvchilar, metama'lumotlar, ichki xususiyatlar kiritilgan |
layout, tipografiya, rang, holat markazida |
|
muammo |
amalga oshirilishidan oldin foydalanish miqdori keskin kamaydi |
zarur ma'lumotlar markazida ishlarni olib borish |
|
cheklov |
aniq tokenlar sonini tekshirib bo'lmaydi |
kvantlangan benchmark emas, balki kuzatuv asosidagi solishtirish |
Ushbu tajribadan so'ng tokenlarni optimallashtirishga boshqacha qaray boshladim. Asosiysi, promtlarni qisqa yozish emas, balki modelga nima yuborishni oldin belgilashdir.
1. Asboblar chiqishi modelga kirishdan oldin qisqarishi kerak
Agentxil dasturlash vositalarida asboblar chiqishi eng katta kontekstni ifloslantiruvchi omil bo'lishi mumkin. Foydalanuvchi promti qisqa bo‘lsa ham, MCP yoki faylni qidirish natijalari katta bo‘lsa, kontekst tezda keraksiz ma’lumotlar bilan to‘lib qoladi.
Figma MCP da aslida zarur bo'lgan ma'lumotlar cheklangan edi.
-
komponentlar iyerarxiyasi
-
Avto Layout yo'nalishi va tikish
-
width, height, padding, gap
-
Matn uslubi
-
rang va token nomi
-
variant va holat
-
Storybook amalga oshirishga nisbatan vizual farq
Buning aksincha, umumiy o'zgaruvchi jadvali, takroriy uslub metama'lumotlari, aloqador bo'lmagan sibling node, juda chuqur ichki xususiyatlar hozirgi vaqtda kerak emas edi. Muammo shundaki, bu kabi ma'lumotlar bir marta modelga kirganda dastlabki xarajatlar yuzaga keladi.
Shuning uchun oqimni o'zgartirish kerak.
나쁜 흐름:
외부 도구 → 응답 전체 → 모델 컨텍스트 → 요약
좋은 흐름:
외부 도구 → 필터링 → 필요한 정보만 → 모델 컨텍스트Olingandan so'ng, qisqartirishdan ko'ra, kirishdan oldin filtrdan o'tkazish afzal.
Figma ishida JavaScript yordamida kerakli xususiyatlarni faqat chiqarib oldik. Masalan, to'liq node ob'ektini o'tkazish o'rniga quyidagi kabi amalga oshirishda zarur bo'lgan tuzilmani saqlab qolishimiz mumkin.
const extracted = {
name: node.name,
type: node.type,
layout: {
mode: node.layoutMode,
padding: {
top: node.paddingTop,
right: node.paddingRight,
bottom: node.paddingBottom,
left: node.paddingLeft,
},
gap: node.itemSpacing,
},
size: {
width: node.width,
height: node.height,
},
styles: {
fills: simplifyFills(node.fills),
text: extractTextStyle(node),
},
children: node.children?.map(toShallowNode),
};Bu uslubning asosiy maqsadi LLMga ma'lumotlarni to'liq o'qitish imkonini bermaslikdir. Dastur avval ma'lumotlar miqdorini qisqartiradi va model muhim bo'lgan joylarga e'tibor qaratadi.
Bu printsip faqat Figma ga tegishli emas. API chaqiruvi paytida kerakli maydonlarni so'rash, ma'lumotlar bazasida SELECT * o'rniga kerakli ustunlarni ko'rish, log tahlilida esa to'liq log emas, balki xato satrlari va atrof-muhitni uzatish afzal.
Lekin filtrni haddan ortiq qilish, keyinchalik kerak bo'lishi mumkin bo'lgan ma'lumotlarni yo'qotishiga olib kelishi mumkin. Shuning uchun, shunchaki ozgina jo'natishdan ko'ra, ish maqsadiga mos kesish mezoni kerak.
Design extraction 기준:
- layout: 방향, 정렬, padding, gap, size
- typography: font size, weight, line height
- color: fill, stroke, semantic token name
- component: variant, state, child hierarchy
- 제외: 관련 없는 변수, 미사용 메타데이터, 원본 node 전체 덤프Tokenlarni qisqartirish uchun modelga kamroq berish emas, balki baholash uchun kerakli ma'lumotlarni berish kerak.
2. Kontekst yozuv emas, balki hozirgi ish holati sifatida boshqarilishi kerak.
Muloqot yozuvlari xotira singari tuyuladi, lekin agent uchun har safar qayta o'qish zarur. Oldingi muloqotlar, asboblarni bajarish natijalari, xato loglarini doimo saqlab turish foydali bo'lishi mumkin, ammo aslida bu baholash uchun zarur bo'lmagan ma'lumotlar yig'ilishi mumkin.
Kontekst saqlash joyi emas, balki ish maydoniga yaqin. Hozirgi baholash uchun zarur bo'lgan ma'lumotlar qolishi kerak. Eskirgan loglar, allaqachon hal qilingan xatolar, bekor qilingan rejalari, aloqador bo'lmagan fayl mazmuni doimiy ravishda qoldirilsa, xarajatlar oshadi va baholash xiralashadi.
Dasturiy ta'minot ishlab chiqarishda ham ishlash jurnali to'liq dasturning xotirasida saqlanmaydi. Zarur vaqtda qidiriladi, faqat kerakli qismlar o'qiladi va hozirgi holat alohida boshqariladi. Xuddi shunday usulda agentga ham to'liq suhbat tarixidan ko'ra hozirgi ish holatini uzatish yaxshiroqdir.
Masalan, agent Figma ma'lumotlarini o'qidi, Storybook faylini tekshirdi, komponentni o'zgartirdi va typecheck'dan o'ta olmay, yana o'zgartirgani haqida taxmin qilaylik. Barcha asl matnni doimiy saqlab turish shart emas. Keyingi jarayonda zarur bo'lgan holat quyidagicha.
Current goal:
Button variant를 Figma 기준으로 Storybook 구현과 맞춥니다.
Relevant files:
- Button.tsx
- Button.stories.tsx
- theme/tokens.ts
Decisions:
- raw color 사용 금지
- 기존 semantic token 우선 사용
Checks:
- typecheck 1차 실패: ButtonVariant union에 "soft" 없음
- 타입 수정 후 재검증 필요
Open issue:
- hover background token 일치 여부 확인 필요Bunday holat qisqacha bayon qilish asl logdan qisqaroq bo'lib, keyingi qaror uchun davolashda yanada samarali yordam beradi.
Yaxshi holat xulosaida hozirgi maqsad, tasdiqlangan qaror, o'zgartirilgan fayl, muvaffaqiyatsiz urinish, amalga oshirilgan tekshirish, qolgan xavf va keyingi harakat ko'rsatilishi kerak. Aksincha, allaqachon hal qilingan uzoq xato jurnal, takrorlangan fayl mazmuni, ma'nosiz terminal ogohlantirishlari va bekor qilingan rejaning batafsil tavsifi uzoq muddat saqlanishiga kam ehtiyoj bor.
Kontextni qisqartirish bu xotirani yo'qotish emas. Hozirgi ishga zarur holatni aniqroq qoldirishdir.
3. Agentning qidiruv doirasini qisqartirish kerak
Agentga mo'ljallangan dasturda tokenlar ko'p ishlatilishining yana bir sababi takroriy sikllardir. Bir marta berilgan savol uzun bo'lgandan ko'ra, noto'g'ri qidiruv va tuzatish bir necha marta takrorlanishi katta xarajatga ega bo'lishi mumkin.
Odatda uchraydigan muvaffaqiyatsiz oqimlar quyidagilardir.
-
Talab juda keng.
-
Agent ko'p faylni o'qiydi.
-
Maqsadsiz ma'lumotlarni ham tushunadi.
-
Implementatsiya doirasini noto'g'ri belgilaydi.
-
Sinov muvaffaqiyatsiz bo'ladi.
-
Muvaffaqiyat logini uzoq o'qiydi.
-
Yana o'zgartiradi.
-
Foydalanuvchi yo'nalishni qayta tushuntiradi.
Ushbu jarayonda tokenlar bilan birga odamning ko'rib chiqish vaqti ham behuda sarflanadi. Shuning uchun agentga ish topshirayotganda, avvalo, ish doirasini qisqartirish kerak.
Yomon talablar quyidagilar:
Figma랑 Storybook 맞춰줘.Ushbu talab juda keng. Agent qaysi Figma tugunlarini ko'rishi, qaysi Storybook komponentlarini o'zgartirishi va qaysi mezon asosida mos keladi deb hisoblashini o'z-o'zidan taxmin qilishi kerak.
Yaxshi talablar maqsad, ruxsat berilgan doira, taqiqlanganlar va tekshirish usullarini birga taqdim etadi.
Goal:
Figma의 Button / Soft / Medium / Disabled 상태를 Storybook Button과 맞춥니다.
Allowed context:
- 선택된 Figma node만 확인합니다.
- Button.tsx, Button.stories.tsx, theme token 파일만 우선 확인합니다.
Do not:
- 전체 Figma variable table을 dump하지 않습니다.
- public API를 변경하지 않습니다.
- raw color를 추가하지 않습니다.
Verify:
- typecheck
- Storybook 실행 또는 build 가능 여부
Final answer:
- 변경 파일
- 적용한 token
- 실행한 검증
- 남은 visual mismatchBunday ish paketlari birinchi kiritishda uzun ko'rinishi mumkin. Ammo umumiy ish xarajati kamayadi. Agent noto'g'ri faylni o'qish, keraksiz MCP chaqiruvlarini amalga oshirish yoki aloqasi bo'lmagan amalga oshirishni o'zgartirish imkoniyati kamayadi.
Ushbu nuqtai nazardan AGENTS.md, ko'nikmalar, tekshirish buyruqlari, bajarilish shartlari va taqiqlovchilar token optimizatsiyasi bilan bog'lanadi. Ular oddiy qulaylik hujjatlari emas, balki agentni keraksiz ravishda qidirishdan saqlovchi ish chegaralaridir.
Ish birligini loyihalashda, avval quyidagi savollarni tekshirish yaxshi.
-
Maqsad nima?
-
Tekshirilishi kerak bo'lgan fayl nima?
-
Tekshirilmasi kerak bo'lgan ma'lumot nima?
-
Taqiqlangan o'zgarishlar nima?
-
Muvaffaqiyatni qanday tekshirish mumkin?
-
Yakuniy hisobot qanday shaklda bo'lishi kerak?
Yaxshi ish birligi agentning erkinligini yo'q qilmaydi. Aksincha, keraksiz izlanish maydonini kamaytiradi.
Xulosa qilib aytganda
Bu tajribadan o‘rgangan eng katta narsa shundaki, token optimallashtirishning boshlanish nuqtasi prompt uzunligi emas. Agent turidagi dasturiy ta'minotda asbob chiqarishi, suhbat tarixlari, sinov jurnalari, fayl mazmuni, takrorlanuvchi o'zgartirish doiralari ham barchasi kontekstni egallaydi.
Figma MCP da yuzaga kelgan muammo esa men uzun prompt yozganim sababli bo‘lmagan edi. Dastur tomonidan qaytarilgan keraksiz ma'lumotlar birinchi navbatda kontekstni egalladi va agent haqiqiy amalga oshirishni boshlashdan oldin ish maydoni to'silgan edi.
Shuning uchun endi Codex dan foydalanayotganda, avval “Nimani so‘rashim kerak?” emas, balki “Nimani kontekstga kiritmasligim kerak?”ni aniqlayman.
Yaxshi token optimallashtirish modelga ma'lumotlarni yetishmovchilik qilmayoq berish emas. Model hukm qilishi kerak bo‘lgan ma'lumotlarni aniq berishdir.
Joseph