
LLM을 업무에 활용하다 보면 처음에는 프롬프트를 얼마나 짧고 명확하게 쓰는지가 가장 중요해 보입니다. 저도 처음에는 토큰을 아끼려면 제가 입력하는 문장을 줄이면 된다고 생각했습니다.
하지만 Codex 같은 에이전트형 개발 도구를 사용하면서 생각이 바뀌었습니다. 실제 토큰 낭비는 사용자가 직접 쓴 문장보다 도구가 반환한 데이터에서 더 크게 발생할 수 있습니다. MCP, 파일 검색, 코드 읽기, 터미널 실행 결과처럼 외부 도구가 연결되면 모델의 컨텍스트는 사용자의 프롬프트가 아니라 도구 출력으로 빠르게 채워집니다.
이 문제를 직접 체감한 것은 Figma와 Storybook을 동기화하는 작업에서였습니다. Figma 디자인을 Storybook 컴포넌트와 맞추기 위해 Figma MCP를 호출했는데, 제가 필요했던 정보는 레이아웃, 색상, Typography, 간격, variant 정도였습니다. 그러나 실제 응답에는 Figma 컴포넌트의 변수, 중복된 메타데이터, 관련 없는 내부 속성까지 대량으로 포함되어 있었습니다.
Codex 개인 사용 환경에서는 API처럼 input token, output token, cached token을 직접 확인하기 어렵기 때문에 정확한 토큰 수를 확인할 수는 없었습니다. 다만 Figma MCP 호출 시 개인 Plus 계정의 5시간 사용량 표시가 약 91%에서 38%까지 급격히 떨어졌고, 실제 구현을 시작하기도 전에 컨텍스트가 불필요한 정보로 막혔습니다.
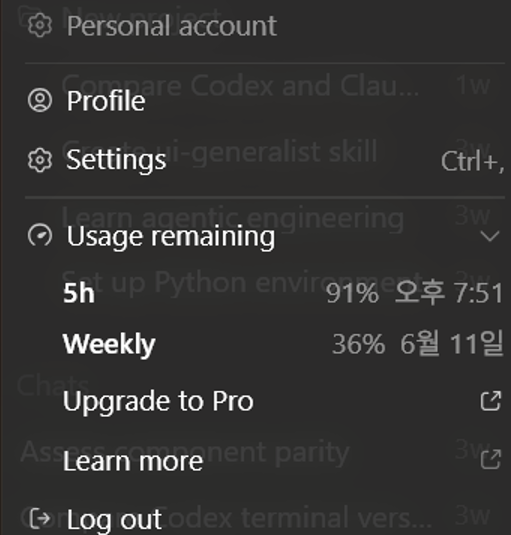
그림 1. Figma MCP 호출 전 사용량 표시
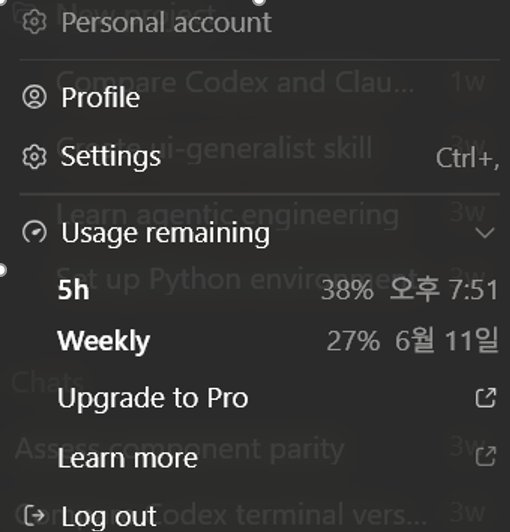
그림 2. Figma MCP 호출 후 사용량 표시
처음에는 MCP 결과를 받은 뒤 에이전트에게 요약시키면 된다고 생각했습니다. 하지만 이 방식은 근본적인 해결책이 아니었습니다. 대량의 MCP 응답이 이미 모델 컨텍스트에 들어온 뒤라면 첫 번째 비용은 이미 발생한 상태입니다. 이후 요약은 다음 작업의 부담을 줄일 수는 있지만, 불필요한 데이터가 처음부터 모델에 들어오는 문제를 막지는 못합니다.
결국 해결책은 요약이 아니라 사전 필터링이었습니다. 저는 에이전트가 use-figma 도구를 통해 JavaScript 코드를 실행하도록 만들고, Figma 노드에서 구현 판단에 필요한 필드만 추출하게 했습니다. 전체 Figma 객체를 그대로 넘기는 대신, 필요한 정보만 정리해서 컨텍스트에 넣은 것입니다.
|
구분 |
기존 방식 |
개선 방식 |
|---|---|---|
|
데이터 처리 |
MCP 응답 전체를 모델에 전달 |
JavaScript로 필요한 필드만 추출 |
|
컨텍스트 내용 |
변수, 메타데이터, 내부 속성 포함 |
layout, typography, color, state 중심 |
|
문제 |
구현 전 사용량 표시가 급감 |
필요한 정보 중심으로 작업 진행 |
|
한계 |
정확한 토큰 수 확인 불가 |
정량 벤치마크가 아닌 관찰 기반 비교 |
이 경험 이후 토큰 최적화를 다르게 보게 되었습니다. 핵심은 프롬프트를 짧게 쓰는 것이 아니라, 모델에게 무엇을 보낼지 먼저 정하는 것입니다.
1. 도구 출력은 모델에 들어가기 전에 줄여야 합니다
에이전트형 개발 도구에서는 도구 출력이 가장 큰 컨텍스트 오염원이 될 수 있습니다. 사용자의 프롬프트가 짧아도 MCP나 파일 검색 결과가 크면 컨텍스트는 금방 불필요한 정보로 채워집니다.
Figma MCP에서 실제로 필요했던 정보는 제한적이었습니다.
-
컴포넌트 계층 구조
-
Auto Layout 방향과 정렬
-
width, height, padding, gap
-
텍스트 스타일
-
색상과 토큰 이름
-
variant와 state
-
Storybook 구현 대비 시각적 차이
반대로 전체 변수 테이블, 중복된 스타일 메타데이터, 관련 없는 sibling node, 지나치게 깊은 내부 속성은 당장 필요하지 않았습니다. 문제는 이런 정보가 한 번 모델에 들어오면 이미 비용이 발생한다는 점입니다.
그래서 흐름을 바꿔야 합니다.
나쁜 흐름:
외부 도구 → 응답 전체 → 모델 컨텍스트 → 요약
좋은 흐름:
외부 도구 → 필터링 → 필요한 정보만 → 모델 컨텍스트받은 뒤 줄이는 것보다, 들어오기 전에 거르는 편이 낫습니다.
Figma 작업에서는 JavaScript로 필요한 속성만 추출했습니다. 예를 들면 전체 node 객체를 넘기는 대신 다음과 같이 구현 판단에 필요한 구조만 남길 수 있습니다.
const extracted = {
name: node.name,
type: node.type,
layout: {
mode: node.layoutMode,
padding: {
top: node.paddingTop,
right: node.paddingRight,
bottom: node.paddingBottom,
left: node.paddingLeft,
},
gap: node.itemSpacing,
},
size: {
width: node.width,
height: node.height,
},
styles: {
fills: simplifyFills(node.fills),
text: extractTextStyle(node),
},
children: node.children?.map(toShallowNode),
};이 방식의 핵심은 LLM에게 데이터를 모두 읽힌 뒤 판단하게 하지 않는 것입니다. 코드가 먼저 데이터 양을 줄이고, 모델은 의미 판단이 필요한 부분에 집중합니다.
이 원칙은 Figma에만 적용되지 않습니다. API를 호출할 때는 필요한 필드만 요청하고, 데이터베이스에서는 SELECT * 대신 필요한 컬럼만 조회하며, 로그 분석에서는 전체 로그가 아니라 에러 라인과 주변 문맥만 전달하는 것이 좋습니다. 코드 리뷰에서도 전체 저장소보다 변경된 diff와 관련 파일만 넘기는 편이 낫습니다.
다만 필터링을 과하게 하면 나중에 필요한 정보까지 빠질 수 있습니다. 그래서 무조건 적게 보내기보다 작업 목적에 맞는 추출 기준이 필요합니다.
Design extraction 기준:
- layout: 방향, 정렬, padding, gap, size
- typography: font size, weight, line height
- color: fill, stroke, semantic token name
- component: variant, state, child hierarchy
- 제외: 관련 없는 변수, 미사용 메타데이터, 원본 node 전체 덤프토큰을 줄이려면 모델에게 덜 주는 것이 아니라, 판단에 필요한 정보만 주어야 합니다.
2. 컨텍스트는 기록이 아니라 현재 작업 상태로 관리해야 합니다
대화 기록은 기억처럼 느껴지지만, 에이전트에게는 매번 다시 읽어야 하는 입력입니다. 이전 대화, 도구 실행 결과, 실패 로그를 계속 남겨두면 도움이 될 것 같지만, 실제로는 판단에 필요 없는 정보가 계속 누적될 수 있습니다.
컨텍스트는 저장소가 아니라 작업 공간에 가깝습니다. 지금 판단에 필요한 정보만 남아 있어야 합니다. 오래된 로그, 이미 해결된 에러, 폐기된 계획, 관련 없는 파일 내용이 계속 남아 있으면 비용은 늘고 판단은 흐려집니다.
소프트웨어 개발에서도 운영 로그 전체를 애플리케이션 메모리에 올려두지 않습니다. 필요한 시점에 검색하고, 필요한 부분만 읽고, 현재 상태는 별도로 관리합니다. 같은 방식으로 에이전트에게도 전체 대화 기록보다 현재 작업 상태를 넘기는 편이 낫습니다.
예를 들어 에이전트가 Figma 정보를 읽고, Storybook 파일을 확인하고, 컴포넌트를 수정하고, typecheck에서 실패한 뒤 다시 수정했다고 가정하겠습니다. 이 모든 원문이 계속 남을 필요는 없습니다. 다음 단계에 필요한 것은 아래와 같은 상태입니다.
Current goal:
Button variant를 Figma 기준으로 Storybook 구현과 맞춥니다.
Relevant files:
- Button.tsx
- Button.stories.tsx
- theme/tokens.ts
Decisions:
- raw color 사용 금지
- 기존 semantic token 우선 사용
Checks:
- typecheck 1차 실패: ButtonVariant union에 "soft" 없음
- 타입 수정 후 재검증 필요
Open issue:
- hover background token 일치 여부 확인 필요이런 상태 요약은 원문 로그보다 짧고, 다음 판단에 더 직접적으로 도움이 됩니다.
좋은 상태 요약에는 현재 목표, 확정된 결정, 변경한 파일, 실패한 접근, 실행한 검증, 남은 위험, 다음 행동이 남아야 합니다. 반대로 이미 해결된 긴 에러 로그, 중복된 파일 내용, 의미 없는 터미널 경고, 폐기한 계획의 상세 설명은 오래 보관할 필요가 적습니다.
컨텍스트를 줄인다는 것은 기억을 버리는 것이 아닙니다. 현재 작업에 필요한 상태를 더 정확하게 남기는 일입니다.
3. 에이전트의 탐색 범위를 줄여야 합니다
에이전트형 개발 도구에서 토큰이 많이 쓰이는 또 다른 이유는 반복 루프입니다. 한 번의 프롬프트가 긴 것보다, 잘못된 탐색과 수정이 여러 번 반복되는 것이 더 큰 비용이 될 수 있습니다.
흔한 실패 흐름은 다음과 같습니다.
-
요청이 너무 넓습니다.
-
에이전트가 많은 파일을 읽습니다.
-
관련 없는 정보까지 해석합니다.
-
구현 범위를 잘못 잡습니다.
-
테스트가 실패합니다.
-
실패 로그를 길게 읽습니다.
-
다시 수정합니다.
-
사용자가 다시 방향을 설명합니다.
이 과정에서는 토큰뿐 아니라 사람의 검토 시간도 낭비됩니다. 따라서 에이전트에게 일을 맡길 때는 작업 범위를 먼저 좁혀야 합니다.
나쁜 요청은 다음과 같습니다.
Figma랑 Storybook 맞춰줘.이 요청은 너무 넓습니다. 에이전트는 어떤 Figma 노드를 볼지, 어떤 Storybook 컴포넌트를 수정할지, 어떤 기준으로 맞췄다고 판단할지 스스로 추측해야 합니다.
더 나은 요청은 목표, 허용 범위, 금지 사항, 검증 방법을 함께 제공합니다.
Goal:
Figma의 Button / Soft / Medium / Disabled 상태를 Storybook Button과 맞춥니다.
Allowed context:
- 선택된 Figma node만 확인합니다.
- Button.tsx, Button.stories.tsx, theme token 파일만 우선 확인합니다.
Do not:
- 전체 Figma variable table을 dump하지 않습니다.
- public API를 변경하지 않습니다.
- raw color를 추가하지 않습니다.
Verify:
- typecheck
- Storybook 실행 또는 build 가능 여부
Final answer:
- 변경 파일
- 적용한 token
- 실행한 검증
- 남은 visual mismatch이런 작업 패킷은 첫 입력만 보면 길어 보일 수 있습니다. 하지만 전체 작업 비용은 줄어듭니다. 에이전트가 잘못된 파일을 읽거나, 불필요한 MCP 호출을 하거나, 관련 없는 구현을 수정할 가능성이 줄기 때문입니다.
이 관점에서 AGENTS.md, skills, 체크 명령어, 완료 조건, 금지 규칙도 토큰 최적화와 연결됩니다. 이들은 단순한 편의 문서가 아니라 에이전트가 불필요하게 탐색하지 않도록 만드는 작업 경계입니다.
작업 단위를 설계할 때는 다음 질문을 먼저 확인하는 것이 좋습니다.
-
목표는 무엇인가?
-
확인해야 할 파일은 무엇인가?
-
확인하지 말아야 할 정보는 무엇인가?
-
금지되는 변경은 무엇인가?
-
성공 여부를 어떻게 검증할 것인가?
-
최종 보고는 어떤 형식이어야 하는가?
좋은 작업 단위는 에이전트의 자유도를 없애지 않습니다. 대신 불필요한 탐색 공간을 줄입니다.
마치며
이번 경험에서 가장 크게 배운 점은 토큰 최적화의 출발점이 프롬프트 길이가 아니라는 것입니다. 에이전트형 개발 도구에서는 도구 출력, 대화 기록, 테스트 로그, 파일 내용, 반복되는 수정 루프가 모두 컨텍스트를 차지합니다.
Figma MCP에서 겪은 문제도 제가 긴 프롬프트를 써서 발생한 것이 아니었습니다. 도구가 반환한 불필요한 정보가 먼저 컨텍스트를 차지했고, 에이전트가 실제 구현을 시작하기 전에 작업 공간이 막혔습니다.
그래서 이제 Codex를 사용할 때는 “무엇을 물어볼까?”보다 먼저 “무엇을 컨텍스트에 넣지 말아야 할까?”를 확인합니다.
좋은 토큰 최적화는 모델에게 정보를 부족하게 주는 일이 아닙니다. 모델이 판단해야 할 정보만 정확하게 주는 일입니다.
Joseph