
When utilizing LLMs for work, it initially seems most important to write prompts as short and clear as possible. I also thought at first that I could just shorten the sentences I input to save tokens.
However, my perspective changed while using agent-type development tools like Codex. In reality, token wastage can occur more significantly in the data returned by the tool than in the sentences written directly by the user. When external tools like MCP, file search, code reading, or terminal execution results are involved, the model's context gets rapidly filled with tool outputs rather than the user's prompts.
I felt this issue firsthand while synchronizing Figma and Storybook. I called the Figma MCP to match the Figma design with Storybook components, but the information I needed was just layout, color, typography, spacing, and variants. However, the actual response included a large amount of variables from Figma components, duplicate metadata, and unrelated internal attributes.
In the personal usage environment of Codex, it was difficult to check input tokens, output tokens, and cached tokens directly like an API, so I couldn't verify the exact number of tokens. However, when calling the Figma MCP, the usage display on my personal Plus account dramatically dropped from about 91% to 38%, and the context was filled with unnecessary information even before I started the actual implementation.
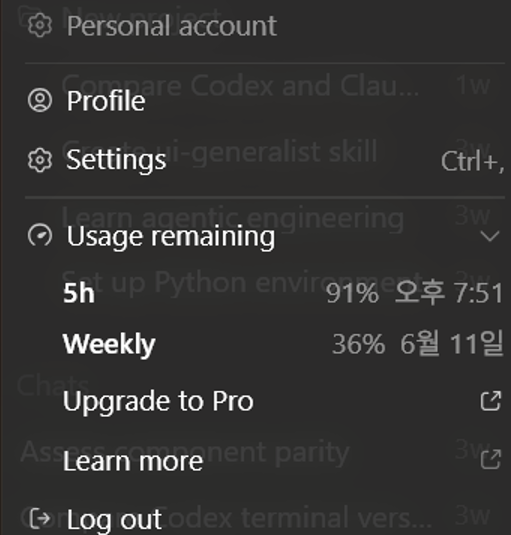
Figure 1. Usage display before calling Figma MCP
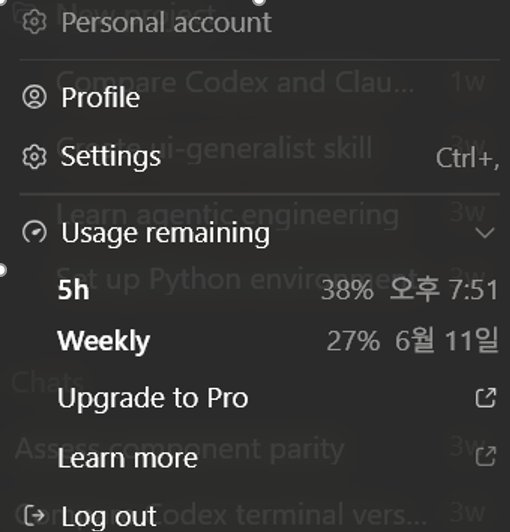
Figure 2. Usage display after calling Figma MCP
Initially, I thought I could just have the agent summarize after receiving the MCP results. However, this approach was not a fundamental solution. If the large MCP responses have already entered the model's context, the first cost has already occurred. The subsequent summarization may reduce the burden of the next task, but it doesn't prevent unnecessary data from entering the model from the beginning.
Ultimately, the solution was not summarization but pre-filtering. I made the agent execute JavaScript code through the use-figma tool and extracted only the fields necessary for implementation judgment from the Figma node. Instead of passing the entire Figma object as is, I organized only the necessary information and put it into the context.
|
Category |
Existing Method |
Improved Method |
|---|---|---|
|
Data Processing |
Pass the entire MCP response to the model |
Extract only the necessary fields with JavaScript |
|
Context Content |
Variables, metadata, and internal properties included |
Focus on layout, typography, color, and state |
|
Problem |
Display usage sharply decreased before implementation |
Proceed with work centered around necessary information |
|
Limitations |
Unable to accurately check the number of tokens |
Observation-based comparison rather than quantitative benchmarks |
After this experience, I view token optimization differently. The key is not to write short prompts, but to first determine what to send to the model.
1. Tool output needs to be reduced before entering the model
In agent-based development tools, tool output can be the largest source of context contamination. Even if the user's prompt is short, if the MCP or file search results are large, the context quickly fills with unnecessary information.
The information actually needed from the Figma MCP was limited.
-
Component hierarchy
-
Auto Layout direction and alignment
-
width, height, padding, gap
-
Text Style
-
Color and Token Name
-
Variant and State
-
Visual Differences Compared to Storybook Implementation
On the contrary, an entire variable table, redundant style metadata, unrelated sibling nodes, and excessively deep internal properties were not immediately necessary. The problem is that once this information enters the model, costs are already incurred.
So we need to change the flow.
나쁜 흐름:
외부 도구 → 응답 전체 → 모델 컨텍스트 → 요약
좋은 흐름:
외부 도구 → 필터링 → 필요한 정보만 → 모델 컨텍스트It's better to filter before it comes in than to reduce after receiving it.
In Figma work, we extracted only the necessary properties using JavaScript. For example, instead of passing the entire node object, we can structure it to leave only what is needed for implementation judgment.
const extracted = {
name: node.name,
type: node.type,
layout: {
mode: node.layoutMode,
padding: {
top: node.paddingTop,
right: node.paddingRight,
bottom: node.paddingBottom,
left: node.paddingLeft,
},
gap: node.itemSpacing,
},
size: {
width: node.width,
height: node.height,
},
styles: {
fills: simplifyFills(node.fills),
text: extractTextStyle(node),
},
children: node.children?.map(toShallowNode),
};The key to this approach is not letting the LLM make judgments after reading all the data. The code reduces the amount of data first, and the model focuses on areas requiring meaning judgment.
This principle does not only apply to Figma. When calling an API, only the necessary fields should be requested, in databases, instead of SELECT * only the necessary columns should be queried, and in log analysis, it's better to transmit only error lines and surrounding context rather than entire logs. In code reviews, it's also better to pass only the changed diffs and related files rather than the entire repository.
However, if filtering is excessive, it may exclude information that is needed later. Therefore, instead of sending as little as possible, it is necessary to have extraction criteria that align with the purpose of the task.
Design extraction 기준:
- layout: 방향, 정렬, padding, gap, size
- typography: font size, weight, line height
- color: fill, stroke, semantic token name
- component: variant, state, child hierarchy
- 제외: 관련 없는 변수, 미사용 메타데이터, 원본 node 전체 덤프To reduce tokens, it is essential to provide only the information necessary for judgment to the model, not less data.
2. Context should be managed as the current state of work, not as a record.
The conversation history may feel like memory, but for the agent, it is input that needs to be read again each time. Keeping previous conversations, tool execution results, and error logs may seem helpful, but in reality, unneeded information may continue to accumulate regarding judgments.
Context is closer to a workspace than a repository. Only information necessary for current judgment should be left. If old logs, resolved errors, discarded plans, and unrelated file contents remain, costs will increase and judgments will become unclear.
In software development, we do not keep the entire operational log in application memory. We search at the necessary times, read only the needed parts, and manage the current state separately. In the same way, it is better to pass the current working state to the agent rather than the entire conversation history.
For example, let’s assume the agent reads Figma information, checks Storybook files, modifies components, fails a typecheck, and then modifies again. There is no need for all of this original text to remain. What is needed for the next step is a state like the one below.
Current goal:
Button variant를 Figma 기준으로 Storybook 구현과 맞춥니다.
Relevant files:
- Button.tsx
- Button.stories.tsx
- theme/tokens.ts
Decisions:
- raw color 사용 금지
- 기존 semantic token 우선 사용
Checks:
- typecheck 1차 실패: ButtonVariant union에 "soft" 없음
- 타입 수정 후 재검증 필요
Open issue:
- hover background token 일치 여부 확인 필요Such a state summary is shorter than the original log and helps directly with the next judgment.
A good state summary should include the current goal, confirmed decisions, modified files, failed attempts, validations performed, remaining risks, and next actions. Conversely, detailed descriptions of long error logs that have already been resolved, duplicated file contents, meaningless terminal warnings, and discarded plans do not need to be kept for long.
Reducing context does not mean discarding memory. It is about retaining the state that is more accurate for the current task.
3. We need to reduce the agent's scope of exploration.
Another reason tokens are heavily used in agent-based development tools is the repetition loop. A single long prompt can be a bigger cost than multiple instances of incorrect exploration and corrections.
A common failure flow is as follows.
-
The request is too broad.
-
The agent reads many files.
-
It interprets irrelevant information.
-
It misdefines the scope of implementation.
-
Tests fail.
-
It reads the failure logs for too long.
-
It modifies again.
-
The user explains the direction again.
In this process, not only tokens but also human review time is wasted. Therefore, when assigning tasks to agents, the scope of work should first be narrowed down.
A bad request looks like this.
Figma랑 Storybook 맞춰줘.This request is too broad. The agent has to guess which Figma nodes to look at, which Storybook components to modify, and what criteria should be used to determine matching.
A better request provides goals, allowed scope, prohibitions, and validation methods together.
Goal:
Figma의 Button / Soft / Medium / Disabled 상태를 Storybook Button과 맞춥니다.
Allowed context:
- 선택된 Figma node만 확인합니다.
- Button.tsx, Button.stories.tsx, theme token 파일만 우선 확인합니다.
Do not:
- 전체 Figma variable table을 dump하지 않습니다.
- public API를 변경하지 않습니다.
- raw color를 추가하지 않습니다.
Verify:
- typecheck
- Storybook 실행 또는 build 가능 여부
Final answer:
- 변경 파일
- 적용한 token
- 실행한 검증
- 남은 visual mismatchSuch work packets may seem lengthy at first glance. However, the overall cost of work decreases. This is because the agent is less likely to read the wrong files, make unnecessary MCP calls, or modify irrelevant implementations.
From this perspective, AGENTS.md, skills, check commands, completion conditions, and prohibited rules are also connected to token optimization. These are not merely convenience documents, but task boundaries that prevent agents from navigating unnecessarily.
When designing work units, it is advisable to first check the following questions.
-
What is the goal?
-
What files need to be checked?
-
What information should not be checked?
-
What changes are prohibited?
-
How will success be validated?
-
What format should the final report take?
A good work unit does not eliminate the agent's freedom. Instead, it reduces unnecessary exploration space.
In conclusion
The most important lesson I learned from this experience is that the starting point of token optimization is not the length of the prompt. In agent-type development tools, tool output, conversation history, test logs, file content, and repetitive modification loops all occupy context.
The issue I encountered in Figma MCP was not caused by my writing a long prompt. The unnecessary information returned by the tool occupied the context first, and the workspace was blocked before the agent could begin actual implementation.
So now, when using Codex, I check 'What should I not include in the context?' before asking 'What should I ask?'.
Good token optimization does not mean providing the model with insufficient information. It means giving exactly the information that the model needs to make judgments.
Joseph