
Когда вы начинаете использовать LLM в работе, сначала кажется, что наиболее важным является то, насколько коротко и четко вы пишете запросы. Я также думал в начале, что чтобы сэкономить токены, мне нужно сократить вводимые мной предложения.
Однако, используя такие инструменты-разработчики, как Codex, я изменил свое мнение. На самом деле, потери токенов могут происходить в значительной степени при данных, возвращаемых инструментами, а не при предложениях, написанных пользователем. Когда подключаются внешние инструменты, такие как MCP, поиск файлов, чтение кода, результаты выполнения терминала, контекст модели заполняется не пользовательским запросом, а выводом инструмента.
Я прочувствовал эту проблему непосредственно во время работы по синхронизации Figma и Storybook. Чтобы согласовать дизайн Figma с компонентами Storybook, я вызвал Figma MCP, но мне нужна была информация о макете, цветах, типографике, интервалах, вариантах. Однако фактический ответ содержал огромное количество переменных компонентов Figma, дублирующей метаданных и нерелевантных внутренних свойств.
В личной рабочей среде Codex было трудно проверить точное количество токенов, так как такие как input token, output token, cached token не видны напрямую. Однако во время вызова Figma MCP использование моего личного аккаунта Plus резко упало с 91% до 38%, и контекст забился ненужной информацией еще до начала реальной реализации.
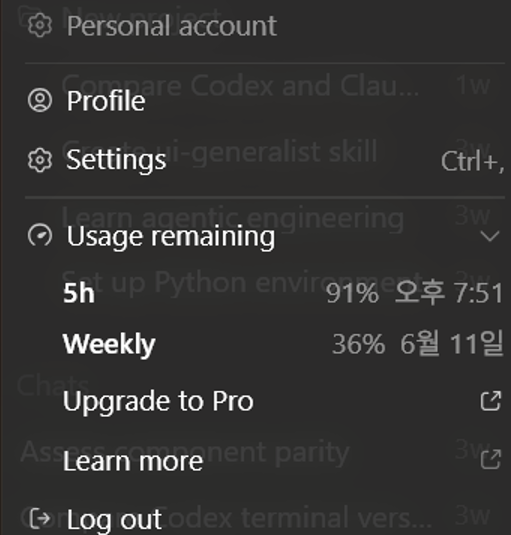
Рисунок 1. Показатели использования до вызова Figma MCP
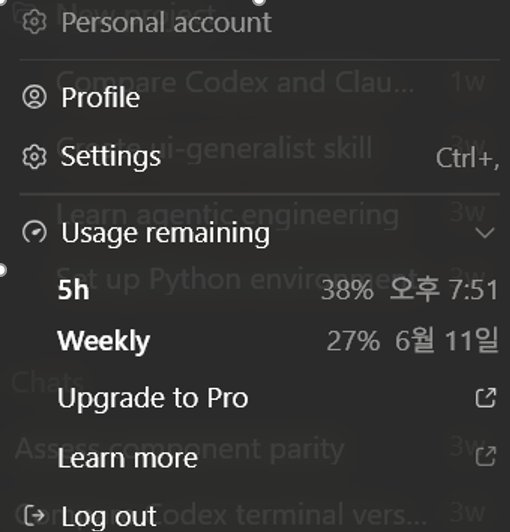
Рисунок 2. Показатели использования после вызова Figma MCP
Сначала я думал, что после получения результата MCP достаточно будет попросить агента сделать его кратким. Но этот подход не является основным решением. Если большой объем ответов MCP уже попал в контекст модели, первый расход уже произошел. Далее, краткость может уменьшить нагрузку на следующие задачи, но не предотвратит попадание ненужных данных в модель с самого начала.
В конечном итоге решения не было в краткости, а в предварительной фильтрации. Я заставил агента выполнять JavaScript-код через инструмент use-figma и извлекать только необходимые поля для принятия решений от узла Figma. Вместо передачи всего объекта Figma, я структурировал только нужную информацию в контекст.
|
Разделитель |
Существующий метод |
Улучшенный метод |
|---|---|---|
|
Обработка данных |
Передача всего ответа MCP в модель |
Извлечение только необходимых полей на JavaScript |
|
Содержание контекста |
переменные, метаданные, внутренние свойства включены |
центрируемся на макете, типографии, цвете, состоянии |
|
проблема |
перед реализацией потребление резко снизилось |
работа сосредоточена на необходимой информации |
|
ограничения |
невозможно точно проверить количество токенов |
сравнение на основе наблюдений, а не количественных бенчмарков |
После этого опыта я стал по-другому смотреть на оптимизацию токенов. Ключ в том, чтобы сначала определить, что отправить модели, а не просто писать короткие подсказки.
1. Вывод инструмента должен быть сокращен перед тем, как попасть в модель
В инструментах разработки типа агент вывод инструмента может стать самым большим источником загрязнения контекста. Даже если подсказка пользователя короткая, если результаты поиска MCP или файла велики, контекст быстро заполняется ненужной информацией.
На самом деле, информация, которая мне была нужна в Figma MCP, была ограниченной.
-
иерархия компонентов
-
направление и выравнивание авто-раскладки
-
ширина, высота, отступ, промежуток
-
Стиль текста
-
Название цвета и токена
-
вариант и состояние
-
Визуальные отличия по сравнению с реализацией Storybook
Напротив, вся таблица переменных, дублирующиеся метаданные стилей, нерелевантные узлы-соседи и чрезмерно глубокие внутренние свойства не были нужны на данный момент. Проблема в том, что такая информация уже вызывает затраты, когда она попадает в модель.
Поэтому нужно изменить поток.
나쁜 흐름:
외부 도구 → 응답 전체 → 모델 컨텍스트 → 요약
좋은 흐름:
외부 도구 → 필터링 → 필요한 정보만 → 모델 컨텍스트Лучше отфильтровать информацию до ее поступления, чем уменьшать после получения.
В работе с Figma я извлекал только необходимые свойства с помощью JavaScript. Например, вместо передачи всего объекта узла, можно оставить только ту структуру, которая необходима для принятия решения.
const extracted = {
name: node.name,
type: node.type,
layout: {
mode: node.layoutMode,
padding: {
top: node.paddingTop,
right: node.paddingRight,
bottom: node.paddingBottom,
left: node.paddingLeft,
},
gap: node.itemSpacing,
},
size: {
width: node.width,
height: node.height,
},
styles: {
fills: simplifyFills(node.fills),
text: extractTextStyle(node),
},
children: node.children?.map(toShallowNode),
};Ключевым моментом этого подхода является то, что LLM не должен принимать решения, читая все данные. Код сначала уменьшает объем данных, а модель сосредоточивается на тех аспектах, где необходимо смысловое суждение.
Этот принцип применим не только к Figma. При вызове API следует запрашивать только необходимые поля, в базе данных — выбирать только необходимые колонки вместо SELECT *, а в анализе журналов лучше передавать не весь журнал, а только строки с ошибками и их контекст.
Тем не менее, чрезмерная фильтрация может привести к тому, что важная информация впоследствии будет упущена. Поэтому необходимо установить критерии извлечения, соответствующие целям задачи, а не просто отправлять минимальное количество данных.
Design extraction 기준:
- layout: 방향, 정렬, padding, gap, size
- typography: font size, weight, line height
- color: fill, stroke, semantic token name
- component: variant, state, child hierarchy
- 제외: 관련 없는 변수, 미사용 메타데이터, 원본 node 전체 덤프Чтобы уменьшить количество токенов, нужно давать модели не меньше информации, а только ту, которая необходима для принятия решения.
2. Контекст должен управляться как текущим состоянием работы, а не как записью.
История разговоров кажется памятью, но для агента это каждый раз ввод, который нужно снова читать. Хотя оставление предыдущих разговоров, результатов выполнения инструментов и журналов ошибок может показаться полезным, на самом деле это приводит к накоплению ненужной информации для суждений.
Контекст ближе к рабочему пространству, чем к репозиторию. Должны оставаться только те данные, которые необходимы для текущего суждения. Если остаются устаревшие записи, уже решенные ошибки, отмененные планы и нерелевантные содержимое файлов, это увеличивает затраты и затуманивает суждение.
В разработке программного обеспечения все операционные логи не хранятся в памяти приложения. Их ищут в нужный момент, читают только необходимые части, а текущее состояние управляется отдельно. Таким же образом агенту лучше передавать текущее состояние работы, чем всю историю разговора.
Например, предположим, что агент читает информацию из Figma, проверяет файлы Storybook, вносит изменения в компоненты и, после сбоя в проверке типов, снова вносит изменения. Не обязательно сохранять весь текст. Для следующего шага необходимо следующее состояние.
Current goal:
Button variant를 Figma 기준으로 Storybook 구현과 맞춥니다.
Relevant files:
- Button.tsx
- Button.stories.tsx
- theme/tokens.ts
Decisions:
- raw color 사용 금지
- 기존 semantic token 우선 사용
Checks:
- typecheck 1차 실패: ButtonVariant union에 "soft" 없음
- 타입 수정 후 재검증 필요
Open issue:
- hover background token 일치 여부 확인 필요Такое резюме состояния короче оригинального лога и более непосредственно помогает в следующих решениях.
В хорошем резюме состояния должны оставаться текущие цели, подтвержденные решения, измененные файлы, неудачные подходы, выполненные проверки, оставшиеся риски и следующие действия. Напротив, длинные логи ошибок, которые уже решены, дублирующее содержание файлов, несущественные предупреждения терминала и подробные описания отложенных планов не требуют долгого хранения.
Сокращение контекста не значит потерять память. Это более точная информация о состоянии, необходимом для текущей работы.
3. Необходимо сократить область поиска агента
Еще одна причина, по которой токены часто используются в инструментах разработки с агентами, — это повторяющиеся циклы. Один длинный запрос может обойтись дороже, чем многократные неправильные поиски и исправления.
Распространенный поток неудач выглядит следующим образом.
-
Запрос слишком широкий.
-
Агент читает много файлов.
-
Интерпретирует нерелевантную информацию.
-
Неправильно определяет область реализации.
-
Тесты проваливаются.
-
Долго читает логи ошибок.
-
Снова вносит изменения.
-
Пользователь снова объясняет направление.
В этом процессе тратится не только токен, но и время на проверку человеком. Поэтому, когда вы поручаете работу агенту, вам сначала нужно уточнить область работы.
Плохие запросы выглядят следующим образом.
Figma랑 Storybook 맞춰줘.Этот запрос слишком широк. Агент должен сам предполагать, какие узлы Figma он увидит, какие компоненты Storybook он изменит и по каким критериям он определит, что все сделано правильно.
Лучшие запросы предоставляют цель, допустимый диапазон, ограничения и методы проверки.
Goal:
Figma의 Button / Soft / Medium / Disabled 상태를 Storybook Button과 맞춥니다.
Allowed context:
- 선택된 Figma node만 확인합니다.
- Button.tsx, Button.stories.tsx, theme token 파일만 우선 확인합니다.
Do not:
- 전체 Figma variable table을 dump하지 않습니다.
- public API를 변경하지 않습니다.
- raw color를 추가하지 않습니다.
Verify:
- typecheck
- Storybook 실행 또는 build 가능 여부
Final answer:
- 변경 파일
- 적용한 token
- 실행한 검증
- 남은 visual mismatchТакие пакеты задач могут показаться длинными, если посмотреть только на первый ввод. Но общая стоимость работы снижается. Это связано с тем, что вероятность того, что агент прочитает неправильный файл, сделает ненужные вызовы MCP или изменит нерелевантные реализации, уменьшается.
С этой точки зрения AGENTS.md, навыки, команды проверки, условия завершения и запрещенные правила также связаны с оптимизацией токенов. Это не просто удобные документы, а границы задач, которые не позволяют агенту ненадлежащим образом исследовать.
При проектировании единиц работы хорошо начать с проверки следующих вопросов.
-
Какова цель?
-
Какие файлы необходимо проверить?
-
Какую информацию не следует проверять?
-
Каковы запрещенные изменения?
-
Как будет проверяться успешность?
-
Какой должна быть конечная отчетность?
Хорошая единица работы не лишает агента свободы. Вместо этого она сокращает ненужное пространство для исследований.
В заключение
Главный урок, который я вынес из этого опыта, заключается в том, что отправная точка оптимизации токенов — это не длина запроса. В инструментах разработки на основе агентов выводы инструментов, журнал бесед, тестовые логи, содержимое файлов и повторяющиеся модификационные циклы — все это занимает контекст.
Проблема, с которой я столкнулся в Figma MCP, также не была вызвана тем, что я использовал длинный запрос. Ненужная информация, возвращаемая инструментом, сначала заняла контекст, и рабочее пространство было заблокировано до того, как агент начал фактическую реализацию.
Поэтому теперь, используя Codex, я сначала проверяю не «что спросить?», а «что не следует помещать в контекст?».
Хорошая оптимизация токенов не означает, что модель получает недостаточное количество информации. Это значит предоставить модели только ту информацию, которую она должна оценить.
Joseph