1. Observabilityni yengil qilish zarurati
Zamonaviy bulut va Kubernetes asosidagi infratuzilish muhitida Observability tizim boshqaruvining asosiy elementi hisoblanmoqda.
Xizmat hajmi kattalashgani sayin, log, metrik va izlash asosida tizim holatini kuzatish va muammolarni tezda tahlil qilish qobiliyati juda muhim bo'ladi.
Xususan, MSA (Mikroservis Arxitekturasi) asosidagi tuzilmalarda ko'plab xizmatlar tarqatilgan holda ishlaganda oddiy ilova loglari bilan muammo sabablarini aniqlash qiyin.
Shu sababdan ko'p muqovalarda Loki + Promtail + Prometheus + Grafana kombinatsiyasi eng mashhur Observability stek hisoblanadi.
Ushbu kombinatsiya ochiq manba asosidagi ekotizim juda yaxshi tashkil etilganligi va Kubernetes muhitiga oson integratsiyasi sababli, asosan standart stek sifatida ishlatiladigan holatlar ko'pdir.
Ammoqiy muhitda bunday an'anaviy tuzilmalar ham ko'plab cheklovlarga duch kelgan.
Eng katta muammo - bu resurs sarfi edi. Promtail va node-exporter har biri alohida DaemonSet shaklida ishlaydi va har bir tugunda alohida Podlar yaratiladi.
Ya'ni, tugunlar soni ortib borishi bilan agent Pod'lari soni ham ortadi.
Shuningdek, Prometheus xotira asosidagi TSDB (Vaqt Qatorlari Ma'lumotlar Bazasini) ishlatadi, shuning uchun metrikalar yig'ilishi ortgan sayin xotira sarfi ham tezda ortadi.
Xususan kichik Kubernetes klasterlari yoki Edge muhitlarida bunday tuzilma katta yuk bo'lib xizmat qildi.
Masalan, quyidagi muhitlarda mavjud Observability steki ortiqcha resurslarni talab qilishi mumkin.
-
Yagona tugunli Kubernetes klasteri
-
ARM asosidagi Edge qurilmalari
-
Sanoat IoT Gateway
-
Xarajatni optimallashtirish muhim bo'lgan rivojlanish muhit
-
Kichik on-premises muhit
Loyihada haqiqatan ham cheklangan resurslarga ega muhitda Observability tuzilmasini boshqarishimiz kerak edi va mavjud stack tuzilmasida CPU va xotira iste'moli juda yuqori bo'lishi bilan bog'liq muammo bor edi.
Xususan metrik saqlash va log saqlash alohida ishlayotganda, operatsion murakkablik ham oshib bormoqda.
Nihoyat, mavjud stek bilan imkon qadar moslikni saqlab, ancha engil va samarali tuzilma kerak edi.
Buni hal qilish uchun Grafana Alloy + VictoriaLogs + VictoriaMetrics asosidagi yengil konfiguratsiyani ko'rib chiqish va uni haqiqiy ish sharoitida qo'llashga majbur bo'ldik.
2. Mavjud Observability stekining tuzilishi va cheklovlari
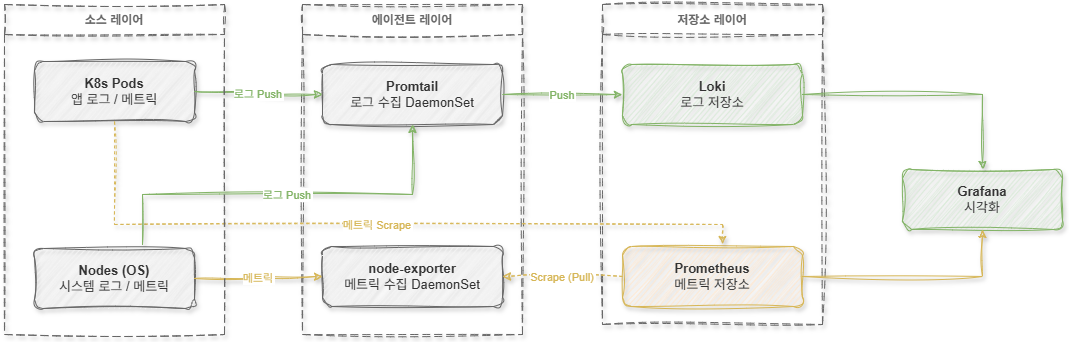
Mavjud Observability stek Loki + Promtail + Prometheus + Grafana tuzilmasidan iborat edi. Ushbu tuzilishda jurnal va metriklarni yig'ish mustaqil ravishda ishlaydi.
Birinchidan, jurnal yig'ish Promtail tomonidan amalga oshiriladi. Promtail Kubernetes tugunidan konteyner jurnal fayllarini o'qiydi va ularni Loki ga Push qiladi.
Biroq, metrikalarni yig'ish node-exporter va Prometheus kombinatsiyasidan iborat. Node-exporter CPU, xotira, disk va tarmoq holati kabi OS metrikalarni ko'rsatadi va Prometheus buni Pull usuli bilan muntazam ravishda yig'adi.
Ya'ni, log va metrikalarni yig'ish tuzilmasi butunlay ajratilgan edi.
[ Tuzilish oqim diagrammasi (Legacy Stack) ]
Ushbu tuzilma etarlicha barqaror va sinovdan o'tgan uslub edi, ammo haqiqiy ishlash jarayonida bir qancha muammolar yuzaga keldi.
Birinchisi agentlar sonini oshirish masalasi edi.
Promtail va node-exporter alohida DaemonSet sifatida ishlayotganligi sababli, har bir tugun uchun kamida ikkita Observability Pod ishga tushdi.
Ko'rsatkichlar podi uchun kam sonli tugunlar mavjud bo'lgan muhitda aslida resurs ulushi nisbatan juda yuqori bo'lishi mumkin edi.
Ikkinchisi esa xotira ishlatilishi muammosi edi.
Prometheus metrik ma'lumotlarini xotira asosidagi TSDB-ga saqlaydi.
Shuning uchun metrik yig'ilishi oshgan sari xotira ishlatish ham deyarli chiziqli ravishda oshadi. Haqiqiy ish muhitida metriklar soni ko'paygan sari Prometheus xotira ishlatishining tez oshishi hodisasini tasdiqladik.
Uchinchisi operatsion murakkablikni oshirish edi.
Promtail, node-exporter va Prometheus har biri turli xil sozlash fayli tuzilishiga ega bo'lganligi sababli, operator bir vaqtning o'zida bir nechta sozlash tuzilmalarini boshqarishi kerak edi.
Shuningdek, har bir komponentning yangilanishi va versiyalarini moslashtirish alohida amalga oshirilishi kerak edi.
Xususan, Edge muhitida saqlash diskidan foydalanish ham muhim muammo edi. Loki indeks va siqish strukturasining xususiyatlari tufayli, loglar soni oshganda diskdan foydalanish tezda ortishi mumkin edi.
Nihoyat loyiha quyidagi maqsadlarni ko'zda tutgan yengil tuzilmani yangidan loyihalashga olib keldi.
-
Yagona agentga asoslangan tuzilma
-
Xotira ishlatish miqdorini minimallashtirish
-
Jurnal saqlash samaradorligini oshirish
-
Mavjud Grafana dashtlarini qayta ishlatilishi mumkin
-
Prometheus va Loki ekotizimlari bilan moslikni saqlab qolish
-
Boshqaruv murakkabligini kamaytirish
3. Grafana Alloy asosidagi integratsiya to'plov tuzilmasi
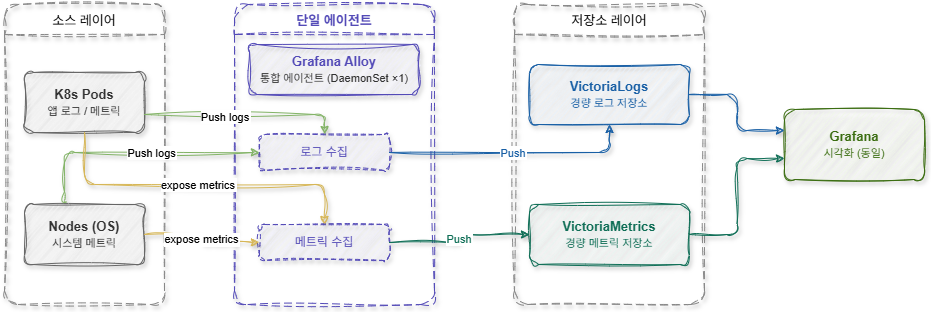
Yengil vaziyatni tashkil etishning asosi yig‘ish agentlarini Grafana Alloy bilan birlashtirish edi.
Grafana Alloy OpenTelemetry asosidagi integratsiyalashgan Observability agenti bo‘lib, bir vaqtda loglar va metrikalarni yig‘ish uchun tuzilmani taqdim etadi. Avvalgi tuzilmada Promtail va node-exporter alohida ishlagan bo‘lsa, Grafana Alloy bitta bilan ikkita funktsiyani bajara olgan.
Ya'ni, mavjud ikkita DaemonSetni bitta birlashgan holda yig'ish imkoniyatiga ega bo'ldik. Ushbu tuzilma faqat Pod sonini kamaytirishdan ko'ra ko'proq afzalliklar taqdim etdi.
Eng katta afzallik resursdan foydalanish samaradorligi edi.
Avval har bir agent mustaqil jarayon sifatida ishlaydi va CPU hamda xotiradan har biri alohida foydalanar edi, lekin Alloy asosidagi tuzilishda bir jarayon ichida log va metrikalarni yig‘ish bir vaqtda amalga oshiriladi. Natijada tugunning agent xotira foydalanish miqdorini keskin kamaytira olishimiz mumkin bo‘ldi.
Shuningdek, sozlamalarni boshqarish ham ancha soddalashtirildi. Avval Promtail sozlamasi va Prometheus Scrape sozlamalarini alohida boshqarish zarur edi, lekin Alloyda yagona sozlama fayli asosida hammasini boshqarish mumkin bo‘ldi. Bu amaliyot murakkabligini sezilarli darajada kamaytirdi. Loyihada Alloy Kubernetes muhiti ichida DaemonSet shaklida tarqatildi.
Alloy bir vaqtning o'zida quyidagi rollarni bajarish uchun tuzilgan.
-
Kubernetes loglarni yig'ish
-
Node metriklarni yig'ish
-
Container metriklarni yig'ish
-
Kubernetes xizmatlarini aniqlash
-
Jurnal teglashi
-
Metrik belgilash
[ Yengil stack tuzilishi ) ]
Xususan, OpenTelemetry asosidagi tuzilma bo'lgani uchun kelgusi Tracinggacha kengaytirilishi mumkinligi katta afzallik edi.
Biroq, ushbu loyihada faqat Logging va Metricni engillashtirishga e'tibor qaratildi, Tracing esa qo'llanilish doirasidan chiqarildi.
Natijada, faqat Grafana Alloy'ni joriy etish orqali agent tuzilmasini sezilarli darajada soddalashtirish mumkin bo'ldi va ishni barqarorlashtirish ham yaxshilandi.
4. VictoriaLogs va VictoriaMetrics joriy etilishi
Yig'uv agentlarini integratsiyalashdan keyin keyingi qadam Storage ni yengillashtirishdir.
Loyihada eski Loki va Prometheus ni VictoriaLogs va VictoriaMetrics bilan almashtirdik. VictoriaMetrics, Prometheus ga mos keluvchi TSDB bo'lib, juda yuqori siqish darajasi va past xotira ishlatish qobiliyati bilan ajralib turadi.
Xususan, bir xil metrik yig‘ish hajmi asosida Prometheusga nisbatan xotira iste'moli ancha kam ekanligi afzallikdir.
Amaliy sinov muhitida VictoriaMetrics oldingi Prometheusga nisbatan taxminan 7 marta xotira iste'molini kamaytirish samaradorligini tasdiqladi.
Shuningdek, u PromQL-ni to'g'ridan-to'g'ri qo'llab-quvvatlashi tufayli, mavjud Grafana boshqaruv panelining aksariyatini tuzatmasdan ishlatish imkoniyatiga ega bo'ldik.
Bu operatsion muhitga o'tish vaqtida juda katta afzallik edi. Agar so'rov tili yoki API tuzilishi butunlay boshqacha bo'lsa, eski boshqaruv paneli va xabardorlik sozlamalarini qayta yozish kerak bo'lardi.
Biroq, VictoriaMetrics Prometheus API bilan yuqori moslashuvchanlikni taqdim etgani uchun migratsiya yuklamasi juda oz edi. Log saqlash joyi ham Loki o'rniga VictoriaLogsdan foydalanildi. VictoriaLogs yuqori siqilgan log saqlash joyi sifatida ishlab chiqilgan va Loki API bilan yuqori moslashuvchanlikni taqdim etadi.
Xususan, diskdan foydalanishning kamayishi juda a'lo bo'ldi. Sinov muhiti sharoitida eski Loki ga nisbatan diskdan foydalanish 30 barobar qadar kamaygan holatlarni ko'rish mumkin edi. Bu uzoq muddatli log saqlash talab etiladigan muhitlarda sezilarli xarajatlarni tejashga yordam berdi.
Shuningdek, qidirish tezligi ham juda tez ishladi. Loyihada haqiqiy operatsion jurnal ma'lumotlariga asoslangan qidiruv faoliyatini sinovdan o'tkazdik va mavjud Loki ga nisbatan ancha barqaror javob tezligini tekshirdik.
Natijada, VictoriaLogs va VictoriaMetrics kombinatsiyasi nafaqat oddiy yengillik, balki operatsion samaradorlik va saqlash xarajatlarini kamaytirish masalalarida ham juda samarali tanlov bo'ldi.
5. Mavjud tarkibni va yengil tarkibni taqqoslash
Mavjud tarkib va yengil tarkibning eng katta farqi tuzilishning soddalashtirilishi va resurs samaradorligida edi.
|
Tasnif |
Mavjud tuzilma |
yengil tuzilma |
|---|---|---|
|
log agenti |
Promtail (DaemonSet) |
Grafana Alloy |
|
Metrix agent |
node-exporter (DaemonSet) |
Grafana Alloy |
|
agent soni |
2 ta DaemonSet |
1 ta DaemonSet |
|
Agent xotira (dona ko'rinishi) |
~120 MB (60+60) |
~60 MB |
|
jurnallar ombori |
Loki |
VictoriaLogs |
|
Metrix ombori |
Prometheus |
VictoriaMetrics |
|
Saqlash xotirasi (jami) |
~2 GB+ |
~800 MB |
|
sozlamalar fayli |
2ta alohida boshqarish |
1 ta birlashtirilgan boshqaruv |
* VictoriaMetrics Prometheusga nisbatan xotiradan taxminan 7 baravar kam foydalanadi va VictoriaLogs Loki ga nisbatan disk foydalanishini maksimal 30 baravar kamaytiradi.
Mavjud tuzilmada quyidagi komponentlar mustaqil ravishda ishladi.
-
Promtail
-
node-exporter
-
Prometheus
-
Loki
-
Grafana
Birodanda, yengil tuzilish quyidagicha soddalashtirildi.
-
Grafana Alloy
-
VictoriaLogs
-
VictoriaMetrics
-
Grafana
Xüsusilə, eng diqqatga sazovor o'zgarish agentlar sonining kamayishi edi. Avval logger va metrikalar yig'ish uchun ikkita DaemonSet zarur edi, ammo yengil konfiguratsiyada bitta Grafana Alloy bilan integratsiya qilish mumkin edi.
Natijada, tugun boshiga xotira foydalanish ham sezilarli darajada kamaydi.
Avvalgi tuzilishda agent xotira sarfi taxminan 120MB edi, ammo Alloy asosidagi tuzilishda bu taxminan 60MB ga kamaydi. Saqlash xotira sarfi farqi yanada kattaroq edi.
Prometheus va Loki kombinatsiyasida umumiy xotira iste'moli taxminan 2GB dan oshdi, ammo Victoria qatoridagi saqlash tizimiga asoslangan tuzilishda taxminan 800MB darajasigacha kamaydi.
Bu yagona tugunli klaster yoki Edge muhitida juda katta farqni yaratdi.
Shuningdek, operatsion jihatdan ham afzalliklar mavjud edi. Avvalgi o'rnatish fayllari va versiyalarini alohida boshqarish kerak edi, ammo engil tuzilishda boshqarish nuqtalari sezilarli darajada kamaydi. Grafana avvalgi kabi saqlanib qoldi, shuning uchun dasboard va Alert Qoidasi ham deyarli o'zgarmasdan qayta foydalanish imkoniyatiga ega bo'ldik.
Ya'ni, foydalanuvchilar mavjud operatsion tajribalarini saqlab qolib, ichki Observability tuzilmasini engillashtirish imkoniga ega bo'lishdi.
Natijada, ushbu engillashtirish jarayoni faqatgina resurslarni tejashdan ko'ra ko'proq ma'noga ega bo'ldi. Cheklangan resurs muhitida Observability-ni barqaror saqlab qolish mumkin bo'lgan barqaror tuzilmani qurish jihatidan juda muhim loyiha edi.
6. Xulosa
Observability zamonaviy infratuzilma muhitida endi tanlov emas, balki majburiy elementga aylandi. Ammo barcha muhitlar keng ko'lamli bulut infratuzilmasi darajasidagi resurslarga ega emas.
Xususan, kichik Kubernetes klasterlari yoki Edge muhitlarida cheklangan CPU va xotira ichida barqaror ish rejimini tashkil etish kerak.
Ushbu loyihada Grafana Alloy + VictoriaLogs + VictoriaMetrics kombinatsiyasi orqali mavjud Observability stekini ancha yengil va samarali tuzilishga o'tkazish imkoniyatiga ega bo'ldik.
Xususan, quyidagi afzalliklarni his qildik.
-
Agent tuzilishini soddalashtirish
-
Xotira iste'moli kamayishi
-
Diskni ishlatish miqdorini kamaytirish
-
Sozlamalarni boshqarishni oddiylashtirish
-
Mavjud Grafana muhitini qayta ishga solish mumkin
-
Boshqa komponentlar bilan yuqori moslashuvchanlikni saqlab qolish
Eng muhim nuqta, mavjud Prometheus va Loki ekotizimlariyla moslikni saqlab qolish bilan birga, boshqaruv xarajatlarini sezilarli darajada kamaytirish imkoniyatidir.
Bu oddiy xarajatlarni kamaytirishdan ko'ra, cheklangan resurslar doirasida yanada barqaror va barqaror ishlash muhitini yaratish imkoniyatini ta'minlovchi strategik tanlovdir. Kelajakda Tracing qatnashgan holda butun OpenTelemetry asosidagi tuzilmalarga kengayish ehtimoli mavjud deb umid qilmoqda.
Ushbu tajriba orqali Observability faqatgina ko'p ma'lumotlarni yig'ish emas, balki operatsion muhitga mos samarali tuzilmani loyihalash juda muhimligini yana bir bor tasdiqlay oldim.
[Manbalar]
Sean