1. Observability 경량화가 필요한 이유
현대 클라우드 및 Kubernetes 기반 인프라 환경에서 Observability는 시스템 운영의 핵심 요소로 자리 잡고 있습니다.
서비스 규모가 커질수록 로그(Log), 메트릭(Metric), 트레이싱(Tracing)을 기반으로 시스템 상태를 관찰하고 문제를 빠르게 분석할 수 있는 능력이 매우 중요해집니다.
특히 MSA(Microservice Architecture) 기반 구조에서는 수많은 서비스가 분산되어 동작하기 때문에 단순 애플리케이션 로그만으로는 장애 원인을 파악하기 어렵습니다.
이러한 이유로 많은 환경에서 Loki + Promtail + Prometheus + Grafana 조합이 대표적인 Observability 스택으로 사용되고 있습니다.
해당 조합은 오픈소스 기반 생태계가 매우 잘 구축되어 있고 Kubernetes 환경과의 연동도 뛰어나기 때문에 사실상 표준 스택처럼 사용되는 경우가 많습니다.
하지만 실제 운영 환경에서는 이러한 전통적인 구성에도 여러 한계가 존재했습니다.
가장 큰 문제는 리소스 사용량이었습니다. Promtail과 node-exporter는 각각 별도의 DaemonSet 형태로 동작하며 노드마다 개별 Pod가 생성됩니다.
즉, 노드 수가 증가할수록 에이전트 Pod 수도 함께 증가하게 됩니다.
또한 Prometheus는 메모리 기반 TSDB(Time Series Database)를 사용하기 때문에 메트릭 수집량이 증가할수록 메모리 사용량 역시 빠르게 증가하는 특성이 있습니다.
특히 소규모 Kubernetes 클러스터나 Edge 환경에서는 이러한 구조가 상당한 부담으로 작용했습니다.
예를 들어 다음과 같은 환경에서는 기존 Observability 스택이 과도한 리소스를 요구할 수 있었습니다.
-
단일 노드 Kubernetes 클러스터
-
ARM 기반 Edge 디바이스
-
산업용 IoT Gateway
-
비용 최적화가 중요한 개발 환경
-
소규모 온프레미스 환경
프로젝트에서는 실제로 제한된 자원을 가진 환경에서 Observability 구성을 운영해야 했으며, 기존 스택 구조로는 CPU와 메모리 사용량이 지나치게 높다는 문제가 있었습니다.
특히 메트릭 저장소와 로그 저장소가 각각 별도로 동작하면서 운영 복잡도도 함께 증가하고 있었습니다.
결국 기존 스택과 최대한 호환성을 유지하면서도 훨씬 가볍고 효율적인 구조가 필요했습니다.
이를 해결하기 위해 Grafana Alloy + VictoriaLogs + VictoriaMetrics 기반의 경량화 구성을 검토하고 실제 운영 환경에 적용하게 되었습니다.
2. 기존 Observability 스택 구조와 한계
기존 Observability 스택은 Loki + Promtail + Prometheus + Grafana 구조로 구성되어 있었습니다. 이 구조에서는 로그와 메트릭 수집이 각각 독립적인 방식으로 동작합니다.
먼저 로그 수집은 Promtail이 담당합니다. Promtail은 Kubernetes 노드에서 컨테이너 로그 파일을 읽어 Loki로 Push하는 역할을 수행합니다.
반면 메트릭 수집은 node-exporter와 Prometheus 조합으로 구성됩니다. node-exporter는 CPU, 메모리, 디스크, 네트워크 상태와 같은 OS 메트릭을 노출하고, Prometheus가 이를 Pull 방식으로 주기적으로 수집합니다.
즉, 로그와 메트릭 수집 구조가 완전히 분리된 형태였습니다.
[ 구성 흐름도 (Legacy Stack) ]
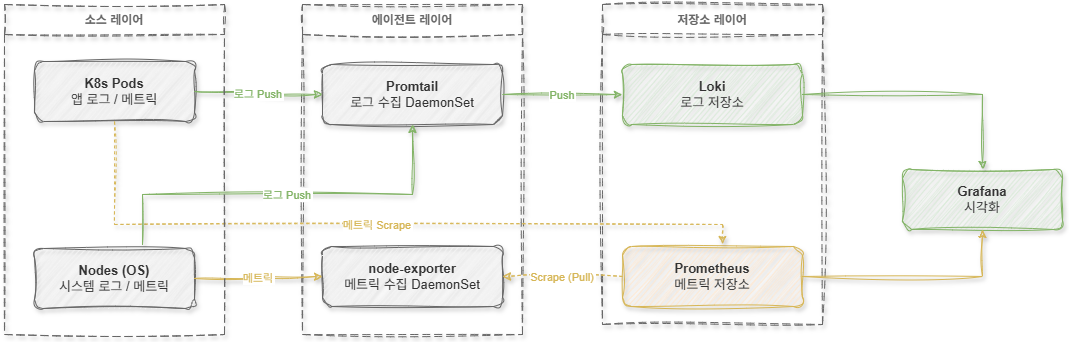
이 구조는 충분히 안정적이고 검증된 방식이었지만 실제 운영 과정에서는 여러 문제가 발생했습니다.
첫 번째는 에이전트 수 증가 문제였습니다.
Promtail과 node-exporter가 각각 별도 DaemonSet으로 동작하기 때문에 노드당 최소 두 개 이상의 Observability Pod가 실행되었습니다.
노드 수가 많지 않은 환경에서는 Observability Pod 자체가 차지하는 리소스 비율이 상대적으로 매우 높아질 수 있었습니다.
두 번째는 메모리 사용량 문제였습니다.
Prometheus는 메트릭 데이터를 메모리 기반 TSDB에 저장합니다.
따라서 메트릭 수집량이 증가할수록 메모리 사용량 역시 거의 선형적으로 증가하게 됩니다. 실제 운영 환경에서도 메트릭 수가 많아질수록 Prometheus 메모리 사용량이 빠르게 증가하는 현상을 확인할 수 있었습니다.
세 번째는 운영 복잡도 증가였습니다.
Promtail, node-exporter, Prometheus는 각각 설정 파일 구조가 다르기 때문에 운영자는 여러 설정 구조를 동시에 관리해야 했습니다.
또한 각 컴포넌트의 업그레이드 및 버전 호환성 관리 역시 별도로 수행해야 했습니다.
특히 Edge 환경에서는 저장소 디스크 사용량 역시 중요한 문제였습니다. Loki는 인덱스 및 압축 구조 특성상 로그량이 많아질수록 디스크 사용량이 빠르게 증가하는 경우가 있었습니다.
결국 프로젝트에서는 다음과 같은 목표를 가진 경량화 구조를 새롭게 설계하게 되었습니다.
-
단일 에이전트 기반 구조
-
메모리 사용량 최소화
-
로그 저장 효율 향상
-
기존 Grafana 대시보드 재사용 가능
-
Prometheus 및 Loki 생태계와의 호환성 유지
-
운영 복잡도 감소
3. Grafana Alloy 기반 통합 수집 구조
경량화 구성의 핵심은 수집 에이전트를 Grafana Alloy로 통합하는 것이었습니다.
Grafana Alloy는 OpenTelemetry 기반의 통합 Observability Agent로, 로그와 메트릭을 동시에 수집할 수 있는 구조를 제공합니다. 기존 구조에서는 Promtail과 node-exporter가 각각 별도로 동작했지만, Grafana Alloy 하나만으로 두 역할을 모두 수행할 수 있었습니다.
즉, 기존 두 개의 DaemonSet을 하나로 통합할 수 있게 된 것입니다. 이러한 구조는 단순히 Pod 개수를 줄이는 수준 이상의 장점을 제공했습니다.
가장 큰 장점은 리소스 효율성이었습니다.
기존에는 각각의 에이전트가 독립적인 프로세스로 동작하면서 CPU와 메모리를 각각 사용하고 있었지만, Alloy 기반 구조에서는 하나의 프로세스 안에서 로그와 메트릭 수집이 동시에 수행됩니다. 그 결과 노드당 에이전트 메모리 사용량을 크게 줄일 수 있었습니다.
또한 설정 관리 역시 훨씬 단순해졌습니다. 기존에는 Promtail 설정과 Prometheus Scrape 설정을 각각 따로 관리해야 했지만, Alloy에서는 단일 설정 파일 기반으로 모두 관리할 수 있었습니다. 이는 운영 복잡도를 크게 낮추는 효과를 가져왔습니다. 프로젝트에서는 Kubernetes 환경에서 Alloy를 DaemonSet 형태로 배포했습니다.
Alloy는 다음 역할을 동시에 수행하도록 구성했습니다.
-
Kubernetes 로그 수집
-
Node 메트릭 수집
-
Container 메트릭 수집
-
Kubernetes Service Discovery
-
로그 라벨링
-
메트릭 라벨링
[ 경량화 구성 흐름도 (Lightweight Stack) ]
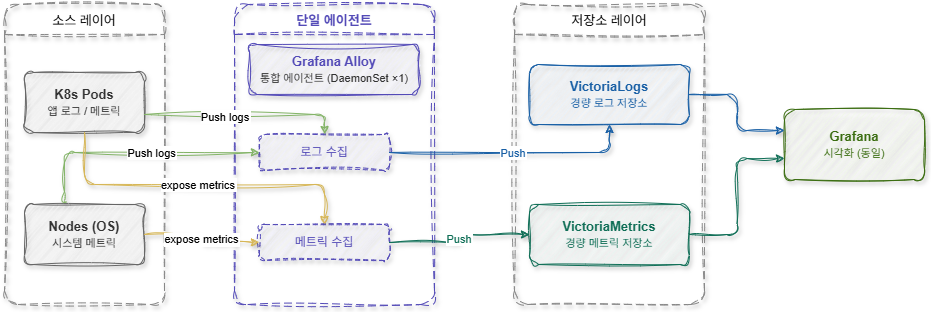
특히 OpenTelemetry 기반 구조이기 때문에 향후 Tracing까지 확장 가능하다는 점도 큰 장점이었습니다.
다만 이번 프로젝트에서는 Logging과 Metric 경량화에만 집중했으며, Tracing은 적용 범위에서 제외했습니다.
결과적으로 Grafana Alloy 도입만으로도 에이전트 구조를 상당히 단순화할 수 있었으며 운영 안정성 역시 향상되는 효과를 얻을 수 있었습니다.
4. VictoriaLogs와 VictoriaMetrics 도입
수집 에이전트 통합 이후 다음 단계는 저장소(Storage) 경량화였습니다.
프로젝트에서는 기존 Loki와 Prometheus를 각각 VictoriaLogs와 VictoriaMetrics로 대체했습니다. VictoriaMetrics는 Prometheus 호환 TSDB로, 매우 높은 압축률과 낮은 메모리 사용량을 특징으로 합니다.
특히 동일한 메트릭 수집량 기준으로 Prometheus 대비 메모리 사용량이 훨씬 적다는 장점이 있습니다.
실제 테스트 환경에서도 VictoriaMetrics는 기존 Prometheus 대비 약 7배 수준까지 메모리 사용량이 감소하는 효과를 확인할 수 있었습니다.
또한 PromQL을 그대로 지원하기 때문에 기존 Grafana 대시보드 대부분을 수정 없이 그대로 사용할 수 있었습니다.
이는 운영 환경 전환 시 매우 큰 장점이었습니다. 만약 쿼리 언어나 API 구조가 완전히 달랐다면 기존 대시보드와 Alert 설정을 모두 다시 작성해야 했을 것입니다.
반면 VictoriaMetrics는 Prometheus API와 높은 호환성을 제공하기 때문에 마이그레이션 부담이 매우 적었습니다. 로그 저장소 역시 Loki 대신 VictoriaLogs를 사용했습니다. VictoriaLogs는 고압축 로그 저장소로 설계되어 있으며 Loki API와 높은 호환성을 제공합니다.
특히 디스크 사용량 절감 효과가 매우 뛰어났습니다. 테스트 환경에서는 기존 Loki 대비 최대 30배 수준까지 디스크 사용량이 감소하는 사례도 확인할 수 있었습니다. 이는 장기간 로그 저장이 필요한 환경에서 상당한 비용 절감 효과를 제공했습니다.
또한 검색 속도 역시 매우 빠르게 동작했습니다. 프로젝트에서는 실제 운영 로그 데이터를 기반으로 검색 성능 테스트를 수행했으며, 기존 Loki 대비 훨씬 안정적인 응답 속도를 확인할 수 있었습니다.
결과적으로 VictoriaLogs와 VictoriaMetrics 조합은 단순 경량화뿐만 아니라 운영 효율성과 저장 비용 절감 측면에서도 매우 효과적인 선택이었습니다.
5. 기존 구성과 경량화 구성 비교
기존 구성과 경량화 구성의 가장 큰 차이는 구조 단순화와 리소스 효율성에 있었습니다.
|
구분 |
기존 구성 |
경량화 구성 |
|---|---|---|
|
로그 에이전트 |
Promtail (DaemonSet) |
Grafana Alloy |
|
메트릭 에이전트 |
node-exporter (DaemonSet) |
Grafana Alloy |
|
에이전트 수 |
2개 DaemonSet |
1개 DaemonSet |
|
에이전트 메모리 (노드당) |
~120 MB (60+60) |
~60 MB |
|
로그 저장소 |
Loki |
VictoriaLogs |
|
메트릭 저장소 |
Prometheus |
VictoriaMetrics |
|
저장소 메모리 (총합) |
~2 GB+ |
~800 MB |
|
설정 파일 |
2개 별도 관리 |
1개 통합 관리 |
* VictoriaMetrics는 Prometheus 대비 메모리를 약 7배 적게 사용하며, VictoriaLogs는 Loki 대비 디스크 사용량을 최대 30배 절감합니다.
기존 구조에서는 다음과 같은 컴포넌트가 각각 독립적으로 동작했습니다.
-
Promtail
-
node-exporter
-
Prometheus
-
Loki
-
Grafana
반면 경량화 구조에서는 다음과 같이 단순화되었습니다.
-
Grafana Alloy
-
VictoriaLogs
-
VictoriaMetrics
-
Grafana
특히 가장 눈에 띄는 변화는 에이전트 수 감소였습니다. 기존에는 로그와 메트릭 수집을 위해 두 개의 DaemonSet이 필요했지만, 경량화 구성에서는 Grafana Alloy 하나만으로 통합할 수 있었습니다.
이로 인해 노드당 메모리 사용량 역시 크게 감소했습니다.
기존 구조에서는 에이전트 메모리 사용량만 약 120MB 수준이었지만, Alloy 기반 구조에서는 약 60MB 수준으로 감소했습니다. 저장소 메모리 사용량 차이는 더욱 컸습니다.
Prometheus와 Loki 조합에서는 전체 메모리 사용량이 약 2GB 이상 발생했지만, Victoria 계열 저장소 기반 구조에서는 약 800MB 수준까지 감소했습니다.
이는 단일 노드 클러스터나 Edge 환경에서는 매우 큰 차이를 만들어냈습니다.
또한 운영 측면에서도 장점이 있었습니다. 기존에는 여러 설정 파일과 버전 관리를 각각 수행해야 했지만, 경량화 구조에서는 관리 포인트가 크게 줄어들었습니다. Grafana는 기존과 동일하게 유지했기 때문에 대시보드와 Alert Rule 역시 대부분 그대로 재사용할 수 있었습니다.
즉, 사용자는 기존 운영 경험을 유지하면서도 내부 Observability 구조만 경량화할 수 있었습니다.
결과적으로 이번 경량화 작업은 단순한 리소스 절감 이상의 의미를 가졌습니다. 한정된 자원 환경에서도 안정적으로 Observability를 유지할 수 있는 지속 가능한 구조를 구축했다는 점에서 매우 의미 있는 프로젝트였습니다.
6. 마치며
Observability는 현대 인프라 환경에서 더 이상 선택이 아닌 필수 요소가 되었습니다. 하지만 모든 환경이 대규모 클라우드 인프라 수준의 리소스를 보유하고 있는 것은 아닙니다.
특히 소규모 Kubernetes 클러스터나 Edge 환경에서는 제한된 CPU와 메모리 안에서 안정적인 운영 구조를 구성해야 합니다.
이번 프로젝트에서는 Grafana Alloy + VictoriaLogs + VictoriaMetrics 조합을 통해 기존 Observability 스택을 훨씬 가볍고 효율적인 구조로 전환할 수 있었습니다.
특히 다음과 같은 장점을 체감할 수 있었습니다.
-
에이전트 구조 단순화
-
메모리 사용량 감소
-
디스크 사용량 절감
-
설정 관리 단순화
-
기존 Grafana 환경 재사용 가능
-
높은 호환성 유지
무엇보다 중요한 점은 기존 Prometheus 및 Loki 생태계와의 호환성을 유지하면서도 운영 비용을 크게 줄일 수 있었다는 점이었습니다.
이는 단순한 비용 절감 이상의 의미를 가집니다. 한정된 자원 안에서 더욱 안정적이고 지속 가능한 운영 환경을 구축할 수 있다는 점에서 전략적인 선택이었습니다. 향후에는 Tracing까지 포함한 전체 OpenTelemetry 기반 구조로 확장하는 것도 충분히 가능할 것으로 기대하고 있습니다.
이번 경험을 통해 Observability는 단순히 많은 데이터를 수집하는 것이 아니라, 운영 환경에 맞는 효율적인 구조를 설계하는 것이 훨씬 중요하다는 점을 다시 한번 확인할 수 있었습니다.
[참고 문헌]
Sean