1. Причины необходимости упрощения наблюдаемости
В современных облачных и основанных на Kubernetes инфраструктурах наблюдаемость становится ключевым элементом системного администрирования.
По мере увеличения масштаба службы способность наблюдать за состоянием системы и быстро анализировать проблемы на основе логов (Log), метрик (Metric) и трассировки (Tracing) становится крайне важной.
Особенно в архитектуре на основе MSA (микросервисной архитектуры) большое количество сервисов работает в распределенном виде, поэтому только на основании журналов приложений трудно определить причины сбоев.
По этой причине комбинация Loki + Promtail + Prometheus + Grafana часто используется в качестве 대표스набжения стека во многих средах.
Эта комбинация имеет очень хорошо разработанную экосистему на основе открытого кода и обладает отличной интеграцией с Kubernetes, поэтому она часто используется как стандартный стек.
Однако на практике в таких традиционных конфигурациях существуют несколько ограничений.
Наибольшей проблемой было использование ресурсов. Promtail и node-exporter работают в виде отдельных DaemonSet, и для каждого узла создается отдельный Pod.
То есть, по мере увеличения числа узлов, также увеличивается количество агентских Pod.
Кроме того, поскольку Prometheus использует память как базу данных временных рядов (TSDB), по мере увеличения объема собираемых метрик объем используемой памяти также быстро растет.
В частности, такая структура значительно нагрузила небольшие кластеры Kubernetes или Edge-окружения.
Например, в таких окружениях предыдущий стек наблюдаемости мог требовать чрезмерных ресурсов.
-
Однопоточный кластер Kubernetes
-
Устройства Edge на базе ARM
-
Промышленные IoT шлюзы
-
Развивающая среда, где оптимизация затрат имеет важное значение
-
Небольшая локальная среда
В проекте приходилось настраивать наблюдаемость в среде с ограниченными ресурсами, и существующая структура стека имела проблему чрезмерного использования ЦП и памяти.
Особенно хранилище метрик и хранилище логов работали отдельно, что увеличивало операционную сложность.
В конечном итоге была необходима структура, которая была бы гораздо легче и эффективнее, при этом максимально совместимой с существующим стеком.
Для решения этой проблемы был рассмотрен легкий состав на основе Grafana Alloy + VictoriaLogs + VictoriaMetrics и применен в реальной рабочей среде.
2. Существующая структура и ограничения стека наблюдаемости
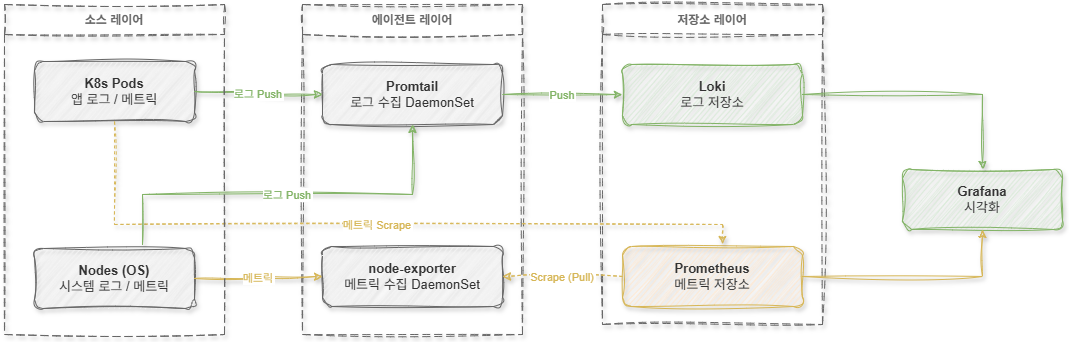
Существующий стек наблюдаемости состоял из структуры Loki + Promtail + Prometheus + Grafana. В этой структуре сбор логов и метрик функционирует независимо друг от друга.
Сначала сбор логов выполняет Promtail. Promtail читает файлы журналов контейнеров на узлах Kubernetes и отправляет их в Loki.
В то время как сбор метрик осуществляется в комбинации node-exporter и Prometheus. Node-exporter экспонирует метрики ОС, такие как состояние CPU, памяти, диска и сети, а Prometheus периодически собирает их по протоколу Pull.
То есть структура сбора логов и метрик была полностью разделена.
[ Схема конструкции (Устаревший стек) ]
Эта структура была достаточно стабильной и проверенной, но в процессе эксплуатации возникло множество проблем.
Первый вопрос касался увеличения числа агентов.
Поскольку Promtail и node-exporter работают как отдельные DaemonSet, на каждом узле запущены как минимум два и более Pod для наблюдаемости.
В окружениях с небольшим количеством узлов доля ресурсов, используемая самим Pod для наблюдаемости, может быть относительно высокой.
Второй проблемой была проблема использования памяти.
Prometheus сохраняет метрики в памяти на основе TSDB.
Таким образом, с увеличением объема собираемых метрик объем используемой памяти также будет увеличиваться почти линейно. Мы также наблюдали, что на практике, когда количество метрик увеличивалось, объем памяти, используемый Prometheus, быстро увеличивался.
Третьим фактором стало увеличение операционной сложности.
Поскольку Promtail, node-exporter и Prometheus имеют разные структуры файлов конфигурации, операторам приходилось одновременно управлять несколькими структурами конфигурации.
Кроме того, необходимо было отдельно управлять обновлениями и совместимостью версий каждого компонента.
Особенно в среде Edge использование дискового пространства хранилища также было важной проблемой. Из-за характеристик индексации и сжатия Loki объем используемого диска мог быстро увеличиваться с увеличением объема логов.
В итоге проект был пересмотрен с целью разработки новой легкой структуры с такими целями.
-
Структура на основе единого агента
-
Минимизация использования памяти
-
Улучшение эффективности сохранения логов
-
Можно повторно использовать существующие дашборды Grafana
-
Сохраняется совместимость с экосистемой Prometheus и Loki
-
Снижение сложности эксплуатации
3. Интегрированная структура сбора на основе Grafana Alloy
Ключевым моментом облегченной конфигурации стала интеграция сборщика данных с Grafana Alloy.
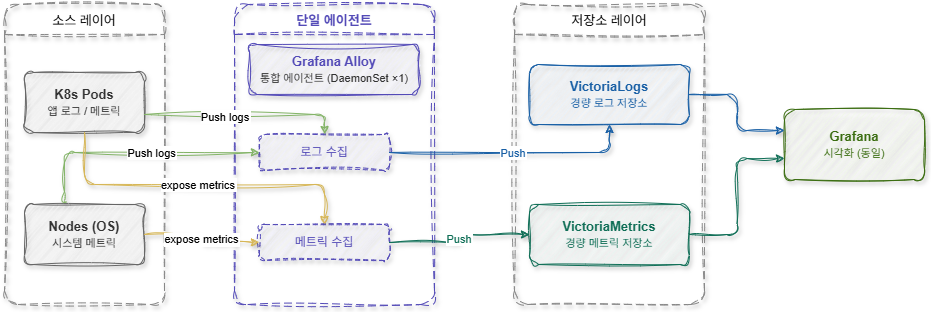
Grafana Alloy – это интегрированный агент наблюдаемости на базе OpenTelemetry, который предоставляет структуру для одновременного сбора логов и метрик. В предыдущей структуре Promtail и node-exporter работали отдельно, но теперь Grafana Alloy может выполнять обе роли самостоятельно.
Таким образом, существующие два DaemonSet были объединены в один. Эта структура обеспечила преимущества, выходящие за рамки простой экономии количества Pod.
Главным преимуществом была эффективность использования ресурсов.
Ранее каждый агент работал как независимый процесс, используя CPU и память, но в структуре на основе Alloy сбор логов и метрик выполняется одновременно в одном процессе. В результате удалось значительно снизить использование памяти агентами на узел.
Кроме того, управление настройками стало гораздо проще. Ранее необходимо было отдельно управлять настройками Promtail и настройками сбора Prometheus, но в Alloy все это можно было управлять из единого файла настроек. Это значительно снизило операционную сложность. В проекте Alloy был развернут в формате DaemonSet в среде Kubernetes.
Alloy настроен для одновременного выполнения следующих ролей.
-
Сбор логов Kubernetes
-
Сбор метрик узла
-
Сбор метрик контейнера
-
Служба обнаружения Kubernetes
-
Логирование меток
-
Метрики разметки
[ Схема конфигурации облегченной системы (Lightweight Stack) ]
Особенно это было большим преимуществом, что структура основана на OpenTelemetry, что позволяет в будущем расшириться до Tracing.
Тем не менее, в этом проекте мы сосредоточились только на облегчении Logging и Metric, исключив Tracing из области применения.
В результате внедрения Grafana Alloy удалось существенно упростить структуру агентов, а также получить эффект повышения операционной надежности.
4. Внедрение VictoriaLogs и VictoriaMetrics
Следующим шагом после интеграции агента сбора данных стало облегчение хранилища.
В проекте существующий Loki и Prometheus были заменены соответственно на VictoriaLogs и VictoriaMetrics. VictoriaMetrics - это совместимая с Prometheus TSDB, отличающаяся очень высокой степенью сжатия и низким использованием памяти.
Особенно есть преимущество в том, что объем используемой памяти значительно меньше по сравнению с Prometheus при одинаковых метриках сбора данных.
На практике в тестовой среде также было подтверждено, что VictoriaMetrics снижает объем используемой памяти примерно в 7 раз по сравнению с традиционным Prometheus.
Также он полностью поддерживает PromQL, поэтому большинство существующих панелей Grafana можно было использовать без изменений.
Это было огромным преимуществом при переходе на рабочую среду. Если бы язык запросов или структура API были совершенно иными, то все существующие панели и настройки оповещений пришлось бы переписывать.
С другой стороны, VictoriaMetrics обеспечивает высокую совместимость с API Prometheus, что значительно снизило нагрузку при миграции. В качестве хранилища логов был использован не Loki, а VictoriaLogs. VictoriaLogs спроектирован как хранилище логов с высокой степенью сжатия и обеспечивает высокую совместимость с API Loki.
Особенно эффект снижения использования дискового пространства был очень заметен. В тестовой среде было зафиксировано снижение использования дискового пространства до 30 раз по сравнению с Loki. Это обеспечило значительную экономию затрат в средах, где требуется длительное хранение логов.
Также скорость поиска работала очень быстро. В проекте были проведены тесты производительности поиска на основе реальных эксплуатационных логов, и было подтверждено, что она значительно стабильнее по сравнению с Loki.
В результате комбинация VictoriaLogs и VictoriaMetrics оказалась очень эффективным выбором не только с точки зрения простой легкости, но и с точки зрения операционной эффективности и снижения затрат на хранение.
5. Сравнение традиционной конфигурации и облегченной конфигурации
Основное отличие между традиционной конфигурацией и облегченной конфигурацией заключалось в упрощении структуры и эффективности использования ресурсов.
|
Разделитель |
Существующая конфигурация |
Упрощенная конфигурация |
|---|---|---|
|
Лог агент |
Промтейл (Демонсет) |
Графана Альянс |
|
Метрик агент |
node-exporter (DaemonSet) |
Графана Сплав |
|
Количество агентов |
2 DaemonSet |
1 DaemonSet |
|
Агент память (на узел) |
~120 МБ (60+60) |
~60 MB |
|
Журнал хранения |
Локи |
ВикторияЛоги |
|
Метрика хранения |
Prometheus |
VictoriaMetrics |
|
Общая память хранилища |
~2 ГБ+ |
~800 МБ |
|
Файл конфигурации |
2 отдельных управления |
1 интегрированное управление |
* VictoriaMetrics использует примерно в 7 раз меньше памяти по сравнению с Prometheus, а VictoriaLogs сокращает использование диска до 30 раз по сравнению с Loki.
В существующей структуре следующие компоненты работали независимо друг от друга.
-
Promtail
-
node-exporter
-
Prometheus
-
Локи
-
Графана
В то же время легкая структура была упрощена следующим образом.
-
Grafana Alloy
-
ВикторияЛоги
-
ВикторияМетрики
-
Графана
Особенно заметным изменением стало сокращение количества агентов. Ранее для сбора логов и метрик требовались два DaemonSet, но в облегченной конфигурации это можно было интегрировать всего с одним Grafana Alloy.
В результате это также значительно снизило использование памяти на узел.
В старой структуре использование памяти агента составляло около 120 МБ, но в структуре на базе Alloy оно снизилось до примерно 60 МБ. Разница в использовании памяти хранилища была еще более значительной.
В сочетании Prometheus и Loki общее использование памяти составило около 2 ГБ, в то время как структура на основе хранилищ Victoria сократилась до примерно 800 МБ.
Это создало огромную разницу в кластерах с одним узлом или в Edge-окружениях.
Кроме того, с точки зрения управления были преимущества. Ранее необходимо было отдельно выполнять управление несколькими файлами настроек и версиями, но в упрощенной структуре количество точек управления значительно сократилось. Grafana осталась прежней, поэтому большинство панелей инструментов и правил уведомлений можно было повторно использовать.
Таким образом, пользователи смогли сохранить свой прежний операционный опыт, при этом упрощая только внутреннюю структуру наблюдаемости.
В конечном итоге, эта работа по оптимизации имела значение, выходящее за рамки простой экономии ресурсов. Это был очень значимый проект, поскольку мы смогли создать устойчивую структуру, позволяющую поддерживать Observability даже в условиях ограниченных ресурсов.
6. Заключение
Наблюдаемость стала необходимым элементом в современных инфраструктах, а не выбором. Однако не все среды обладают ресурсами на уровне крупномасштабной облачной инфраструктуры.
Особенно в малых кластерах Kubernetes или на Edge-окружениях необходимо строить надежную операционную структуру в условиях ограниченного ЦП и памяти.
В этом проекте мы смогли преобразовать существующий стек наблюдаемости в гораздо более легкую и эффективную структуру с помощью комбинации Grafana Alloy + VictoriaLogs + VictoriaMetrics.
Особенно можно было ощутить следующие преимущества.
-
Упрощение структуры агента
-
Снижение потребления памяти
-
Снижение использования диска
-
Упрощение управления настройками
-
Возможность повторного использования существующей среды Grafana
-
Сохранение высокой совместимости
Самым важным моментом было то, что нам удалось значительно снизить операционные расходы, сохранив при этом совместимость с существующей экосистемой Prometheus и Loki.
Это означает не просто снижение затрат. Это было стратегическим выбором, потому что мы можем создать более стабильную и устойчивую операционную среду с ограниченными ресурсами. В будущем мы также ожидаем, что будет возможно расширить это до полной структуры на основе OpenTelemetry, включая трассировку.
Эта практика еще раз подтвердила, что наблюдаемость заключается не просто в сборе большого объема данных, но в проектировании эффективной структуры, соответствующей операционной среде.
[Список литературы]
Шон