Архитектура на основе событий для автоматического перевода LLM
Обработка автоматического перевода LLM как асинхронного потока событий
1. Введение
Во время разработки функции автоматического перевода многозначных строк я понял, что есть более важные проблемы, чем просто вызов LLM для получения перевода. Это вопрос о том, как обрабатывать вызовы LLM в рамках существующей потока запросов услуг. Обработка на основе LLM имеет непостоянное время ответа, в отличие от общего внутреннего логики, и зависит от состояния внешней модели или сетевой ситуации. Поэтому, если обрабатывать вызовы LLM внутри API хранения, время ответа на запросы пользователя становится трудно предсказуемым.
Сначала я также думал о том, чтобы объединить сохранение и перевод в один поток. Если посмотреть на реализацию, структура кажется простой: после получения запроса на сохранение сохраняется оригинальный текст, затем вызывается LLM для получения переводов и возвращения ответа. Однако такой подход сильно связывает ответственность функции сохранения и ответственность функции перевода. Сохранение - это задача, которая может быть выполнена быстро, но если перевод затягивается, то задерживается и ответ на сохранение. Кроме того, неясно, как в одном запросе отобразить случай, когда сохранение прошло успешно, а перевод потерпел неудачу.
Поэтому в этой работе мы выбрали направление отделения вызова LLM от потока пользовательских запросов и обработки его с использованием событийной асинхронной обработки. Ключевым моментом было не просто добавить перевод как простую дополнительную функцию, а разобраться, как отделить потенциально задерживающие внешние операции от потока изменения внутреннего состояния сервиса.
2. Почему вызов LLM был отделен от потока запросов
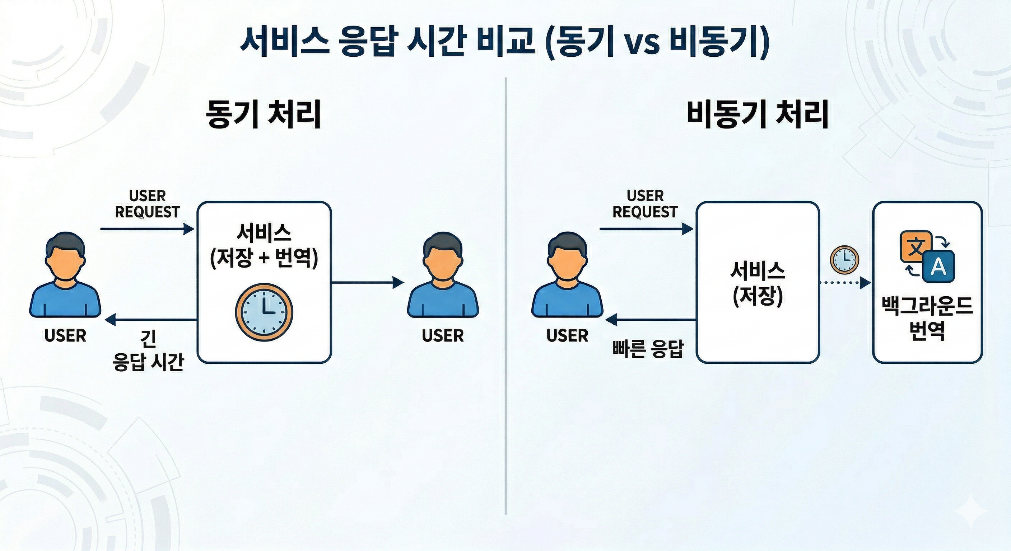
Вызов LLM отличается от обычной бизнес-логики. Внутренняя проверка данных или сохранение в базе данных завершаются в относительно предсказуемые сроки, но время ответа при вызове LLM зависит от нагрузки на модель, состояния сети, длины запроса и количества целевых языков. Если такое обработка включить в синхронный запрос, пользователю придется ждать ответа из-за операций, не связанных с сохранением.
Кроме того, с точки зрения распространения сбоев есть проблемы. Если API сохранения напрямую зависит от вызова LLM, сбой LLM может показаться сбоем функции сохранения. Пользователь всего лишь пытался сохранить данные, но из-за неудачного вызова внешней модели запрос на сохранение может показаться полностью провалившимся. На самом деле сохранение и перевод - это задачи с разными ответственностями, но в синхронной структуре границы между этими ответственностями размыты.
Асинхронная структура смягчает эту проблему. Запросы на сохранение выполняют только свои обязательства по сохранению и быстро отвечают. Затем ситуации, требующие перевода, выражаются в виде событий, а обработка перевода выполняется в отдельном потоке. Этот подход ближе к конечной согласованности, чем к мгновенной. Хотя все значения перевода не могут быть готовы сразу после сохранения, отклик на запросы пользователей и изоляция сбоев системы становятся лучше.
[Рисунок 1. Сравнение времени ответа сервиса: синхронная и асинхронная обработка]
Выбор этой структуры обусловлен не только тем, что она «быстро отвечает». Гораздо важнее то, что она позволяет четко отделить задачи, которые могут занять длительное время, и обрабатывать их успехи и неудачи через отдельные потоки событий.
3. Сохранение контрактов событий компактнымиПервым делом, что нужно было упорядочить в асинхронной структуре, это был контракт событий. Событие - это не просто объект, передающий данные, а обещание между различными потоками обработки. Поскольку сторона, публикующая запрос, и сторона, обрабатывающая запрос, находятся не в одном и том же стеке вызовов, то в зависимости от того, какую информацию мы включим в событие, изменяется степень связи всей структуры.
Сначала казалось безопасным включить как можно больше информации в событие. Однако по мере увеличения размера полезной нагрузки события обязанности на этапе запроса и обработку начали смешиваться. Событие запроса должно сосредоточиться на минимальной информации, необходимой для выполнения перевода, а событие завершения — на информации, необходимой для отражения результата. Поэтому мы разделили роли события запроса и события завершения.
В событии запроса содержится информация о том, для какого сервиса и какой сущности, какие поля требуют перевода, а также информация о базовом языке и многоязычной строке, необходимость принудительного повторного перевода. В свою очередь, событие завершения было упрощено и теперь содержит только идентификационную информацию и переведенные LangStrings, необходимые для отражения результатов перевода. Таким образом, событие запроса фокусируется на «что переводить», а событие завершения — на «какой результат отражать».
Сохранение контракта мероприятия в узком формате также выгодно в случае изменений. Даже если внутренняя реализация перевода изменится с Mock на реальный LLM, значение запрашиваемого события может быть сохранено. Если способ генерации результатов перевода изменится, но контракт результатов, который выражает событие завершения, останется неизменным, это позволит сократить объем изменений с той стороны, которая отражает результаты.
4. Обращаться не ко всей базе данных, а к патчу
Выражение результатов перевода также было важным решением. Один из способов – вернуть всю мультиязычную строку после завершения перевода. Однако этот подход может размыть границы между исходными данными и результатами перевода. Особенно это может произойти, если уже есть введенные вручную значения; в таком случае повторное отражение всех данных может привести к непреднамеренному перезаписыванию.
Поэтому результаты перевода были решено воспринимать не как полные данные, а как набор значений, которые необходимо дополнить, то есть ближе к патчу. Мы решили, что целевыми для перевода должны быть только пустые языковые значения, в то время как языки с уже имеющимися значениями были исключены по умолчанию. Если необходимо повторно сгенерировать существующий перевод, это можно сделать с помощью отдельного параметра forceUpdate, который позволяет явно инициировать повторный перевод.
Эта политика была скорее защитой данных, чем простыми бизнес-условиями. Автоматический перевод удобен, но если перекрыть тщательно проработанные формулировки машинным переводом, качество может снизиться. Поэтому было безопаснее интерпретировать результаты автоматического перевода как 'данные, дополняющие текущие недостающие значения', а не как 'данные, которые всегда полностью заменяют предыдущие'.
С этой точки зрения подход patch хорошо сочетался с обработкой на основе событий. Запрос события рассчитывает целевой перевод на основе исходного состояния, а событие завершения передает только те результаты, которые можно применить. Тот, кто применяет результаты, может не переосмыслять все состояние, а просто применить полученный перевод в необходимых местах.
5. Ответ LLM не является проверяемыми данными
Настоящая мысль, которую я почувствовал, подключая реальный LLM, заключается в том, что нельзя полностью доверять ответам LLM. Хотя LLM силен в генерации естественного языка, он не всегда точно соблюдает формат, который требуется сервисным данным. Хотя сам перевод может выглядеть естественно, с точки зрения структуры данных это может быть сломанный ответ.
Например, если есть предложение «Здравствуйте, {{name}}», то {{name}} не подлежит переводу. Это место для имени пользователя, поэтому в результате перевода оно также должно остаться неизменным. То же самое касается URL, электронной почты, HTML-тегов и токенов формата. Если такие значения исчезнут или изменятся, это не будет проблемой качества перевода, а будет ошибкой в данных сервиса.
Разделение строк также было важным объектом проверки. Строки меток, отображаемые на экране, могут включать не только простые однострочные предложения, но и многострочные инструкции. Если в исходном тексте использование переносов строк разделяет смысловые единицы, и они исчезают в переводе, это может повлиять на компоновку экрана или контекст. Поэтому мы сравнивали количество переносов строк в исходном и переводном текстах, и если они различались, это рассматривалось как нарушенный ответ.
Языковые письменные системы нужно рассматривать отдельно. Например, узбекский язык требует учета как латинских, так и кириллических букв. Если просто перевести на узбекский, это может привести к результату, отличающемуся от желаемой письменной системы. Поэтому я преобразовал языковые коды с учетом письменной системы, такие как uz-Latn, uz-Cyrl, в promptLabel и также проверил, соответствует ли указанная письменная система в ответе.
Этот процесс показал мне, что важным в функции LLM является не только хороший промпт. Промпт направляет к желаемому результату, но код сервиса должен проверять, соответствует ли этот результат действующим правилам данных. Ответ LLM не является сразу же надежными данными, а ближе к кандидатным данным, которые могут быть использованы только после прохождения проверки.
6. Классификация ошибок и разделение критериев повторной попытки
В асинхронной структуре также важно, как обрабатывать ошибки. В синхронном API ошибки могут быть переданы в виде HTTP-ответа, но в событийной обработке моменты запроса и обработки отделены друг от друга. Следовательно, ошибки также должны быть представлены в рамках событийного потока.
Если затрагивать все сбои одинаковым образом, управление станет сложным. Временные внешние сбои, такие как проблемы с сетью или таймауты LLM, можно решить повторными попытками. Напротив, случаи, когда отсутствует эталонный язык, или оригинал пуст, или ответ LLM не проходит структурную проверку, трудно исправить простыми повторными попытками. Поэтому мы разделили сбои на ошибки, которые можно повторить (retryable), и ошибки, которые нельзя повторить (non-retryable).
Сбои запросов LLM или таймауты были расценены как ошибки, которые можно повторить, и переданы обратно в систему обработки сообщений для повторных попыток. В отличие от этого, в случаях, когда отсутствуют обязательные значения, оригинал отсутствует или имеется ошибка формата ответа, мы публиковали их как события сбоев. Такое разделение позволяет по-разному справляться с временными внешними сбоями и проблемами с контрактом данных.
Оставляя события неудачи, последующая обработка тоже становится более ясной. Неудачные сущности и поля, коды ошибок и возможность повторной попытки могут быть зафиксированы как события, которые затем могут быть использованы в операционных инструментах или отдельных коррекционных потоках. В асинхронной структуре, вместо того чтобы оставлять неудачи только в виде простых логов, мне показалось более надежным выражать их в виде событий, понятных системе.
7. От проверки макета до проверки Live LLM
На начальном этапе мы сначала проверили поток событий на основе Mock, а не подключили фактическую LLM. Если сразу подключить реальную модель, то трудно сразу определить, является ли проблема в контракте события, парсинге ответа или вызове модели. Поэтому сначала мы проверили, передаются ли запросы событий в поток обработки, публикуются ли события завершения, и работает ли расчет объекта перевода так, как задумано.
Затем мы подключили реальную LLM и проверили качество перевода и логику проверки ответов. При этом мы не просто смотрели, чтобы результат перевода не был пустым. Мы проверили, сохраняются ли плейсхолдеры, сохраняется ли перенос строк, соответствует ли система символов, используется ли defaultLangCode как язык по умолчанию, если базовый язык опущен, и влияет ли forceUpdate на повторный перевод существующего значения.
В ходе этого тестового процесса мы ещё раз убедились, что «LLM ответил» и «можно безопасно отразить в сервисных данных» — это две разные проблемы. Тестирование интеграции LLM должно проверять не только успешность вызова модели, но и то, соответствует ли результат требованиям данных, предъявляемым системой.
8. Завершение
В ходе этой работы я понял, что важно не только код для вызова модели, когда мы прикрепляем функции LLM к сервису. Необходимо отделить задачи с длительным временем отклика от рабочего процесса, поддерживать контракт событий на небольшом уровне, преобразовывать ответы LLM в проверяемые данные и разделять сбои на те, которые можно повторить, и те, которые нельзя.
В конечном счете, суть автоматизированного перевода LLM заключается не в том, чтобы «заставить LLM выполнять перевод», а в создании структуры, которая безопасно обрабатывает результаты LLM в потоке данных сервиса. Эта концепция заключалась в разделении вызовов LLM на асинхронные потоки на основе событий, а также в попытке обработать недетерминированные ответы в контексте валидации, обработки сбоев и наблюдаемости.
джюю
[参考文献]
Microsoft Learn, асинхронный паттерн запроса-ответа
https://learn.microsoft.com/ko-kr/azure/architecture/patterns/asynchronous-request-reply
IBM, что такое архитектура, основанная на событиях?
https://www.ibm.com/kr-ko/think/topics/event-driven-architecture
Технический блог KakaoPay, использование событийно-ориентированной архитектуры в нужное время и в нужном месте
https://tech.kakaopay.com/post/event-driven-architecture/