
1. 문제 인식
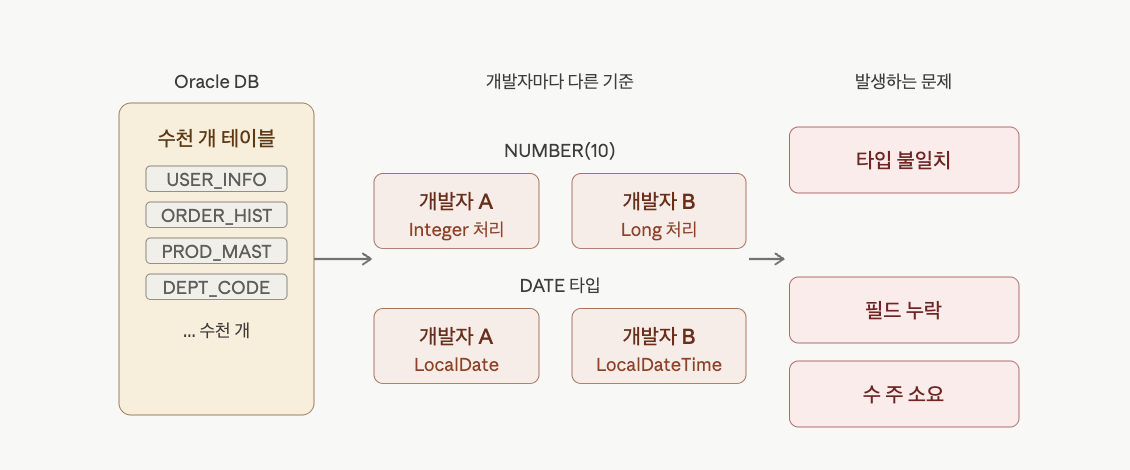
현대화 프로젝트를 진행하던 중, 기존 시스템에서는 MyBatis를 사용하고 있었기 때문에 별도의 Entity 명세가 존재하지 않는 상황이었습니다. 신규 프로젝트에서는 JPA 기반으로 전환하면서 Data Warehouse 테이블 정의서를 참고하여 Entity 모델을 직접 생성해야 했는데, 테이블 수가 수천 개에 달했습니다.
이 과정에서 두 가지 핵심 문제가 발생했습니다. 첫째, Oracle 데이터 타입을 Java 타입으로 변환하는 기준이 개발자마다 달라 코드 일관성이 무너졌습니다. 예를 들어 Number(10)을 Integer로 처리할지 Long으로 처리할지, Date 타입을 LocalDate로 받을지 LocalDateTime으로 받을지에 대한 합의가 없었습니다.
둘째, 수작업으로 수천 개의 Entity를 생성하다 보니 필드 누락이나 타입 불일치 같은 단순 오류가 빈번하게 발생했고, 이를 코드 리뷰 단계에서 다시 확인해야 하는 이중 소모가 발생했습니다.
단순 반복 작업만으로 몇 주 이상의 시간이 소요될 것으로 예측되었고, 이는 팀 전체의 생산성을 저해하는 명확한 병목 요인이었습니다.
2. 해결 방안: Entity 자동 생성 도구 개발
2-1. JavaParser란?
JavaParser는 Java 소스 코드를 파싱하고, 분석하거나 수정 및 생성할 수 있는 오픈소스 라이브러리입니다. 내부적으로 Java 코드를 추상 구문 트리(AST, Abstract Syntax Tree) 형태로 변환하여, 마치 JSON이나 XML을 다루듯 Java 코드를 구조적으로 생성·조작할 수 있게 해줍니다.
이 라이브러리의 핵심 객체인 CompilationUnit을 활용하면 Import 구문, 클래스 애너테이션, 필드 정의, 생성자, 주석 등을 코드로 자유롭게 구성할 수 있습니다.
다른 접근법과의 비교
도구를 선택하기에 앞서 몇 가지 대안도 검토했습니다. 단순 문자열 템플릿(StringTemplate, Freemarker 등)을 활용하는 방법은 구현이 빠르지만, 생성된 코드의 구문 유효성을 보장하기 어렵고 import 중복 제거나 들여쓰기 정규화 같은 후처리를 별도로 구현해야 한다는 단점이 있었습니다.
반면 JavaParser는 AST 수준에서 코드를 조작하기 때문에 구문 오류가 원천적으로 발생하지 않으며, LexicalPreservingPrinter를 통해 일관된 포맷의 소스를 출력할 수 있었습니다. 수천 개의 파일을 자동 생성해야 하는 상황에서 코드 품질의 일관성이 핵심 요건이었기 때문에 JavaParser를 선택했습니다.
2-2. 도구 설계 및 구현
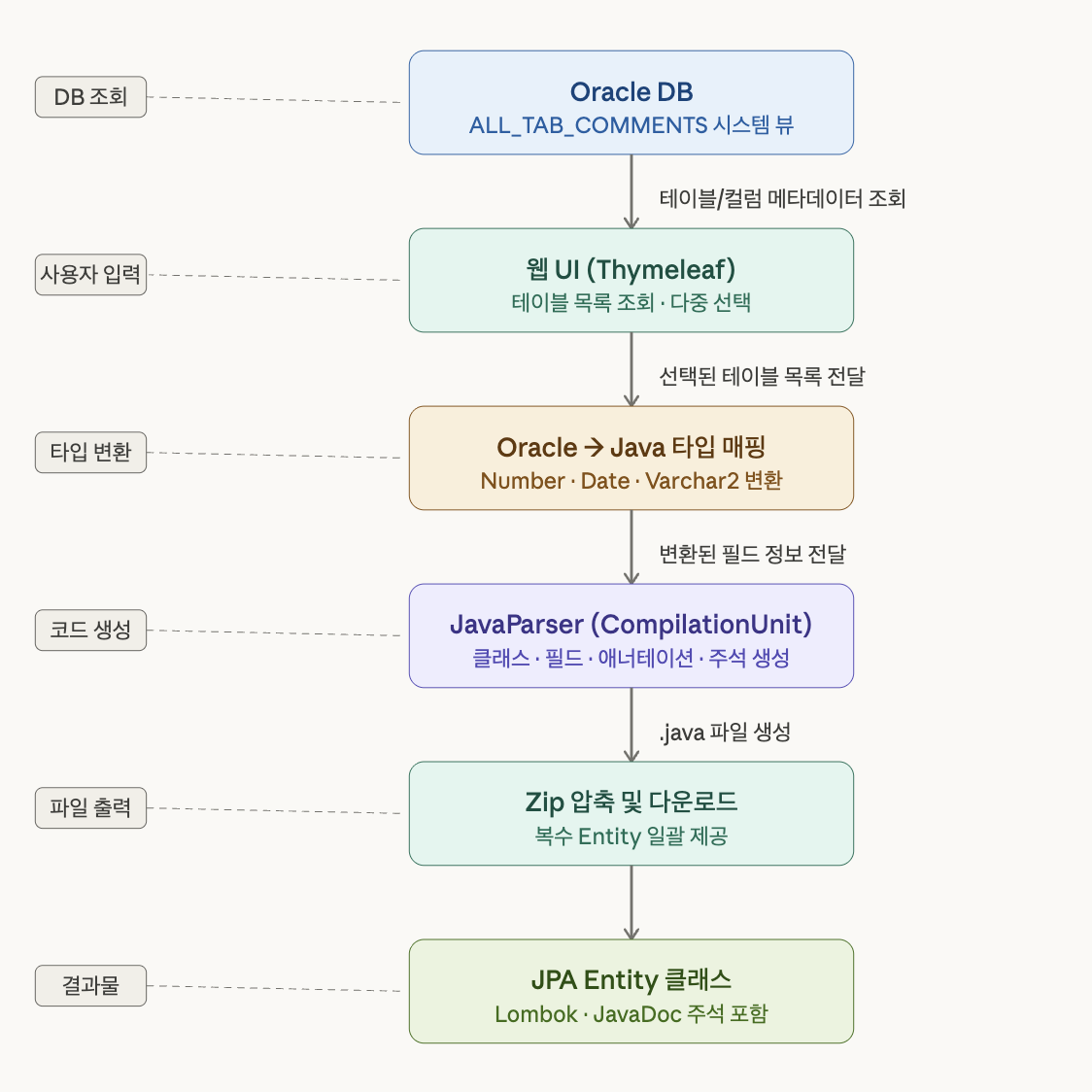
Oracle DB에 직접 커넥션하여 ALL_TAB_COMMENTS 시스템 뷰를 통해 테이블 및 컬럼 정보(이름, 타입, 주석)를 조회하고, 이를 JavaParser의 CompilationUnit으로 전달하여 Entity 클래스를 자동 생성하는 프로그램을 개발했습니다.
주요 기능은 다음과 같습니다.
- Oracle 타입 → Java 타입 자동 변환(Number(10) → Long, Date → LocalDateTime 등 팀 합의 기준 적용)
- 컬럼별 주석을 JavaDoc 형식으로 자동 삽입
- @Getter, @Setter, @NoArgsConstructor 등 Lombok 애너테이션 자동 적용
- LocalDateTime 등 특정 타입 사용 시 import 구문 자동 추가
- Thymeleaf 기반 웹 UI에서 테이블 목록 조회 및 선택, zip 파일로 일괄 다운로드
핵심 구현: 타입 매핑과 CompilationUnit 구성
도구의 핵심은 Oracle 타입 → Java 타입 변환 로직입니다. 팀 내 사전 합의를 통해 아래 기준을 확정하고, 이를 코드에 내재화했습니다.
변환된 타입 정보를 바탕으로 CompilationUnit을 구성하는 과정은 다음과 같은 흐름으로 동작합니다. 먼저 CompilationUnit 인스턴스를 생성한 뒤 패키지 선언을 추가합니다. 이후 필드에서 사용된 타입을 분석하여 필요한 import만 선별적으로 삽입합니다.
클래스 선언에는 @Entity, @Table, @Getter, @NoArgsConstructor 같은 애너테이션을 추가하고, 각 컬럼은 FieldDeclaration으로 변환하여 @Column 애너테이션과 JavaDoc 주석을 함께 붙여 클래스에 삽입합니다.
마지막으로 LexicalPreservingPrinter로 최종 소스 문자열을 출력합니다. 이 일련의 과정이 모두 AST 조작으로 이루어지기 때문에 결과물은 항상 구문적으로 유효한 Java 파일로 보장됩니다.
3. 적용 결과
도구 도입 이후 Entity 생성에 소요되던 시간을 95% 이상 단축하는 효과를 체감했습니다. 팀에서 사전 합의한 타입 매핑 기준이 도구에 반영되어 있어, 개발자에 따라 달라지던 매핑 편차가 사라졌습니다. 필드 누락이나 타입 불일치로 인한 코드 리뷰 부담도 크게 줄었습니다.
무엇보다 눈에 띄었던 효과는 온보딩 비용의 감소였습니다. 신규 투입된 팀원도 타입 변환 기준을 별도로 숙지할 필요 없이 도구를 통해 일관된 산출물을 바로 생성할 수 있었고, 시니어 개발자가 반복적인 리뷰에 쏟던 시간을 아키텍처 검토나 비즈니스 로직 설계에 재배분할 수 있었습니다.
결과적으로 전체 개발 일정이 단축되었고, 팀원들이 단순 반복 작업 대신 가치 있는 문제에 집중할 수 있는 환경이 마련되었습니다.
4. 마치며
이번 경험을 통해 개발자의 역할이 단순히 코드를 작성하는 것을 넘어, 팀의 생산성을 저해하는 문제를 발굴하고 개선하는 것도 중요한 역량임을 다시 한번 느꼈습니다. 반복적이고 오류가 발생하기 쉬운 작업을 자동화함으로써 팀 전체가 더 가치 있는 일에 집중할 수 있었습니다.
또한 자동화 도구를 만드는 과정 자체가 팀의 암묵적 지식을 명시적 규칙으로 전환하는 작업이기도 했습니다. 타입 매핑 기준을 코드에 녹이기 위해서는 먼저 팀 내 합의가 선행되어야 했고, 이 과정에서 그동안 흐릿하게 공유되던 컨벤션이 문서화되는 부수적인 효과도 있었습니다.
좋은 자동화는 단순히 속도를 높이는 것이 아니라, 팀의 기준을 코드로 표현한다는 점에서 그 가치가 있다고 생각합니다.
참고문헌: https://javaparser.org