Архитектура событийной автоматизированной перевода LLM
Автоматический перевод LLMОбработка с помощью асинхронного потока событий
1. Введение
НедавноПри проектировании функции автоматического перевода многоязычных строк я понял, что есть более важная проблема, чем просто вызов LLM и получение результатов перевода. Это то, как обрабатывать вызовы LLM в рамках существующего потока запросов службы. Обработка на основе LLM отличается от общей внутренней логики тем, что время ответа непостоянно и зависит от состояния внешней модели или сетевой ситуации. Поэтому, если выполнять вызовы LLM вместе с обработкой API хранения, время ответа на запросы пользователей становится трудно предсказуемым.
СначалаЯ также подумал о способе объединить сохранение и перевод в один поток. Если посмотреть на реализацию, структура выглядит простой: после получения запроса на сохранение оригинал сохраняется, затем сразу вызывается LLM для получения результатов перевода, и после этого отправляется ответ. Однако этот метод сильно связывает ответственность функции сохранения и функции перевода. Сохранение — это задача, которую можно быстро завершить, но если перевод задерживается, ответ на сохранение тоже задерживается. Кроме того, неясно, как выразить в одном запросе случай, когда сохранение прошло успешно, а перевод не удался.здесь.
ПоэтомуВ этой работе мы выбрали направление разделения вызова LLM от потока пользовательских запросов и обработки его на основе событий в асинхронном режиме. Ключевым моментом было не просто прикрепить перевод как простую дополнительную функцию, а как будет происходить разделение внешней операции с возможной задержкой от изменения внутреннего состояния сервиса.
2. Почему LLM вызов был отделен от потока запроса
Вызов LLM отличается от обычной бизнес-логики. Внутренняя проверка данных или сохранение в БД завершается в относительно предсказуемые сроки, в то время как время ответа LLM-вызова зависит от нагрузки на модель, состояния сети, длины промпта и количества целевых языков. Если такую обработку включить в синхронный запрос, пользователю придется ждать ответа из-за задач, не связанных с сохранением.
ТакжеС точки зрения распространения сбоев также есть проблемы. Если API хранения непосредственно зависит от вызовов LLM, сбой LLM может выглядеть как сбой функции хранения. Пользователь всего лишь пытался сохранить данные, но из-за неудачи вызова внешней модели он может столкнуться с тем, что весь запрос на сохранение провалился. На самом деле сохранение и перевод — это задачи с разными ответственностями, но в синхронной структуре границы между этими двумя обязанностями размыты.
Асинхронный Структура смягчает эту проблему. Запросы на сохранение выполняют только ответственность за сохранение и быстро отвечают. После этого ситуация, требующая перевода, выражается как событие, а обработка перевода осуществляется в отдельном потоке. Этот подход ближе к конечной согласованности, чем к немедленной согласованности. Все значения перевода могут не быть готовы сразу после сохранения, но отзывчивость пользовательского запроса и изоляция сбоев системы становятся лучше.
[Рисунок 1. Сравнение времени отклика сервиса: синхронная и асинхронная обработка] 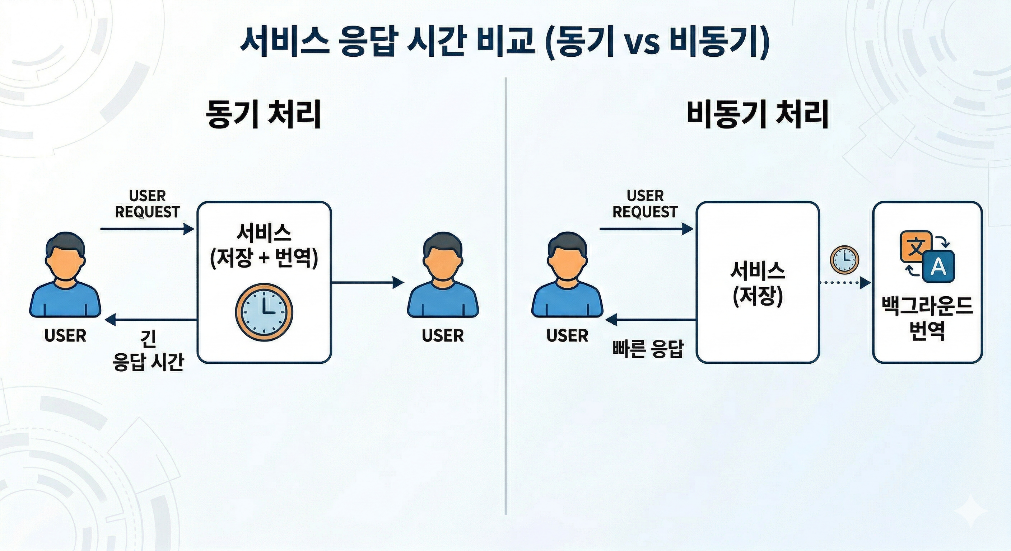
При выборе этой структуры важно было не только то, что она «быстро отвечает». Более важно то, что можно четко отделить задачи, которые могут занять много времени, и обработать успех и неудачу этих задач в отдельном потоке событий.
3. Сохраните контракт на мероприятие небольшимАсинхронныйПервым делом, что нужно было уяснить в структуре, был контракт событий. Событие - это не просто объект, передающий данные, а обещание между различными потоками обработки. Поскольку сторона, инициирующая запрос, и сторона, обрабатывающая его, не находятся в одном и том же стеке вызовов, связывание всей структуры зависит от того, какую информацию мы решим включить в событие.
СначалаКажется безопасным содержать как можно больше информации в событии. Однако, по мере увеличения размера полезной нагрузки события, ответственность на этапе запроса и обработки начала смешиваться. Событие запроса должно сосредоточиться на минимальной информации, необходимой для выполнения перевода, в то время как событие завершения должно сосредоточиться на информации, необходимой для отражения результата. Поэтому мы разделили роли событий запроса и завершения.
ЗапросСобытие запроса содержит информацию о том, какой сервис, какая сущность и какие поля нуждаются в переводе, а также информацию о языках-эталонах и многоязычных строках, а также информацию о необходимости принудительного повторного перевода. В свою очередь, событие завершения должно содержать только идентификационную информацию и переведенные LangStrings, необходимые для отражения результатов перевода. Разделяя эти события, событие запроса сосредотачивается на "что переводить", а событие завершения - на "какой результат учитывать".
СобытиеУдерживание контракта в небольшом объеме также будет выгодно в случае изменений. Внутренняя реализация перевода MДаже если в Mock произойдет переход к реальному LLM, смысл событий запроса может быть сохранен. Если способ генерации переводов изменится, но соглашение о результате, выражаемом событием завершения, останется, можно сократить объем изменений на стороне отражения результата.
4. Не вся данные, а только те, которые относится к патчу
ПереводТакже важно было, как представить результаты. Один из способов - это полный многоязычныйЭто возвращение строки. Однако такой способ может размыть границы между оригинальными данными и результатами перевода. Особенно если есть уже введенные человеком значения, полное обновление данных может привести к непреднамеренному перезаписыванию.
ПоэтомуРезультат перевода является набором значений, которые необходимо дополнить, а именнопатч(патч)Я посчитал более подходящим направление, которое ближе всего к решению. Я выбрал только пустые языковые значения для перевода, и уже имеющие значения языков изначально исключил. Если необходимо заново создать существующий перевод, я добавил отдельный параметр forceUpdate для явного повторного перевода.
ЭтоПолитика больше походила на защиту изменений данных, чем на простые бизнес-условия. Автоматический перевод удобен, но если ручные формулировки заменяются результатами машинного перевода, это может привести к снижению качества. Поэтому было безопаснее интерпретировать результаты автоматического перевода как "данные, которые дополняют текущие недостаточные значения", а не как "данные, которые всегда полностью заменяют".
иС точки зрения патч-метода, он хорошо сочетался с обработкой на основе событий. Запрос события рассчитывает целевой объект перевода на основе исходного состояния, а событие завершения передает только результаты, которые можно применить. Та сторона, которая применяет результаты, может не интерпретировать все состояние заново, а просто использовать полученные результаты перевода в необходимых местах.
5. LLM ответ не является проверяемыми данными
реальноОсновное, что я ощутил, подключая LLM, это то, что на ответы LLM полагаться нельзя. LLM сильна в генерации естественного языка, но не всегда точно соблюдает формат, требуемый данными сервиса. Хотя перевод может выглядеть естественно, с точки зрения структуры данных он может быть нарушен.
примерКогда есть предложение "Здравствуйте, {{name}}", {{name}} не подлежит переводу. Это место для имени пользователя, поэтому оно должно оставаться без изменений в переводе. То же самое касается URL, электронной почты, HTML-тегов и форматированных токенов. Если такие значения исчезнут или изменятся, это не будет проблемой качества перевода, а ошибка данных сервиса.
Перенос строки тожеЭто был важный объект проверки. Строки меток, отображаемые на экране, могут содержать не только простые однострочные предложения, но и многослойные инструкции. В оригинальном тексте смысловые единицы разделены переносами строк, и если переносы строк исчезнут в переводе, это может изменить структуру экрана или контекст. Поэтому я сравнил количество переносов строк в оригинале и переводе, и если оно отличается, я рассматриваю это как нарушенный ответ.
языковыеСистема письменности также должна рассматриваться отдельно. Например, при переводе узбекского языка необходимо учитывать как латинские, так и кириллические буквы. Простое указание на перевод на узбекский может привести к результатам, отличным от желаемой системы письма. Поэтому языковые коды, включающие систему письма, такие как uz-Latn, uz-Cyrl.promptLЯ преобразовал в abel и также проверил, соответствует ли данная система письма в ответе.
ЭтоЯ понял, что в функции LLM важна не только хорошая подсказка, но и то, что подсказка должна вызывать желаемый результат, а код сервиса должен проверять, соответствует ли этот результат реальным правилам данных. Ответы LLM не являются сразу надежными данными, это скорее кандидатные данные, которые могут быть приняты только после прохождения проверки.
6. Неудача разделить критерии для классификации и повторной попытки
Асинхронный В структуре также важно было, как обрабатывать сбои. Если это синхронный API, то сбой можно передать в HTTP-ответе, но в обработке на основе событий время запроса и время обработки разделены. Поэтому сбои также должны быть выражены в потоке событий.
Все Если к неудачам относиться одинаково, это усложнит управление. Проблемы с сетью или LLM Тайм-аутВременные внешние сбои могут быть успешно решены при повторной попытке. В то же время, если отсутствует эталонный язык, или оригинальный текст пуст, или ответ LLM не проходит структурную валидацию, простое повторное действие вряд ли поможет. Поэтому неудача повторной попытки ошибочный)Ошибка иошибка, которую невозможно повторить(неповторяемый)Мы разделили на ошибки.
Ошибки, такие как сбой запроса LLM или тайм-аут, рассматриваются как повторяемые ошибки и снова отправляются в систему обработки сообщений, чтобы использовать ее поток повторных попыток. Напротив, в случаях, когда отсутствуют обязательные значения, отсутствует исходный текст или есть ошибки в формате ответа, это расценивается как событие неудачи. Таким образом, мы можем по-разному справляться с временными внешними сбоями и проблемами с данными.
ОшибкаОставив событие, последующая обработка станет более ясной. Можно оставить событие о неудавшейся сущности и поле, код ошибки, возможность повторной попытки, и позже использовать это в инструментах эксплуатации или в отдельном процессе коррекции. В асинхронной структуре, я почувствовал, что лучше выражать неудачи в виде событий, которые понимает система, вместо того, чтобы просто оставлять их в журналах.
7. Проверка Mock до проверки Live LLM
Начальном этапе лучше не подключать реальную LLM напрямую Mock основан на предварительной проверке потока событий. Если сразу подключить реальную модель, трудно сразу определить, является ли причиной проблемы с контрактом событий, проблемой анализа ответа или проблемой вызова модели. Поэтому сначала M Мы проверили, передаются ли события запроса через Mock в поток обработки, публикуется ли событие завершения и работает ли расчет целевого перевода, как предполагается.
Затем Мы фактически подключили LLM, чтобы проверить качество перевода и логику проверки ответов. При этом мы не просто проверяли, что результат перевода не пустой. Мы также проверяли, сохраняется ли плейсхолдер, сохраняется ли перенос строк, соответствует ли система символов, используется ли defaultLangCode в качестве языка по умолчанию, когда baseLangCode опущен, и влияет ли forceUpdate на повторный перевод существующих значений.
Это В ходе этого тестового процесса мы вновь подтвердили, что «LLM ответил» и «можно безопасно отразить в данных обслуживания» — это разные проблемы. Тестирование интеграции LLM должно было проверить не только успешность вызова модели, но и соответствие результатов требуемому договору по данным системы.
8. Завершение
На этот раз Я понял, что важно не только само код для вызова модели, когда подключаешь функции LLM к сервису. Необходимо отделить задачи с длительными задержками от потока запросов, сохранить события маленькими, преобразовать ответы LLM в проверяемые данные и разделить сбои на те, которые можно повторить, и те, которые нельзя.
В конце концов Ключевой момент автоматического перевода LLM заключается не в том, чтобы «заставить LLM переводить», а в создании структуры, обеспечивающей безопасное обращение с результатами LLM в потоке сервисных данных. Этот проект направлен на разделение вызова LLM на асинхронный поток на основе событий, а также на обработку недетерминированных ответов с точки зрения проверки, обработки ошибок и наблюдаемости.
jyyou
[참ко문헌]
Microsoft Learn, Асинхронный паттерн запрос-ответ
https://learn.microsoft.com/ko-ru/azure/architecture/patterns/asynchronous-request-reply
IBM, Что такое событийная архитектура?
https://www.ibm.com/kr-ko/think/topics/event-driven-architecture
Блог технологий KakaoPay, Использование событийного подхода в нужных местах
https://tech.kakaopay.com/post/event-driven-architecture/