Event-driven architecture for LLM automatic translation
LLM automatic translationHandling with asynchronous event flow
1. Introduction
RecentlyWhile designing the automatic multilingual string translation feature, I realized that there is a more important issue than simply calling the LLM to obtain translation results. It was how to handle the LLM calls within the existing service request flow. LLM-based processing has an unpredictable response time, unlike typical internal logic, and is influenced by external model states and network conditions. Therefore, processing LLM calls alongside in the storage API makes it difficult to predict the response time of user requests.
At first,I also thought about a method that combines storage and translation into a single flow. From the implementation perspective, it seemed simple to save the original text after receiving a storage request, then immediately call the LLM to generate the translation result and respond. However, this approach tightly couples the responsibilities of the storage function and the translation function. Storage is a task that can be completed quickly, but if the translation is delayed, the response for storage is also delayed. Additionally, it is ambiguous how to represent a case where storage succeeds but translation fails within a single request.It will be.
SoIn this task, we chose to separate LLM calls from the user request flow and handle them with event-driven asynchronous processing. The key was not to attach translation as a simple additional feature, but to consider how to separate potentially delayed external operations from the internal state change flow of the service.
2. Why was LLM invocation separated from the request flow?
LLM invocation differs from typical business logic. While internal data validation and DB storage usually finish within a relatively predictable timeframe, LLM invocation response times vary based on model load, network conditions, prompt length, and the number of target languages. Including this processing within synchronous requests would cause users to wait for responses due to tasks unrelated to storage.
AlsoThere is also a problem from the perspective of error propagation. If the storage API directly relies on LLM calls, an LLM failure may appear as if it is a failure of the storage functionality. Users may experience that their attempt to save data has failed entirely due to an external model call failure, even though saving and translating are tasks with different responsibilities. In a synchronous structure, the boundary between these two responsibilities becomes blurred.
AsynchronousThe structure mitigates this issue. The save request performs only the saving responsibility and responds quickly. Subsequently, situations requiring translation are expressed as events, and the translation process is carried out separately. This approach is closer to eventual consistency than immediate consistency. Not all translation values may be immediately ready right after saving, but the responsiveness to user requests and the isolation of system failures improve.
[Figure 1. Comparison of Service Response Time: Synchronous Processing vs Asynchronous Processing] 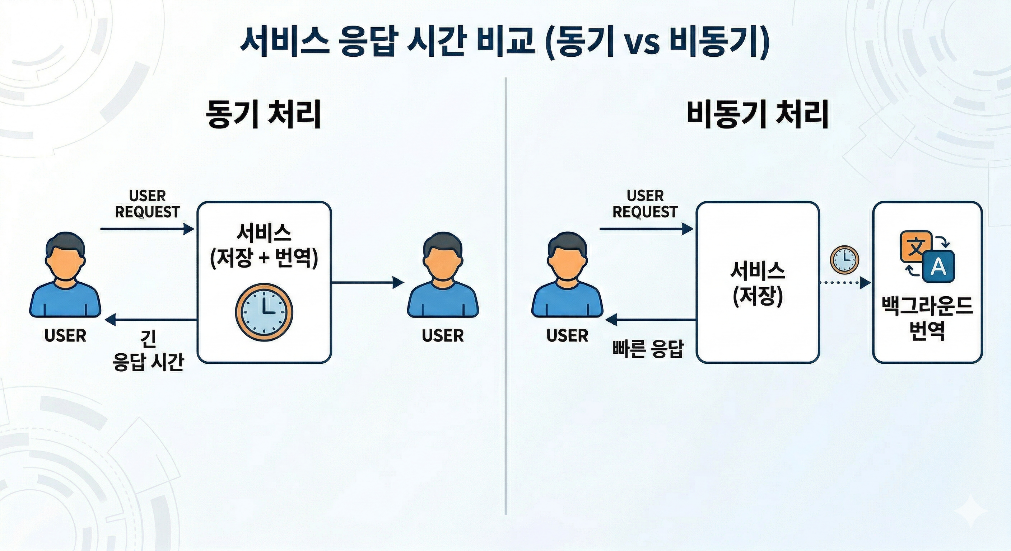
What was important in choosing this structure was not just the aspect of responding quickly. More importantly, it was the ability to clearly separate tasks that could take a long time and handle the success and failure of those tasks through separate event flows.
3. Keep the event contract small.AsynchronousThe first thing that needed to be organized in the structure was the event contract. An event is not just an object that transmits data, but a promise between different processing flows. Since the side issuing the request and the side processing the request are not on the same call stack, the level of coupling in the entire structure varies depending on what information is contained in the event.
At first, it seemed safe to include as much information as possible in the event. However, as the event payload grew larger, the responsibilities of the request stage and the processing stage became mixed. The request event needed to focus on the minimum information required to perform the translation, while the completion event needed to focus on the information necessary to reflect the results. Therefore, we separated the roles of the request event and the completion event.
Request The event contains information on which entities, fields of a certain service need to be translated, the source language and multilingual string information, and whether a forced re-translation is required. Conversely, the completion event is organized to only include the identification information necessary to reflect the translation results and the translated LangStrings. By separating these, the request event focuses on 'what to translate' while the completion event focuses on 'what results to reflect.'
Event Keeping the contract small is advantageous for changes. Internal implementation of translation MEven if it changes from Mock to an actual LLM, the meaning of the request event can be maintained. Even if the way to generate translation results changes, if the result contract expressed by the completion event is maintained, it can reduce the scope of changes on the reflecting side.
4. Not all data, but handled as a patch
TranslationIt was an important decision how to express the results. One way was to present the entire multilingual after completion.It is about returning a string again. However, this method can blur the boundaries between the original data and the translation result. Especially when there are existing values entered by a person, re-reflecting the entire data can lead to unintended overwriting.
SoThe translation result is a set of values that need to be supplemented, that is,patch(patch)I concluded that a direction that handles it more closely is more appropriate. I only aimed to translate the empty language values, and generally excluded languages that already have values. In cases where existing translations need to be recreated, I explicitly set the forceUpdate option to retranslate.
ThisThe policy was more of a safeguard against data changes than just simple business conditions. While automatic translation is convenient, overriding phrases carefully crafted by humans with machine translation results can actually lower quality. Therefore, it was safer to interpret automatic translation results as 'data that complements currently missing values' rather than 'data that always replaces the entire content.'
ThisFrom the perspective of patching, the event-based processing matched well. The request event calculates the target to be translated based on the original state, and the completion event only delivers the results that can be reflected. The one reflecting the results can apply the received translation results to the necessary locations rather than reinterpreting the entire state.
5. LLM responses are not verifiable data
ActualThe biggest realization while connecting to the LLM was that you should not fully trust the LLM's responses. While LLMs excel at generating natural language, they do not always adhere precisely to the required formats of the service data. Although the translations appear natural, they may be broken responses from a data structure perspective.
exampleIn the phrase “Hello, {{name}}.”, {{name}} is not subject to translation. It is a placeholder for the user's name, so it must be preserved in the translation. The same applies to URLs, emails, HTML tags, and format tokens. If such values are removed or changed, it results in a service data error rather than a translation quality issue.
Line breaks alsoIt was an important validation target. The label strings displayed on the screen can include not only simple one-line sentences but also multi-line instructions. In the original text, the meaning units are separated by line breaks, and if the line breaks are removed in the translation, the screen composition or context may change. Therefore, I compared the number of line breaks in the original and translation, and if they differ, I considered it to be a broken structure response.
by languageThe writing system had to be handled separately. For example, Uzbek must consider both Latin and Cyrillic scripts. Simply translating to Uzbek may yield results that differ from the desired writing system. Therefore, language codes that include the writing system, such as uz-Latn and uz-Cyrl, are necessary.promptLConverted to abel and checked if the character system is correct in the response.
ThisI realized that what is important in LLM functionality through the process is not just a good prompt. The prompt guides the desired outcome, but the service code must verify whether that outcome satisfies the actual data rules. LLM responses are not immediately reliable data; they are closer to candidate data that can only be reflected after passing the validation.
6. Classifying failuresand separating retry criteria
AsynchronousIn this structure, how to handle failures was also important. In a synchronous API, failures can be returned as HTTP responses, but in event-driven processing, the point of the request and the point of processing are separated. Therefore, failures had to be expressible within the event flow.
All Handling failures in the same way makes operation difficult. Network issues or LLM TimeoutTemporary external failures can succeed with a retry. On the other hand, if there is no reference language, the original text is empty, or the LLM response fails structural validation, simple retries are unlikely to resolve the issue. Therefore, the failure isRetryable(retryable) error and non-retryable error(non-retryable)Divided by error.
For LLM request failures or timeouts, we reported them as retryable errors and delegated the reprocessing to the message handling system's retry flow. Conversely, cases where essential values are missing, the original text is absent, or there are errors in the response format—situations where the data or the contract itself is incorrect—were issued as failure events. By doing this, we can handle temporary external failures and data contract issues in different ways.
FailureLeaving events makes subsequent processing clearer. The failed entities and fields, error codes, and retry possibilities can be recorded as events, which can then be utilized in operational tools or separate correction flows. In an asynchronous structure, I felt it is more robust to express failures as events that the system can understand rather than simply logging them.
7. Mock verification to Live LLM verification
Initial Instead of directly connecting the actual LLM in the stage MWe first validated the event flow based on ock. When we attach the actual model directly, it is difficult to immediately distinguish whether the issue is with the event contract, response parsing, or model invocation. So first, MI checked whether the request event is passed through the processing flow via Mock, whether the completion event is published, and whether the translation target calculation works as intended.
NextWe then connected the actual LLM to check the translation quality and response validation logic. At this time, we did not just look at whether the translation result was not empty. We also checked whether the placeholders were maintained, whether the line breaks were preserved, whether the character system was correct, whether the defaultLangCode was used as the base language when baseLangCode was omitted, and whether forceUpdate affected the retranslation of existing values.
thisThrough the testing process, we confirmed again that 'the LLM responded' and 'it can be safely reflected with service data' are two different issues. The LLM integration test needs to check not only the success of the model call but also whether the results meet the data contract required by the system.
8. Conclusion
thisI realized that when integrating LLM functionality into a service, it's not just the code that calls the model that is important. It is also necessary to separate tasks with high latency from the request flow, keep event contracts small, convert LLM responses into verifiable data, and distinguish between retryable and non-retryable failures.
In the endThe core of the LLM automatic translation function was not to 'have the LLM translate,' but to create a structure that safely handles the results of the LLM within the service data flow. This design separated the LLM calls into an event-driven asynchronous flow and was an attempt to handle non-deterministic responses within validation, failure processing, and observability.
jyyou
[References]
Microsoft Learn, Asynchronous request-response pattern
https://learn.microsoft.com/en-us/azure/architecture/patterns/asynchronous-request-reply
IBM, What is event-driven architecture?
https://www.ibm.com/kr-ko/think/topics/event-driven-architecture
KakaoPay Technology Blog, Using Event-Driven Appropriately
https://tech.kakaopay.com/post/event-driven-architecture/