"Как только я подумал: 'Очерчивать надо только один OCR', реальные проблемы начали возникать."
Я выбрал тестовый случай с PDF математической задачи, чтобы предварительно проверить конвейер структурирования неформальных документов. Это были подходящие данные для проверки анализа макета и семантического сопоставления, так как области задачи и номера четко разделены, но также имеют смешанную структуру с макетом 1-го и 2-го уровня.
Но реальные данные оказались гораздо сложнее, чем ожидалось. Номера пунктов и текст были плотно связаны на уровне пикселей, и структура макета различалась на каждой странице. В конечном итоге стало быстро очевидно, что простое OCR не может надежно восстановить структуру пунктов.
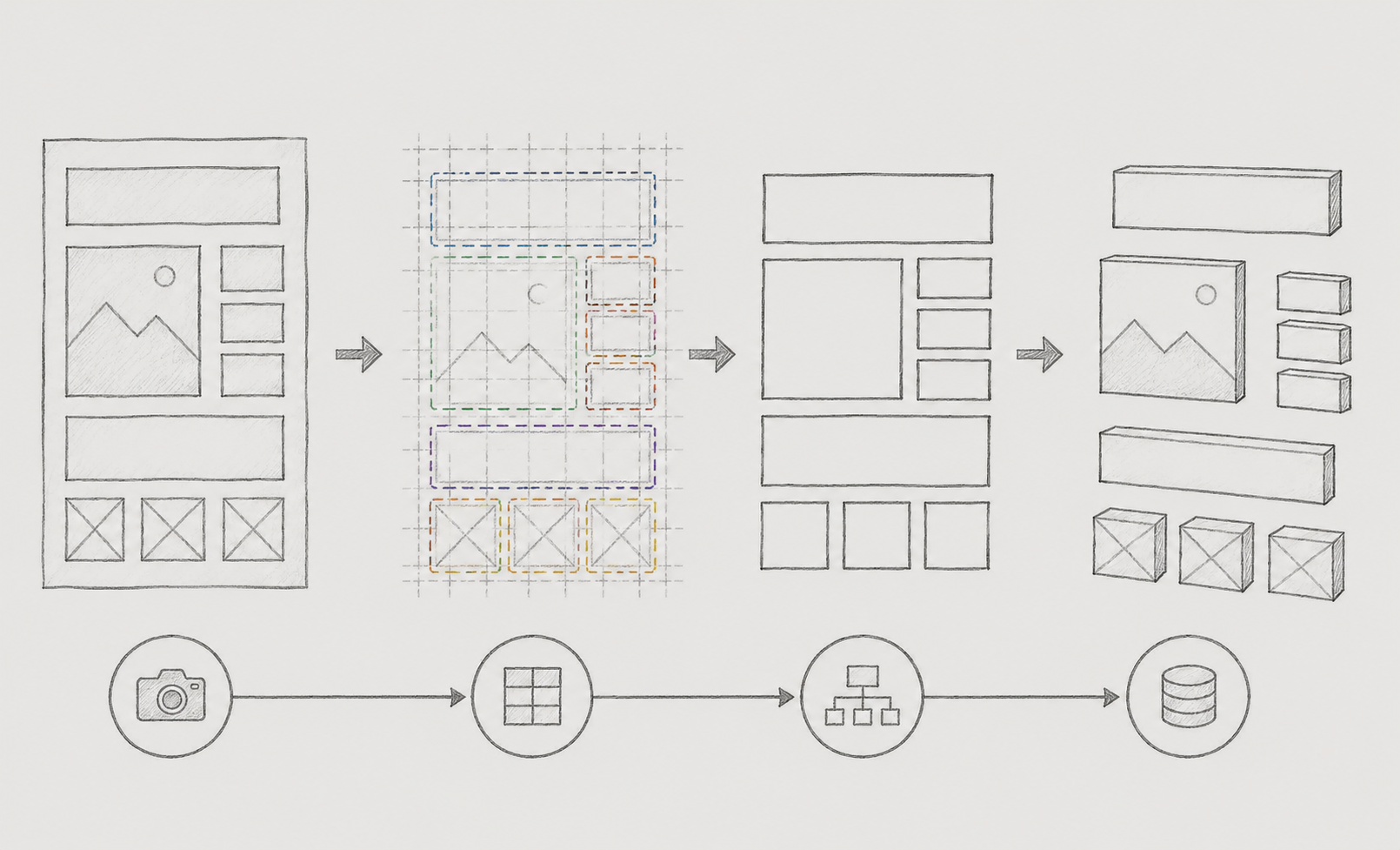
В этой статье описывается разработка 4-ступенчатого пайплайна, который включает в себя обнаружение Vision → выравнивание координат → отображение → OCR, а также процесс улучшения через повторные неудачи.
1. Обоснование выбора технологии — почему сначала должна была использоваться диагностика Vision
В процессе структурирования PDF-материалов с математическими задачами мы вначале выбрали подход с применением OCR. В то время мы думали, что если уровень распознавания OCR будет достаточно высок, то структура задачи восстановится естественным образом.
Однако в реальных тестах возникли совершенно неожиданные проблемы. Особенно в документах с комбинированной двухколоночной версткой OCR не смог распознать текст в порядке, в котором его читает человек. Порядок вопросов в левой и правой колонках перемешался, и случаи неправильного распознавания номер вопросов, смешанных с некоторыми частями текста, происходили многократно.
Например, в результирующих данных OCR было замечено, что после вопроса 12 следовал вопрос 3, или номера вопросов неверно интерпретировались как часть формулы.
В конечном итоге я понял, что OCR — это "технология чтения текста", а не "технология понимания структуры документа". То есть, пока структура документа не будет надежно организована, независимо от того, насколько велика точность распознавания OCR, реальные результаты не могут быть использованы как есть.
После этого я полностью изменил направление подхода. Сначала я определил саму структуру документа, а OCR был переработан так, чтобы он выполнял лишь функцию чтения текста внутри каждой области.
Особенно мы прежде всего учитывали следующие критерии.
-
Независимо от того, является ли макет одноуровневым или двухуровневым, порядок вопросов должен быть надежно восстановлен.
-
Некоторые сбои OCR не приведут к остановке общего потока обработки партии
-
Структура должна быть расширяемой на другие области, такие как анализ макета веб-интерфейса в будущем
В результате мы переключились с подхода, сосредоточенного на OCR, на подход, ориентированный на анализ структуры на основе зрения.
2. Применяемая архитектура и процесс реализации
Вся трубопроводная система была спроектирована с разделением на 4 основных этапа. Наиболее важным аспектом было снижение взаимозависимости между этапами. Мы стремились сохранить независимую структуру, чтобы минимально повлиять на общий поток, даже если конкретные модули будут заменены или изменены.
Кроме того, система была спроектирована так, чтобы позволить тестирование на каждом этапе, что позволяет быстро отслеживать, на каком этапе произошла ошибка в случае возникновения проблем.
2.1 Создание данных и обучение YOLOv8
В качестве модели для обнаружения объектов была выбрана YOLOv8 от Ultralytics. Она имела структуру, способную обеспечивать достаточно высокий mAP даже при реальном времени, и это позволяло использовать экосистему Ultralytics, что было преимуществом для быстрого построения процессов обучения, вывода и валидации модели.
Класс был определен двумя основными компонентами: проблемным блоком (область вопроса) и номерным блоком (область номера). Эти две области имеют четко различающиеся семантические единицы, и для обеспечения их 1:1 соответствия на этапе сопоставления необходимо было разделенное обучение. Начиная с этого момента, мы будем обозначать эти две области как проблемный блок и номерный блок.
Однако в реальном проекте наибольшее время было потрачено не на саму модель, а на упорядочение правил маркировки. Необходимо было четко разграничить область проблем и область номера, и в случаях, когда границы пересекались, всегда нужно было маркировать по единым критериям.
В реальных учебных процессах повторялись случаи, когда при небольших колебаниях в критериях разметки модель обучалась в направлении, отличном от задуманного. Например, в одних данных я захватывал широкий короб с номером пункта, а в других — только номером, в результате чего модель не могла обучиться последовательным характеристикам.
В конечном итоге стало ясно, что важнее производительности модели является "последовательное определение данных".
2.2 Предварительная обработка OCR — 2-кратное увеличение и бинаризация
После завершения обнаружения Vision было выполнено предварительное преобразование, чтобы OCR мог стабильно считывать цифры, после обрезки боксов с номерами. Сначала мы передали Tesseract оригинальное разрешение, но процент распознавания для маленьких номеров вопросов оказался ниже ожидаемого.
Я попытался применить метод, который сначала увеличивает обрезанную область до целого числа с помощью алгоритма ближайшего соседа, а затем применяет преобразование в градации серого и бинаризацию (Otsu). При сравнении с размерами увеличения 2x/3x и так далее, 2x оказалась наиболее стабильной для данных данного домена.
Когда я увеличил масштаб еще больше, распознавание стало менее устойчивым. Даже при фиксированном интерполяционном алгоритме nearest, шум на уровне пикселей увеличивался, что противоречит внутренним предположениям нормализации Tesseract, и поэтому контуры маленьких цифр размывались.
Кроме того, мы не зафиксировали PSM (Режим сегментации страниц) на едином значении, а организовали его таким образом, что сначала используется одиночный блок (PSM 6), а при неудаче повторяем попытку с одиночной строкой (PSM 7). Поскольку количество символов в поле number было коротким, всего 1–3 символа, колебания результатов были значительными в зависимости от PSM.
Самый важный урок, извлеченный из этого процесса, заключался в том, что "характеристики входных данных и настройки модели · движка должны быть согласованы друг с другом, чтобы можно было добиться реального улучшения производительности". Просто увеличение разрешения или смена режима не привели к повышению точности распознавания.
Дизайн восстановления координатной структуры макета и сопоставления оценок
Мы реализовали логику сортировки координат для восстановления действительного порядка чтения документа на основе обнаруженных коробок. Сначала мы разделили проблемные коробки на левую и правую колонки по среднему значению по оси x (image_width × 0.5) ширины страницы. Затем внутри каждой колонки мы отсортировали по оси y, а затем по оси x, чтобы создать порядок, аналогичный реальному потоку чтения человека.
В этом курсе удалось относительно стабильно восстановить порядок вопросов даже в документах с смешанными макетами 1-го и 2-го уровней.
Далее связь между рамками problem и number вместо простого евклидова расстояния была основана на нормализованной весовой оценке, учитывающей особенности домена. В макете математических задач номера вопросов, как правило, находятся на одинаковом расстоянии от верхнего левого угла текста, что делает выравнивание по горизонтали (x) более надежным сигналом, чем выравнивание по вертикали (y).
score = 0.55 × (|nx − px| / p_width) + 0.35 × (|ny − py| / p_height) + 0.10 × (1 − y_overlap_ratio)
+ size_penalty # size_penalty = max(0, (n_area / p_area) − 0.08) × 3.0Каждая переменная, присутствующая в формуле, имеет следующее значение.
-
px, py : координаты верхнего левого угла коробки проблемы (опорная точка)
-
nx, ny : координаты верхнего левого угла поля кандидатов на сопоставление
-
p_width, p_height : ширина и высота поля задачи. Используется для нормализации значений расстояния согласно размеру поля задачи
-
y_overlap_ratio : коэффициент перекрытия между рамкой проблемы и рамкой числа по оси y (0 ~ 1)
-
p_area, n_area : площадь рамок проблемы и числа. Для расчёта размера штрафа
Чем ниже счет, тем лучше кандидат на соответствие, и для каждого блока проблемы выбраны номера с самым низким баллом для связи 1:1. Основная цель проектирования следующая:
-
dx и dy были нормализованы по ширине и высоте блока проблемы соответственно, чтобы сделать возможным сравнение даже при разных размерах блоков.
-
Номер элемента имеет тенденцию располагаться в верхнем левом углу текста, поэтому была придана больший вес (0.55) разнице по оси x, чтобы приоритет отдать горизонтальному выравниванию.
-
Учитывая y_overlap_ratio, ящики, которые находятся на близком расстоянии, но совершенно не перекрываются вертикально, естественным образом удалялись из списка кандидатов на соответствие.
-
Если размер коробки number аномально велик (превышает 8% площади коробки problem), был введен штраф size_penalty, чтобы подавить случаи неправильного соответствия больших коробок.
В результате удалось стабильно снизить количество случаев, когда номера элементов, расположенных в два ряда или рядом с другими элементами, измеряются ближе, чем при использовании простой евклидовой дистанции.
Также логика Fallback в случае сбоя OCR была очень важна. В первоначальной версии было реализовано прекращение всего задания при сбое OCR, но в реальной рабочей среде возникла проблема, когда некоторые сбои OCR приводили к остановке всего процесса обработки.
Чтобы решить эту проблему, мы изменили алгоритм, чтобы в случае, если OCR не смог извлечь значимый номер, автоматически присваивался временный идентификатор, комбинирующий номер страницы и порядковый номер.
if not real_number: real_number = f"{page_num}-{i + 1}" # 예: "3-7"Благодаря этому методу, даже если произошли некоторые ошибки OCR, общая компоновка не была приостановлена, и данные могли продолжать передаваться на следующий этап проверки. В результате, мы смогли добиться значительного улучшения в плане устойчивости системы.
Ниже представлена таблица, которая наглядно подводит итоги четырехступенчатого пайплайна, описанного выше.
|
Этап |
Модуль |
Содержимое обработки |
Примечание |
|---|---|---|---|
|
① |
Обнаружение |
YOLOv8(Ultralytics) — проблема · обнаружение боксов, фильтрация по порогу уверенности |
независимая замена |
|
② |
Гео. Сорт |
Разделение столбцов по среднему значению по оси x → Сортировка по оси y для каждого столбца → Слева → Объединение справа |
Независимая замена |
|
③ |
Сопоставление |
проблема ↔ номер основанное на взвешенных баллах минимальное соответствие → структура объекта вопроса |
независимая замена |
|
④ |
OCR |
номер коробки обрезка → предварительная обработка (2x увеличение · градации серого · бинаризация) → Tesseract / в случае неудачи назначить резервный идентификатор |
независимая заменяемость |
3. Результаты применения
Поскольку на данном этапе еще не было построено официального набора данных для бенчмарков, результаты были организованы на основе наблюдательных данных из операционной среды.
Наибольшее улучшение было в точности восстановления порядка вопросов. В предыдущей структуре, ориентированной на OCR, вероятность ошибок в порядке вопросов была довольно высокой, а особенно часто возникали проблемы с перемешиванием порядка в двухуровневом макете. Однако после выполнения анализа макета на основе Vision такие ошибки значительно снизились.
Кроме того, возможность продолжать обработку через структуру Fallback без полного приостановления всей группы в случае неудачи OCR значительно улучшила операционную стабильность. Особенно отмечаемое снижение доли ручной дообработки имело большое значение с точки зрения фактической операционной эффективности. Ранее часто приходилось вручную исправлять порядок на страницах с перемешанным макетом, но после применения в большинстве случаев это можно было делать автоматически.
|
Оценочные критерии |
Перед применением |
После применения |
Примечание |
|---|---|---|---|
|
Ошибки порядка вопросов |
~23% |
~4% |
Критерии управления наблюдением |
|
Частота прерываний при пакетировании |
Интермиттирующее прерывание |
практически 0 дел |
операционные наблюдательные стандарты |
|
Обработка смешанных макетов |
Необходима ручная дообработка |
Автоматическая классификация |
Стандарты операционных наблюдений |
|
Устойчивость к отказам трубопроводов |
Единичный сбой → полная остановка |
Изоляция с запасом |
Критерии операционного наблюдения |
4. Ограничения и планы на будущее
Эта PoC позволила подтвердить базовую структуру документооборота на основе Vision. Однако есть и очевидные области, требующие улучшения.
В частности, для документов с составными макетами на 3 и более уровней или для обработки отдельных формул стабильность все еще недостаточна. Особенно для областей, содержащих только формулы, которые имеют отличия от обычных текстовых областей, вероятно, потребуется отдельная модель или дополнительные стратегии постобработки.
Кроме того, веса на этапе сопоставления (0.55 / 0.35 / 0.10) и порог значения размера (0.08) в настоящее время являются значениями, настроенными эвристически на основе операционных данных. В будущем, когда достаточно данных будет накоплено, также будет рассматриваться возможность автоматического поиска этих значений на основе валидационного набора или замена их на модели сопоставления на основе обучения.
Я также считаю, что работа по более тонкой настройке семантических связей между результатами OCR и результатами визуального обнаружения станет важной задачей в будущем.
В дальнейшем мы планируем расширить текущее проверенное строение до анализа веб-UI макетов и автоматической генерации руководств по функционалу экрана. Особенно в области обнаружения компонентов на основе захвата экрана и анализа структуры UI также ожидается, что текущая структура сможет быть использована в значительной степени.
Я смог лично ощутить, что в реальных эксплуатационных условиях существует множество проблем, которые невозможно решить только с помощью простого OCR. В конечном итоге важно не "читать текст", а "понимать структуру" — это был опыт, который еще раз подтвердил это.
-
Ultralytics, "YOLOv8 Документация", https://docs.ultralytics.com
-
Смит, Р., "Обзор движка Tesseract OCR", ICDAR, 2007.
-
Оцу, Н., "Метод выбора порога из гистограмм уровня серого", IEEE Trans. on Systems, Man, and Cybernetics, 1979.
Литература
Junny