1. 개요
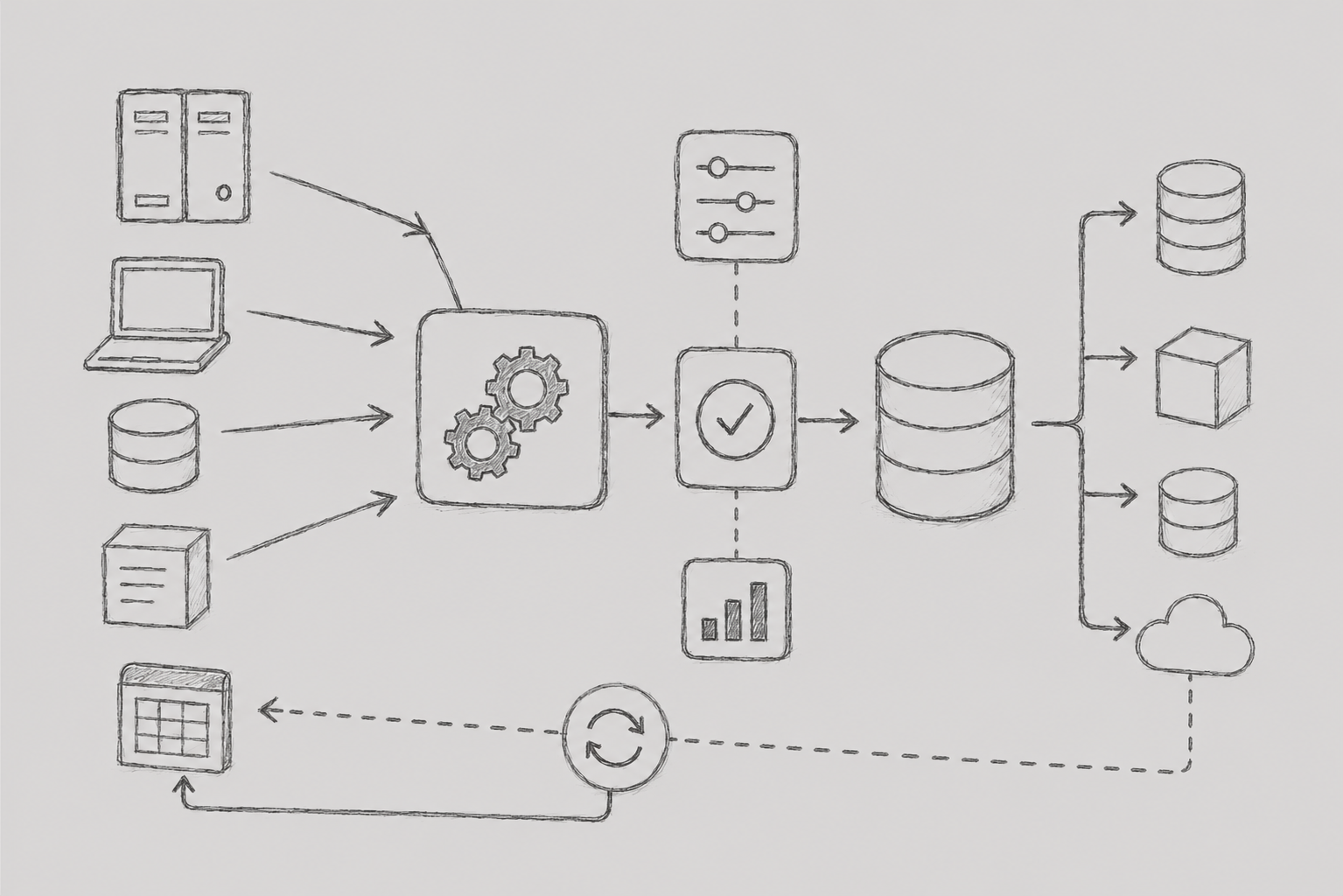
프로젝트 관리 플랫폼은 한 기업의 프로젝트별 activity 데이터를 여러 레거시 시스템에서 수집하여 사업 인력이 일정과 작업을 한 곳에서 관리할 수 있도록 하는 시스템입니다.
레거시 데이터는 외부 ETL을 통해 6개 시스템, 23개 테이블로부터 수집됩니다. 이때 핵심적인 제약이 있었는데, 프로젝트 관리 플랫폼에서 사용하는 하위 데이터가 상위 데이터의 key를 참조하는 구조이기 때문에 단순히 전체 삭제 후 재저장하는 방식을 사용할 수 없었습니다. 이로 인해 기존 데이터와 비교하여 변경이 필요한 데이터만 선별적으로 최신화하는 방식이 필요했습니다.
여기에 더해 레거시 시스템마다 데이터 구조가 달랐고, ETL 적재 완료 여부를 외부에서 확인할 방법도 없었습니다. 이 제약들을 고려하여 적재 검증, 대상 선별, 동기화까지 전체 흐름을 설계한 것이 이번 배치의 핵심입니다.
2. 주요 고려 사항
- ETL 데이터는 적재 성공 여부를 사전에 확인하기 어려워 테이블별 상태를 검증하는 구조 필요함
- 테이블 간 의존 관계(JOIN)를 고려해, 필요한 데이터가 모두 준비된 경우에만 쿼리가 실행되도록 제어
- 기존 JPA 기반 처리에서 발생하던 성능 문제를 해결하기 위해 배치 구간에서는 JDBC Batch 및 프로시저 방식으로 처리
- 오류 발생 시 일부 데이터만 반영되는 상황을 막기 위해 단계별로 트랜잭션을 분리
- 전체 재처리를 피하기 위해 기존 데이터와 비교해 필요한 데이터만 처리
- 향후 레거시 시스템 추가를 고려해 Enum 기반으로 확장 가능한 구조로 설계
- 오류 지점을 파악할 수 있도록 각 단계별 로그 관리
3. 처리 흐름
프로젝트 관리 플랫폼 : 스트리밍 데이터 수신 → 스테이징 적재 → 데이터 비교 기반 처리(Insert/Update/Delete Flag) → 운영 테이블 반영 → 배치 종료
3.1 데이터 적재 검증
배치 시작 시 모든 대상 테이블에 대해 COUNT 쿼리를 수행하여 데이터 적재 여부를 확인 후 저장합니다. ETL 마지막에 삽입되는 NULL row를 기준으로 적재 완료 여부를 판단해 각 테이블의 상태를 기록하여 이후 실행 여부를 판단하는 기준으로 활용하였습니다.
배치 실행 시에는 이 정보를 기반으로 실제 실행 가능한 쿼리만 선별하도록 구성하였고, JOIN이 포함된 경우에는 관련된 모든 테이블이 정상적으로 적재된 상태인지 확인한 이후에만 실행되도록 제어하였습니다.
3.2 배치 대상 데이터 선별
최상위 데이터의 양이 많아서 전체 데이터를 반복 처리하는 방식은 비효율적이었습니다. 때문에 배치 실행 시점 기준으로 선택된 데이터만을 작업 대상으로 선별하였고, 기존 배치 결과와 비교해 레거시에 신규 데이터가 존재할 경우 배치에 포함하도록 구성하였습니다.
3.3 스테이징 적재
스테이징 단계는 레거시 테이블에서 데이터를 추출해 원본 그대로 저장하는 단계입니다. 스테이징에 적재 전 이전 데이터를 모두 삭제한 후 새로 저장합니다. 이후 최상위 데이터부터 하위 데이터 순으로 적재를 진행합니다.
이 단계는 이후 집계 처리의 기준 데이터가 되는 구간이기 때문에 최상위 데이터 적재 중 오류가 발생하면 다음 단계로 넘기지 않고 배치를 종료하도록 구성했습니다. 대량 삽입에 최적화된 JDBC Batch Update를 사용했습니다.
3.4 집계 테이블 처리
집계 단계에서는 기존 데이터와 스테이징 데이터를 비교하여 상태를 맞추는 방식으로 동기화를 합니다. 최초 시점에는 전체 데이터를 저장하고 이후에는 레거시에서 변경된 데이터만 작업합니다.
신규 데이터는 생성하고, 변경된 데이터는 수정하며, 기존에는 존재했으나 현재 데이터에 없는 경우에는 삭제 플래그를 설정하였습니다. 집계 단계는 기존 데이터와의 비교 로직에 시간이 많이 걸리고 처리할 대상이 많기 때문에 애플리케이션 레벨보다 DB에서 직접 처리하는 것이 유리하다고 판단해 프로시저를 사용했습니다.
3.5 데이터 동기화
집계에서 저장된 상태값에 따라 데이터 동기화가 필요한 데이터를 선별하여 필요한 작업만 진행할 수 있도록 구성했습니다. 집계에서 저장된 상태값을 기준으로 운영 테이블에 동일한 방식으로 반영합니다.
3.6 MSA 연계
shared에서 데이터 처리가 완료되면 프로젝트 관리 플랫폼 서버로 이벤트를 발행합니다. 프로젝트 관리 플랫폼 서버는 batchId를 기반으로 데이터를 요청하고, 데이터는 스트리밍 방식으로 1,000건 단위로 분할 전송됩니다.
초기에는 데이터를 수신받자마자 오류가 발생하는 문제가 있었는데, 송수신 처리가 같은 흐름 안에 묶여있어 수신 측 작업이 시작되기 전에 문제가 생기는 것이 원인이었습니다. 이를 해결하기 위해 수신 후 처리 작업을 별도 스레드로 분리하여 독립적으로 실행되도록 구성했습니다.
수신 서버에서는 전달받은 데이터를 스테이징에 적재한 후 동일한 방식으로 동기화를 수행하고, 모든 작업이 완료되면 shared 배치 상태를 종료로 처리합니다.
4. 결과 및 효과
적재 검증 단계를 통해 데이터가 정상적으로 들어오지 않은 상태에서 배치가 실행되는 상황을 사전에 차단할 수 있었습니다. 또한 전체 삭제 후 재저장 대신 변경분만 선별해 처리하는 방식으로 하위 데이터의 key 참조 관계를 유지하면서도 데이터를 안정적으로 최신화할 수 있었습니다.
레거시에서 데이터를 추출하는 SQL은 템플릿 형태의 Enum으로 관리하고, 시스템 및 데이터 종류별 테이블 목록도 별도 Enum으로 분리하여 관리합니다. 향후 레거시 시스템이 추가되더라도 Enum 항목을 추가하는 것만으로 확장이 가능합니다.
성능 측면에서는 JPA 단건 처리에서 프로시저 기반으로 전환하면서 배치 처리 시간이 10분 이상에서 1~2분 수준으로 줄었습니다. MSA 연계 구간에서는 스레드 분리를 통해 수신과 처리를 독립적으로 실행하도록 구성해 안정성을 확보했습니다.
각 단계마다 로그를 기록하여 오류 발생 시 원인을 추적할 수 있도록 했습니다. 모든 로그는 batchId를 기준으로 조회할 수 있어 특정 배치 실행에서 어느 단계에 문제가 있었는지와 생성, 수정, 삭제에 대한 통계도 파악이 가능합니다.
5. 결론
이번 배치의 핵심 제약은 하위 데이터가 상위 데이터의 key를 참조하는 구조로 인해 전체 삭제 후 재저장 방식을 쓸 수 없다는 점이었습니다. 이 제약 안에서 데이터를 안정적으로 최신화하기 위해 적재 검증, 변경분 선별, 단계별 동기화로 흐름을 나누고, 각 단계에서 오류가 생기면 즉시 멈추는 구조로 설계했습니다.
레거시 데이터 특성상 수량을 사전에 알 수 없고 매번 달라지기 때문에 대용량 처리를 전제로 설계해야 했습니다. 기존 JPA 구조로는 이를 감당하기 어려워 JDBC Batch, 프로시저, 스트리밍 분할 전송 등 여러 방식을 검토한 끝에 구간별로 적합한 방식을 선택했습니다.
외부 ETL이나 레거시 시스템을 직접 제어할 수 없는 환경에서, 제어 가능한 범위 안에서 검증과 방어 로직을 촘촘히 쌓아 안정적인 배치를 만든 것이 이번 작업의 핵심이었습니다.