
1. 개요 (Executive Summary)
본 프로젝트는 병원 내 파편화되어 존재하는 다양한 레거시 데이터를 국제 의료 정보 표준인 HL7 FHIR R4(8.6.5) 체계로 통합하고, 데이터의 정밀한 임상적 유효성을 실시간으로 검증하는 고성능 표준화 플랫폼 구축을 목표로 수행되었습니다.
단순한 데이터 변환(Mapping)을 넘어, 내부망에 독립적으로 구축된 Snowstorm(SNOMED CT 전용 서버)과 Elasticsearch를 결합한 마이크로서비스 아키텍처(MSA)를 통해, 데이터의 구조적 무결성과 의미적 정확성을 동시에 확보하는 하이브리드 검증 체계를 완성하였습니다. 본 보고서는 해당 플랫폼의 시스템 구성, 상세 처리 프로세스 및 주요 기술적 성과를 상세히 기술합니다.
2. 전체 시스템 구성 (System Architecture)
전체 시스템은 데이터의 발생부터 변환, 검증, 저장 및 모니터링에 이르는 전 과정을 마이크로서비스 단위로 분리하여 유연성과 확장성을 확보하였습니다.
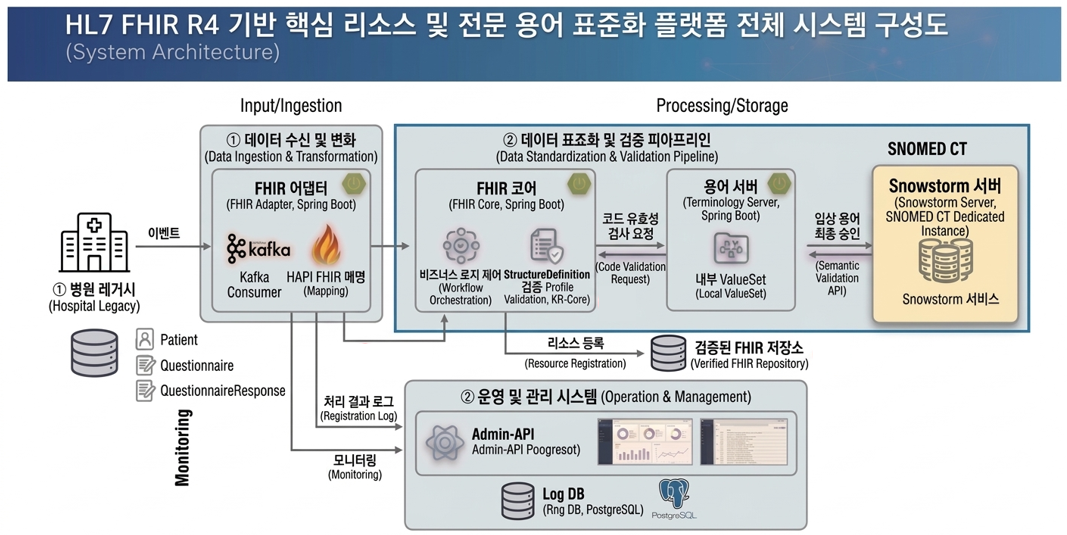
2.1 데이터 수신 및 변환 레이어 (Input/Ingestion)
- 병원 레거시 (Hospital Legacy): 데이터의 원천으로 Patient(환자), Questionnaire(설문 양식), QuestionnaireResponse(응답) 등의 데이터가 발생하는 단계입니다.
- FHIR 어댑터 (FHIR Adapter): Spring Boot 기반으로 구축되었으며, Kafka를 통해 레거시 이벤트를 비동기로 수신합니다. 수신된 원천 데이터는 HAPI FHIR 라이브러리를 통해 표준 리소스 객체로 1차 매핑됩니다.
2.2 표준화 및 검증 레이어 (Processing/Validation)
- FHIR 코어 (FHIR Core): 리소스의 구조적 적합성을 판단합니다. 특히 국내 의료 환경에 특화된 KR-Core 가이드라인 준수 여부를 검증합니다.
- 용어 서버 (Terminology Server): 리소스 내에 포함된 각종 의료 코드를 추출하여 내부 관리 ValueSet과 대조합니다.
- Snowstorm 서버: SNOMED CT 표준 데이터를 보유한 독립 서버로, 복잡한 임상 용어의 최종 승인을 담당합니다.
- Elasticsearch: 방대한 전문 용어 데이터의 인덱싱을 통해 고속의 키워드 검색 및 매핑 성능을 제공합니다.
2.3 운영 및 관리 레이어 (Operation & Management)
- Admin-API & UI: 전체 파이프라인의 처리 결과(성공/실패 사유)를 실시간으로 모니터링하며, 실패한 데이터에 대한 재처리 및 로그 분석 기능을 제공합니다.
3. 상세 데이터 처리 프로세스 (Data Pipeline)
데이터가 레거시 시스템에서 발생하여 최종 FHIR 저장소에 안착하기까지는 총 3단계의 엄격한 프로세스를 거칩니다.
Step 1: 이벤트 수신 및 객체 변환 (Ingestion)
레거시 시스템에서 데이터 발생 시 Kafka Topic으로 이벤트가 발행됩니다. FHIR 어댑터는 이를 Consumer하여 사전에 정의된 매핑 정의서에 따라 JSON 형태의 FHIR 리소스로 변환합니다. 이 단계에서 데이터의 누락이나 형식 오류를 1차적으로 필터링합니다.
[이미지 2: Kafka 기반 비동기 데이터 수신 및 변환 로직 흐름도]
Step 2: 다단계 파이프라인 검증 (Multi-stage Validation)
본 시스템의 핵심 역량이 집중된 단계로, 세 가지 측면에서 검증이 이루어집니다.
- 구조 검증 (Structural Validation): 필수 필드 존재 여부, 데이터 타입(String, Code, DateTime 등), 카디널리티(Cardinality)를 체크합니다.
- 프로파일 검증 (Profile Validation): KR-Core 표준 또는 사용자정의(Questionnaire, QuestionnaireResponse) 프로파일에서 요구하는 제약 사항(Constraint)을 만족하는지 확인합니다.
- 용어 검증 (Semantic Validation): 리소스에 포함된 코드가 실제 유효한 병원 내부 코드, LOINC 코드인지 Terminology 서버와 연동하여 확인하고, SNOMED CT 코드인지 Snowstorm 서버와 연동하여 확인합니다.
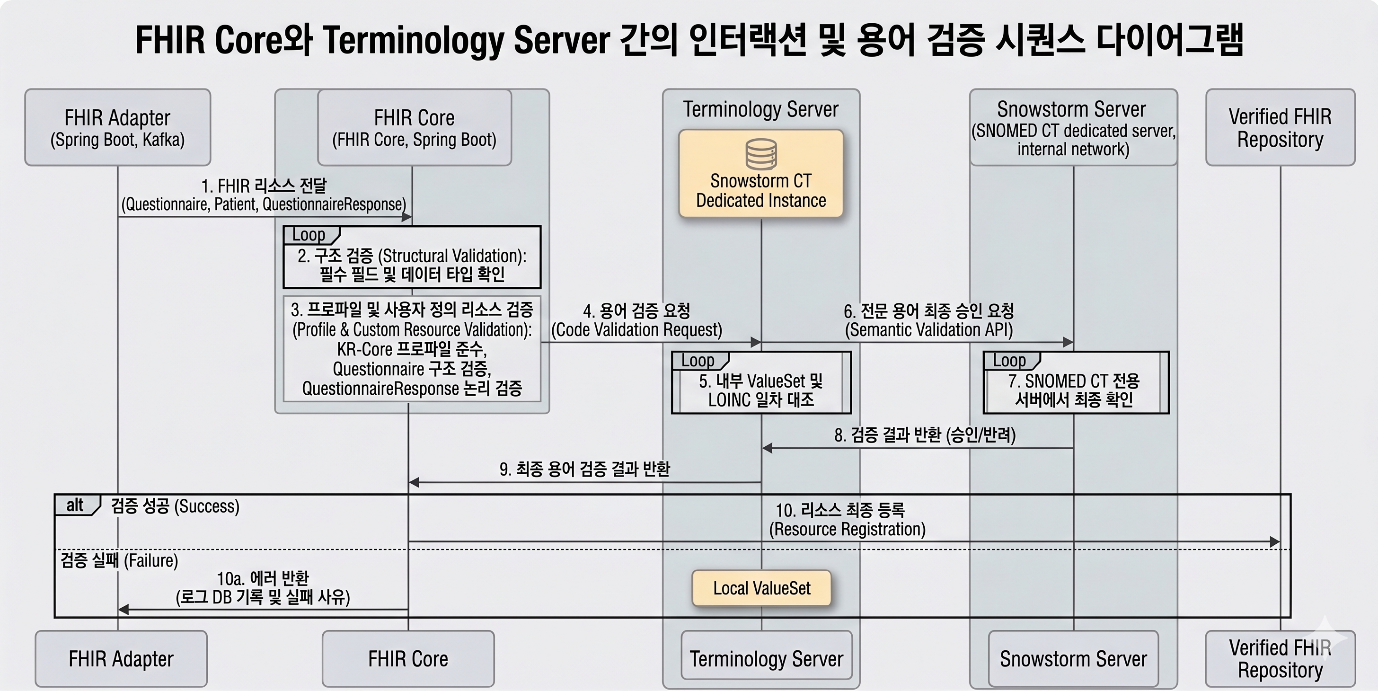
Step 3: 리소스 등록 및 로그 생성 (Storage & Logging)
검증을 통과한 리소스는 Verified FHIR Repository(PostgreSQL/HAPI FHIR JPA 기반)에 영구 저장됩니다. 모든 과정은 Admin-API를 통해 로그 DB에 기록되어, 운영자가 특정 환자의 데이터 표준화 과정을 추적할 수 있도록 지원합니다.
4. 핵심 기술적 성과 (Technical Achievements)
4.1 하이브리드 용어 검증 체계 확립
기존의 단순 코드 매핑 방식에서 벗어나, 실제 표준 데이터를 보유한 Snowstorm 서버와 검색 최적화 엔진인 Elasticsearch를 유기적으로 연동하였습니다. 이를 통해 수십만 건의 임상 용어를 1초 미만(Low-latency)의 속도로 검증할 수 있는 환경을 구축하였으며, 내부망 독립 구축을 통해 의료 데이터 보안성을 극대화하였습니다.
4.2 KR-Core 가이드라인의 완전한 내재화
보건복지부와 한국보건의료정보원에서 제시하는 KR-Core(v1.0.2) 가이드라인을 시스템 로직으로 구현하였습니다. StructureDefinition 기반의 검증 로직을 HAPI FHIR Validator에 탑재하여, 국내 표준에 완벽히 부합하는 데이터를 생성할 수 있게 되었습니다.
5. 향후 전망 및 기대효과 (Future Outlook)
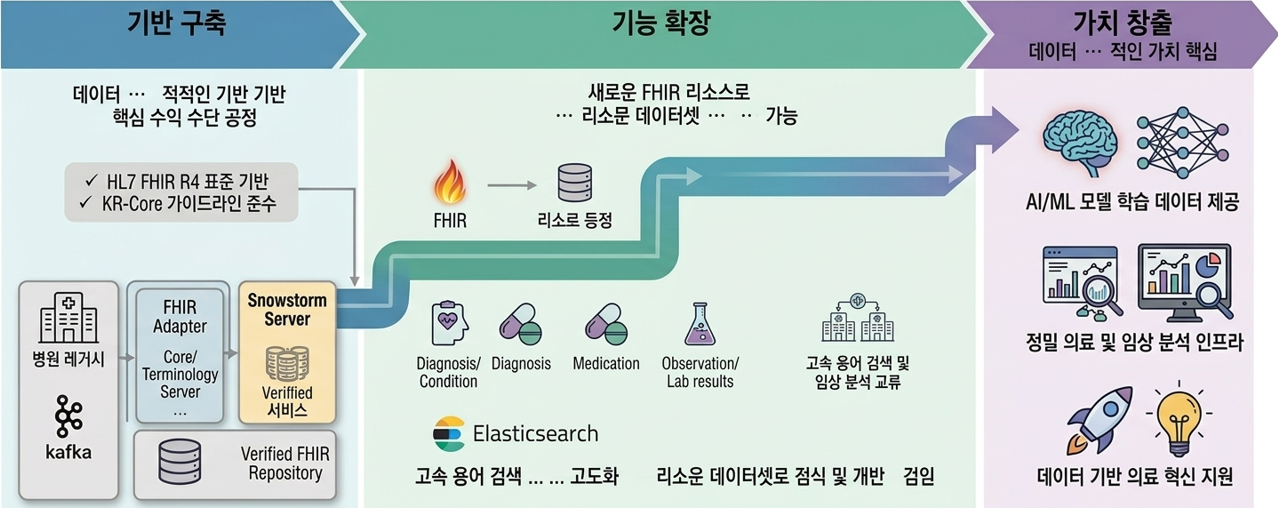
본 플랫폼의 구축은 단순한 시스템 도입 이상의 의미를 가집니다.
- 데이터 품질의 상향 평준화: 실시간 검증을 통해 ‘정제된 표준 데이터’만을 축적함으로써, 향후 AI 학습이나 정밀 의료 분석에 즉각 활용 가능한 고품질 데이터베이스를 확보했습니다.
- 리소스 확장 용이성: 현재 구축된 Patient, Questionnaire 모델을 기반으로 진단(Condition), 처방(Medication), 검사결과(Observation) 등 타 리소스로의 신속한 확장이 가능합니다.
- 상호운용성 기반 마련: 타 병원과의 데이터 교류나 정부 주도의 표준화 사업(예: 나의건강기록 앱 연동) 발생 시 별도의 시스템 개편 없이 표준 인터페이스를 통해 즉각 대응이 가능합니다.
6. 결론 (Conclusion)
이번 FHIR 기반 표준화 플랫폼 구축을 통해 병원 레거시 데이터의 표준화 전환율을 획기적으로 높였으며, 임상 용어의 유효성을 실시간으로 보장하는 기술적 기틀을 마련하였습니다. 이는 향후 데이터 기반 의료 혁신을 위한 핵심 인프라로 기능할 것입니다.
부록: 모듈별 기술 스택 요약
| 구분 | 기술 스택 |
|---|---|
| Language | Java 21, React |
| Framework | Spring Boot 3.5, HAPI FHIR 8.5 |
| Middleware | Apache Kafka, Elasticsearch 8.17 |
| Database | PostgreSQL (JSONB) |
| Standard | HL7 FHIR R4, KR-Core 1.0.2, SNOMED CT |