1. Introduction
The problem I faced while participating in the Medical System MSA Transition Project was data duplication. The new MSA system (PostgreSQL) and the existing legacy system (Oracle) had to be operated side by side, and there was a requirement to maintain data consistency in real-time while both systems were simultaneously serving.
Batch synchronization caused delays of several minutes, making it unsuitable for the healthcare domain, the DB trigger method added operational burdens to the legacy Oracle, and application dual writes made it difficult to ensure transaction atomicity. After reviewing various methods, we decided to adopt the CDC (Change Data Capture) method, which directly reads the transaction logs from the source DB and propagates them asynchronously.
2. Architecture: Debezium and custom synchronization application
Debezium is an open-source CDC platform that directly subscribes to the WAL (Write-Ahead Log) of PostgreSQL, publishing INSERT/UPDATE/DELETE events in real-time to Kafka. Since it reads the WAL logs without triggering the source DB or changing the code, it did not require touching legacy systems, and the ability to continue from the last processed log position (LSN) even after the connector restarts aligned well with the project's requirements.
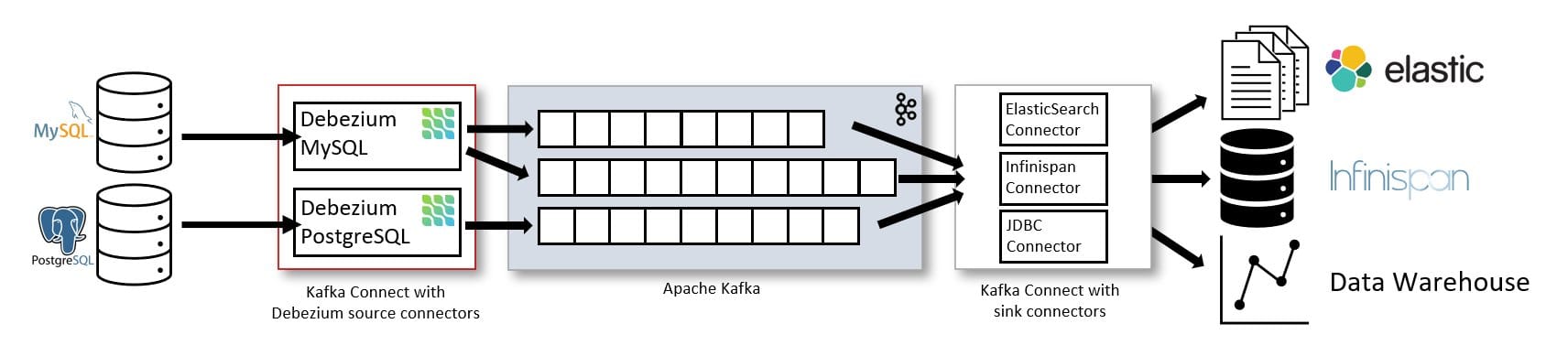
[Figure 1] Debezium Official Architecture — Source: debezium.io/documentation/reference/3.5 (Apache License 2.0)
|
Category |
Technology |
Role |
|---|---|---|
|
Source DB |
PostgreSQL |
Data Change Source (WAL-based CDC) |
|
CDC engine |
Debezium 3.x |
WAL detection → Kafka event publication |
|
Event bus |
Apache Kafka |
at-least-once delivery guarantee (possible duplicate publishing → Consumer idempotency handling required) |
|
Synchronization App |
Data-Sync (Spring Boot) |
Event consumption, Oracle reflection, consistency hash storage |
|
Target DB |
Oracle |
Final synchronization target for legacy systems |
There were three main reasons for directly developing a custom Spring Boot application (Data-Sync) instead of using the standard Sink Connector.
Schema transformation - The complex PK, non-standard column names, and type conversions (timestamptz → TIMESTAMP WITH LOCAL TIME ZONE, etc.) of legacy Oracle were difficult to handle with standard Connector settings alone.
Error handling - We needed to have different retry intervals and notification methods based on the type of error, and for this, the flexibility of custom code was necessary.
Consistency validation - There was also a requirement to asynchronously store the data hash after synchronization is complete in order to periodically verify consistency between the two systems.
3. Durability Verification: Fault Response Testing
After the design was completed, I wanted to check whether the system would not lose data even in the event of a failure before it was actually put into operation. I independently executed scenarios in a development environment Kubernetes cluster, verifying each time whether 20,000 records of data were input into PostgreSQL and successfully loaded into Oracle without any loss.
|
Scenario |
Disability Condition |
Recovery Mechanism |
Result |
|---|---|---|---|
|
Kafka Partition Leader failure |
Forced shutdown of the leader broker during transmission |
Kafka Controller elects another broker as the leader within the ISR, Debezium automatic reconnection |
✓ No loss |
|
Complete failure of Kafka Cluster |
Delete all broker pods and redeploy |
Kafka Connect offset topic (PVC retain) works with PostgreSQL replication slot to continue from the last LSN to WAL |
✓ No loss |
|
Debezium Connector failure |
Forced termination of the connector during CDC processing |
Automatically resume reading WAL from the last LSN recorded in the replication slot |
✓ No data loss |
|
The reason there was no data loss even after the Kafka cluster was fully redeployed is due to the operation of the Kafka Connect offset topic and The offset topic was made possible thanks to preserving the last processed Kafka position, and the replication slot preserves the WAL's LSN position. |
|---|
4. Conclusion: Limitations and Lessons Learned, and Future
◆ Limitations of Initial Design
The method of directly storing column information required for synchronization in the Data-Sync internal metadata table had clear limitations. Each time a column was added to a specific service, changes were needed in Data-Sync as well, compromising the service independence that MSA aims for in the data synchronization layer. To address this issue, we are considering the introduction of Confluent Schema Registry and Avro format. This is a feature already officially supported in Debezium 3.x, and by applying it, Debezium will automatically register the schema with the Schema Registry along with the events, allowing Data-Sync to interpret it dynamically, enabling each service to change the schema independently of Data-Sync.
◆ Key Changes in Debezium 3.x (2024-2025)
|
Version |
Core changes |
Meaning from an operational perspective |
|---|---|---|
|
3.1 (2025.04) |
Official Release of Management Platform (Kubernetes UI) |
Operation method of directly accessing the Pod via curl → can be replaced with GUI |
|
3.4 (2025.12) |
PostgreSQL 17 Failover Slot · PG 18 Support · Kafka 4.1 · OpenLineage Integration |
Automatic Slot Migration during DB Failover · Monitoring pg_replication_slots is Essential |
|
AI integration |
Add LLM·vector DB linked AI module (Debezium Server Sink) |
CDC is evolving from a data replication tool to an AI pipeline layer |
|
The greatest advantage of this approach was that it allowed for controlling data flow without touching legacy systems. I think this is an approach that can be applied in various contexts, not only in situations where two systems must coexist like in MSA transitions, I hope this project will be of some help to those who are encountering CDC for the first time or those who are contemplating similar data |
|---|
References
[1] Debezium official documentation, debezium.io/documentation/reference/3.4
[2] Debezium 3.1~3.4 Release Notes, debezium.io/blog
[3] Confluent Schema Registry, docs.confluent.io/platform/current/schema-registry
Juno