1. Введение
В системах мониторинга в реальном времени часто требуется синхронизировать метаданные вычислительных формул между несколькими службами. В этом проекте также была необходима возможность отправки событий при создании или изменении формул, чтобы передавать изменения другим службам.
В начальной реализации использовалась ConcurrentHashMap и его метод putIfAbsent() для предотвращения дублирования одной и той же вычислительной формулы. Я реализовал функцию, которая публикует событие передачи формулы только в том случае, если условие с putIfAbsent() прошло. Я полагал, что достаточно обработать только первую регистрацию, так как формулы обычно не изменяются после первоначального создания.
Однако в процессе рассмотрения различных сценариев эксплуатации была обнаружена неожиданная проблема. Некоторые формулы могли изменяться не только в зависимости от изначально заданных значений, но и в зависимости от доступной конфигурации сенсорных сигналов, и старая структура не могла обнаружить такие изменения.
Например, определенная формула создается следующим образом, если присутствует только сигнал A.
Value = A + 1.01Но в процессе эксплуатации формула может измениться следующим образом в зависимости от значения сигналов B true/false.
Value = A - 1.01То есть, даже если формулы одинаковые, они могут отличаться в зависимости от доступной конфигурации сигналов.
Проблема в том, что putIfAbsent()не выполняет никаких действий для уже зарегистрированного key. Следовательно, даже если формула изменится, предыдущее значение останется прежним, и событие изменения также не будет выпущено.
В результате другие сервисы не смогут получить последнюю формулу, и может возникнуть несоответствие метаданных между сервисами.
В этой статье я хотел бы изложить причины выбора putIfAbsent()на этапе начального проектирования, его ограничения, а также процесс улучшения, в котором используются replace()для одновременной обработки обнаружения изменений и синхронизации событий.
2. Начальное проектирование - предотвращение дублирования с использованием putIfAbsent()
Прежде чем приступить к проектированию, я проверил формулы, используемые в проекте. При начальном проектировании, изучая формулы, я заметил, что все они были формулами, основанными на начальных значениях. Также я пришел к выводу, что такая формула, как только она будет создана, не изменится в процессе работы, если начальные значения не изменятся. Поэтому я думал, что формулу нужно сохранять только один раз.
Я разработал структуру, в которой формула хранится в памяти в момент её первого создания и одновременно выпускается событие для передачи информации о формуле другим сервисам.
Кроме того, эта функция должна была работать в среде, где к ней одновременно могут получить доступ несколько потоков, поэтому она использовала кеш для хранения информации о формуле.ConcurrentHashMapбыл использован. Первоначальная реализация была очень простой.

putIfAbsent()сохраняет значение только в том случае, если указанный Keyне существует, и возвращает существующее значение, если оно уже есть. Таким образом, события могли быть опубликованы только в случае создания первоначальной формулы, что также естественно предотвратило дублирование событий для одной и той же формулы.
Тогда считалось, что формула, однажды созданная, не изменится. Это было так, потому что начальные значения были фиксированными и редко менялись. Даже если они и изменялись, я думал, что, перезапустив сервис для сброса памяти, можно снова создать новую формулу.
3. Проблема, обнаруженная в процессе пересмотра требований к новой формуле
После завершения первоначальной реализации я присутствовал на совещании по пересмотру требований к другим функциям формул. Эта функция была отдельной от текущей разработки, но в процессе пересмотра требований я обнаружил аспект, который мог повлиять на существующий проект.
Некоторые формулы, обсужденные на совещании, могли не просто использовать стартовые значения, но и изменяться в зависимости от наличия сенсорных сигналов или значений сигналов.
Например, если сигнал конкретного датчика отсутствует, расчет проводится только с использованием A, но как только этот датчик начинает нормально собирать данные, формула должна измениться на использующую и A, и B. Либо формула должна была изменяться в зависимости от того, является ли значение сигнала B истинным или ложным.
Пересматривая эти требования, я снова взглянул на текущую реализацию, основанную на putIfAbsent(). И я обнаружил, что в существующей структуре невозможно обнаружить изменения уже созданной формулы.
4. Переопределение требований для обнаружения изменений формулы
Существующая структура удовлетворяла только требованию публикации события при первоначальном создании расчетных выражений. Однако, чтобы соответствовать новым требованиям, этого было недостаточно. Если расчетное выражение может изменяться, нужно было уметь обнаруживать не только первоначальное создание, но и изменения.
В результате стало ясно, что нужна новая структура, удовлетворяющая следующим условиям.
1. Публикация события при первоначальном создании расчетного выражения
2. Публикация события при изменении расчетного выражения
3. Не публиковать событие, если расчетное выражение одинаковое
4. Безопасная работа в многопоточной среде
putIfAbsent()могла обрабатывать только первоначальное создание. Для уже зарегистрированного Keyнельзя было проверить или обнаружить изменения, если поступало новое расчетное выражение. Поэтому необходима была отдельная структура для обнаружения изменений расчетного выражения.
5. Обнаружение изменений с использованием replace() из ConcurrentHashMap
Изначально рассматривался простой способ определения изменений путем запроса существующего значения и его сравнения.

Однако этот подход был небезопасен в многопоточной среде. Например, если два потока одновременно попытаются изменить одну и ту же информацию о расчетном выражении, оба потока могут, запросив существующее значение, определить, что оно изменилось. В этом случае существует вероятность дублирования публикации события для одного и того же изменения расчетного выражения.
Поэтому, для решения этой проблемы ConcurrentHashMapпредоставляемый replace() методом.

replace(key, oldValue, newValue)является текущим Mapсохранённым значением oldValueи только в случае их newValueзаменит. То есть, работает следующим образом:
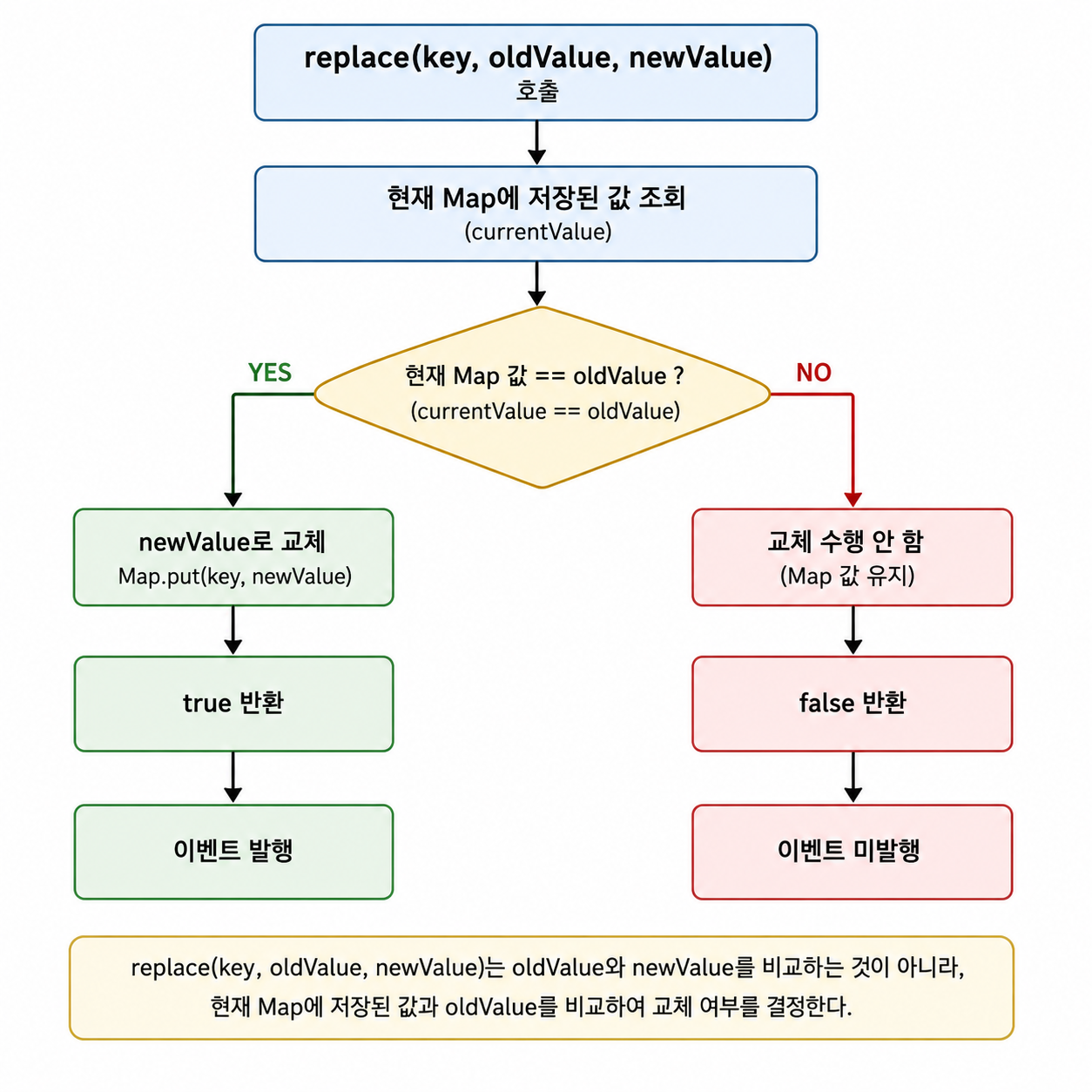
если другой поток уже изменил значение, то текущее Mapзначение уже oldValueне будет. В этом случае replace()возвращает falseи замена значения не выполняется. Таким образом, только потоки, которые фактически успешно изменили формулу, могут вызывать события. В конечном итоге replace()используется для определения того, было ли событие вызвано.
Это позволило вызывать события только в случае изменения формулы и одновременно предотвратить проблему дублирования событий, которая может возникнуть в многопоточной среде.
6. В заключение
При разработке этой функции изначально я сосредоточился лишь на предотвращении дублирования создания формул. Только по начальным требованиям структура, основанная на putIfAbsent()казалась достаточной. На самом деле это эффективно предотвратило дублирование хранения и дублирование вызовов событий для одной и той же формулы.
Однако, рассматривая новые требования к формуле, я обнаружил возможность изменения формулы в процессе эксплуатации и подтвердил, что существующий дизайн не может обработать такую ситуацию. Для решения этой проблемы была улучшена структура, чтобы она могла обнаруживать не только первоначальное создание формулы, но и изменения, а также ConcurrentHashMapнаreplace()был реализован с использованием для безопасной работы в многопоточной среде.
В этом опыте я снова ощутил важность не только удовлетворения текущих требований, но и учета возможных сценариев, которые могут возникнуть в будущем. Также я узнал, что процесс не ограничивается лишь реализацией функций, а включает в себя рассмотрение различных сценариев и обнаружение ограничений дизайна для их улучшения, что также является важной частью разработки.
Yang