1. Введение
Проблема, с которой я столкнулся, участвуя в проекте перехода медицинской системы на MSA, заключалась в дублировании данных. Новая система MSA (PostgreSQL) и существующая устаревшая система (Oracle) должны были работать параллельно, и существовали требования по поддержанию согласованности данных в реальном времени в условиях, когда обе системы находились в эксплуатации.
Синхронизация этапов вызвала задержку в десятки минут, что сделало ее неприемлемой для медицинской области, а метод триггеров БД добавил нагрузку на устаревший Oracle, в то время как двойная запись приложений затрудняла обеспечение атомарности транзакций. После рассмотрения нескольких методов было решено принять подход CDC (Change Data Capture), который подразумевает непосредственное чтение журналов транзакций из исходной БД для асинхронной передачи.
2. Архитектура: Debezium и пользовательское приложение синхронизации
Debezium - это платформа открытого исходного кода CDC, которая напрямую подписывается на WAL (журнал подготовки записей) PostgreSQL и в реальном времени публикует события INSERT/UPDATE/DELETE в Kafka. Поскольку она читает только WAL-журнал без триггеров или изменений кода в исходной БД, это позволило не затрагивать устаревшие системы, и даже если коннектор перезапускается, он может продолжить с последней обработанной позиции журнала (LSN), что хорошо соответствует требованиям этого проекта.
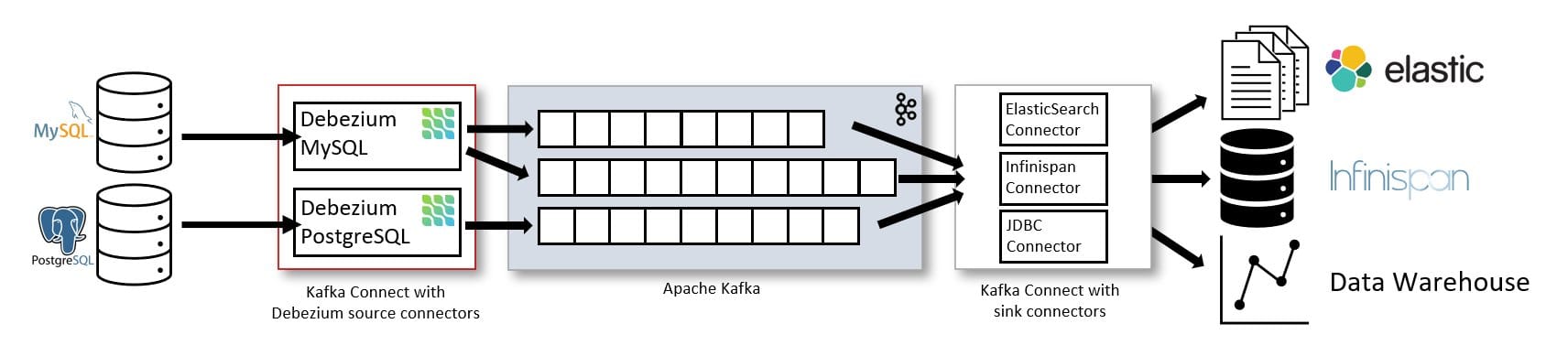
[Рисунок 1] Официальная архитектура Debezium — источник: debezium.io/documentation/reference/3.5 (Лицензия Apache 2.0)
|
Категория |
Технология |
Роль |
|---|---|---|
|
Source DB |
PostgreSQL |
Источник изменений данных (CDC на основе WAL) |
|
Движок CDC |
Debezium 3.x |
Обнаружение WAL → Публикация событий Kafka |
|
Событийная шина |
Apache Kafka |
гарантия доставки не реже одного раза (возможна дублирующая отправка → необходима идемпотентная обработка на стороне потребителя) |
|
Приложение для синхронизации |
Data-Sync (Spring Boot) |
Потребление событий, отражение Oracle, сохранение хешей согласованности |
|
Целевая БД |
Oracle |
Целевая финальная синхронизация наследственной системы |
Существовали три основные причины, по которым мы решили разработать собственное приложение Spring Boot (Data-Sync) вместо использования стандартного Sink Connector.
Преобразование схемы - Сложные PK, нестандартные имена колонок и преобразование типов (timestamptz → TIMESTAMP WITH LOCAL TIME ZONE и др.) в устаревшем Oracle было трудно обеспечить только с помощью стандартных настроек Connector.
Обработка ошибок - Нужно было различать период повторных попыток и способы уведомления в зависимости от типа ошибки, и для этого требовалась гибкость пользовательского кода.
Проверка согласованности - После завершения синхронизации также была необходимость периодически проверять согласованность данных между двумя системами, асинхронно сохраняя их хеши.
3. Проверка надежности: тестирование на устойчивость к сбоям
После завершения проектирования я хотел убедиться, что система не теряет данные даже в ситуации сбоя перед фактическим запуском в эксплуатацию. Мы проводили независимые тесты по сценариям в среде разработки Kubernetes, каждый раз вводя 20 000 записей в PostgreSQL и проверяя, что они загружаются в Oracle без потерь.
|
Сценарий |
Условия инвалидности |
Механизм восстановления |
Результат |
|---|---|---|---|
|
Ошибка ведущего раздела Kafka |
Принудительная остановка лидера брокера во время передачи |
Kafka Controller выбирает другого брокера в ISR в качестве лидера, автоматическое повторное подключение Debezium |
✓ Отсутствие утери |
|
Полный сбой кластера Kafka |
Удаление всех брокеров Pod и повторное развертывание |
Kafka Connect offset topic (с сохранением PVC) и слот репликации PostgreSQL работают вместе, чтобы продолжить с последнего LSN от WAL |
✓ Нет потерь |
|
Ошибка подключения Debezium |
Принудительное завершение работы соединителя во время обработки CDC |
Автоматическое продолжение чтения WAL от последнего LSN, записанного в слоте репликации |
✓ Нет потери |
|
Причиной отсутствия потери данных даже после полного перераспределения кластера Kafka стало совместное функционирование темы смещения Kafka Connect и слота репликации PostgreSQL. Оффсетная тема была возможна благодаря тому, что последнее обработанное положение Kafka и позиция LSN WAL сохранялись в слоте репликации. Однако, из-за свойства at-least-once, при повторной обработке могут возникать дублирующие события, и в результате реализованная на основе UPSERT идемпотентность в Data-Sync в конечном итоге обеспечила согласованность данных. |
|---|
4. Заключение: ограничения и полученные уроки, а также будущее
◆ Ограничения начального проектирования
Способ хранения информации о колонках, необходимой для синхронизации, непосредственно в внутренней таблице метаданных Data-Sync имел явные ограничения. Каждый раз, когда добавляется новая колонка в определенный сервис, структура требует изменений и в Data-Sync, из-за чего независимость сервисов, к которой стремится MSA, нарушается на уровне синхронизации данных. Для решения этой проблемы мы рассматриваем внедрение Confluent Schema Registry и формата Avro. Это функция, которая уже официально поддерживается в Debezium 3.x, и ее применение позволит Debezium автоматически регистрировать схемы в Schema Registry вместе с событиями, обеспечивая динамическую интерпретацию Data-Sync и позволяя каждому сервису независимо изменять схемы с Data-Sync.
◆ Основные изменения Debezium 3.x (2024~2025)
|
Версия |
Ключевые изменения |
Значение с точки зрения эксплуатации |
|---|---|---|
|
3.1 (2025.04) |
Официальный релиз платформы управления (Kubernetes UI) |
операционная система, использующая прямое подключение к Pod через curl → может быть заменена на GUI |
|
3.4 (2025.12) |
Слот переключения PostgreSQL 17 · Поддержка PG 18 · Kafka 4.1 · Интеграция OpenLineage |
Автоматический перенос слота при переключении базы данных · Обязательно мониторинг pg_replication_slots |
|
Интеграция ИИ |
Добавление модуля ИИ с интеграцией LLM и векторной базы данных (Debezium Server Sink) |
CDC продолжает развиваться от инструмента репликации данных к слою AI-пайплайна |
|
Наибольшим преимуществом этого подхода было то, что он позволяет контролировать поток данных, не затрагивая устаревшие системы. Я думаю, что это подход, который можно применить не только в ситуациях, когда два системы должны сосуществовать, как при переходе на MSA, но и в различных контекстах, таких как обновление кеша, индексация поиска, архитектура на основе событий. Надеюсь, этот проект будет полезен для тех, кто впервые сталкивается с CDC, или для тех, кто решает аналогичные проблемы синхронизации данных. |
|---|
Список литературы
[1] Официальная документация Debezium, debezium.io/documentation/reference/3.4
[2] Примечания к релизу Debezium 3.1~3.4, debezium.io/blog
[3] Регистратор схем Confluent, docs.confluent.io/platform/current/schema-registry
Юнона