최근 프로젝트에서 외부 시스템으로부터 유입되는 대용량 데이터를 시스템 내부 마스터 테이블로 안전하고 빠르게 이관(Migration)해야 하는 과제를 수행했습니다. 이 과정에서 마주한 기술적 한계와 이를 PostgreSQL의 Stored Procedure(저장 프로시저) 및 최적화 기법을 통해 어떻게 해결했는지, 상세한 아키텍처와 구현 코드를 바탕으로 공유해보고자 합니다.
-
기존 애플리케이션(Java/Spring) 레벨 배치 처리의 한계
초기 설계 단계에서는 익숙한 Java와 Spring Boot 환경에서 배치를 구현하는 방법을 가장 먼저 검토했습니다. Spring Batch 등을 활용해 Chunk 단위로 데이터를 쪼개어 가공하는 방식이 대중적이기 때문입니다. 하지만 아키텍처를 검토할수록 다음과 같은 명확한 한계점이 드러났습니다.
1-1. 심각한 네트워크 오버헤드 (Network Overhead)
외부 시스템에서 유입된 수만 건, 수천만 건의 데이터를 조회하고 기존 데이터와 비교·대조하는 과정에서 WAS(Web Application Server)와 DB 간의 잦은 네트워크 통신(Round-Trip)이 발생했습니다. 네트워크 대역폭 소모는 물론, 레이턴시(Latency)로 인한 전체 작업 시간 지연이 예상되었습니다.
1-2. WAS 메모리 부담 및 OOM(Out Of Memory) 위험
대량의 엔티티(Entity)나 DTO를 Java 메모리(Heap)에 한꺼번에 올릴 경우 가비지 컬렉션(GC)의 부하가 급증하며, 순간적으로 java.lang.OutOfMemoryError가 발생해 애플리케이션 전체가 다운될 리스크가 존재했습니다.
1-3. 애플리케이션 연산의 한계
데이터의 Row 단위마다 복잡한 비즈니스 로직(비교, 검증, 매핑)을 애플리케이션 루프(Loop) 내에서 수행하다 보니, DB 내부의 인덱스나 연산 엔진을 최대로 활용하지 못해 마이그레이션 성능이 급격히 저하되었습니다.
[선택한 해결책: PostgreSQL Stored Procedure]
이러한 한계를 극복하기 위해, 우리는 "데이터가 존재하는 공간(DB) 내부에서 로직을 직접 처리하자"는 결론에 도달했습니다. PostgreSQL 11 버전부터 지원하기 시작한 Stored Procedure는 기존 Function(함수)과 달리 내부에서 명시적인 트랜잭션 제어(COMMIT, ROLLBACK)가 가능합니다. 이를 통해 대용량 배치 작업 도중 커밋을 나누어 실행함으로써 DB 리소스(Undo, Lock 등)의 압박을 최소화하고 데이터 정합성을 확보할 수 있는 최적의 솔루션으로 채택되었습니다.
|
비교 항목 |
WAS 레벨 처리(Java/Spring) |
DB 레벨 처리(PostgreSQL Procedure) |
|---|---|---|
|
데이터 이동 |
DB → WAS → DB(대량 이동) |
DB 내부에서 완결(이동 최소화) |
|
네트워크 부하 |
매우 높음(Row별 쿼리 혹은 대량 전송) |
매우 낮음(프로시저 호출 및 결과 수신) |
|
메모리 관리 |
WAS 힙 메모리 압박(OOM위험) |
DB 버퍼 풀 및 공유 메모리 최적화 활용 |
|
트랜잭션 제어 |
Spring @Transactional 또는 배치 트랜잭션 |
프로시저 내 개별 단계별 명시적 COMMIT 제어 |
-
시스템 아키텍처 및 데이터 흐름
전체적인 데이터 파이프라인은 2단계 구조로 설계되었습니다.
2-1. Staging 단계
외부 시스템의 로우(Raw) 데이터를 중간 임시 적재 테이블(staging_table)에 벌크 로딩합니다.
2-2. Migration 단계
Java 애플리케이션이 파라미터와 함께 PostgreSQL 프로시저를 호출하면, DB 내부에서 staging_table과 target_table을 비교·분석하여 최종 마스터 테이블에 가공 및 반영(Upsert/Update/Insert)을 수행합니다.
-
적용 과정
구현은 데이터를 가공하여 반영하는 PostgreSQL 프로시저와, 이를 호출하고 처리 결과 건수를 받아오는 Java 애플리케이션 코드로 구성됩니다. 이해를 돕기 위해 복잡한 비즈니스 컬럼은 간소화된 예시 데이터로 대체했습니다.
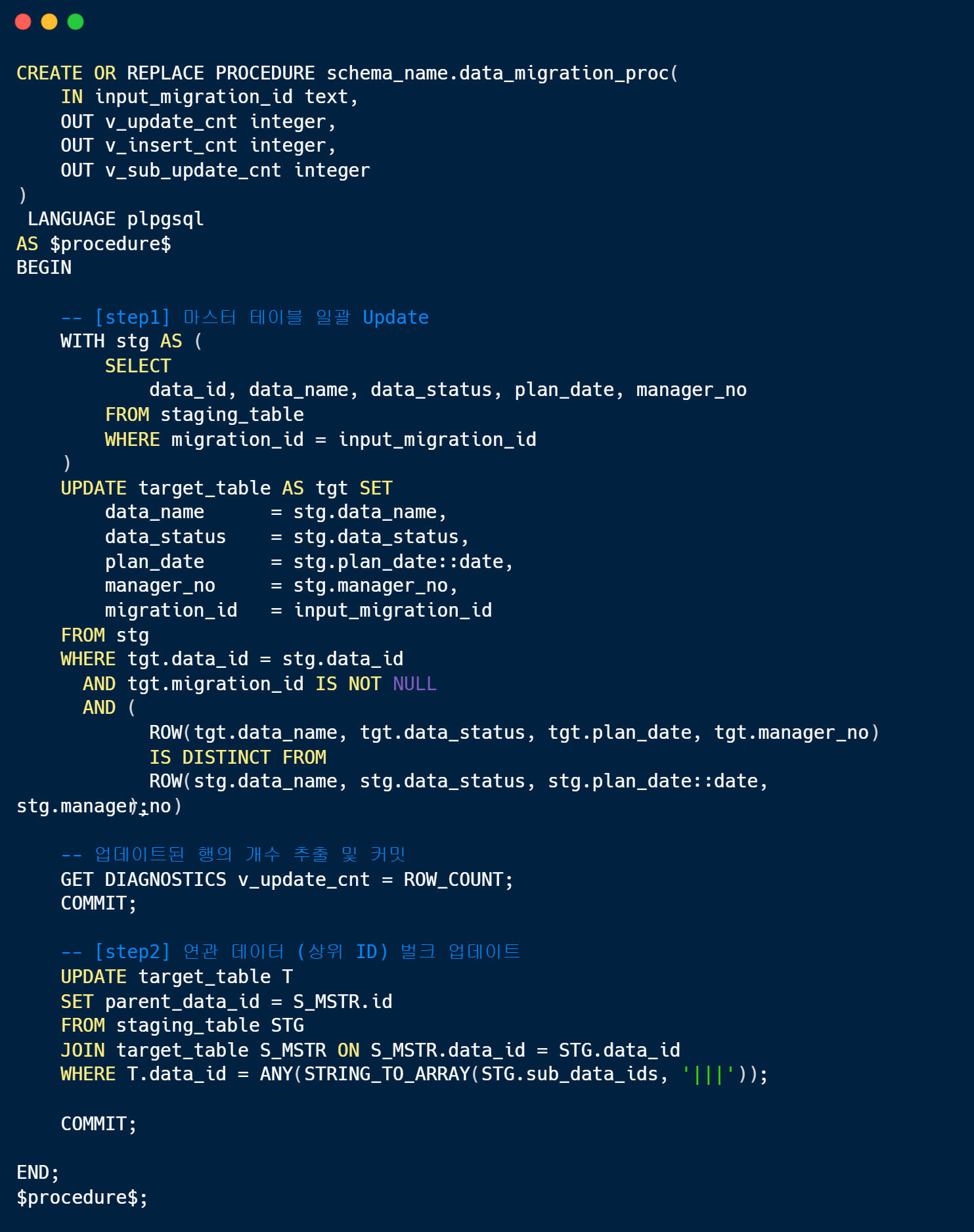
3-1. PostgreSQL Procedure 구현
임시 적재 테이블(staging_table)의 데이터를 기반으로 타겟 테이블(target_table)을 업데이트하는 로직입니다. WITH 절(CTE)과 IS DISTINCT FROM 구문을 활용해 변경 사항이 있는 데이터만 선별하여 Bulk Update를 수행합니다.
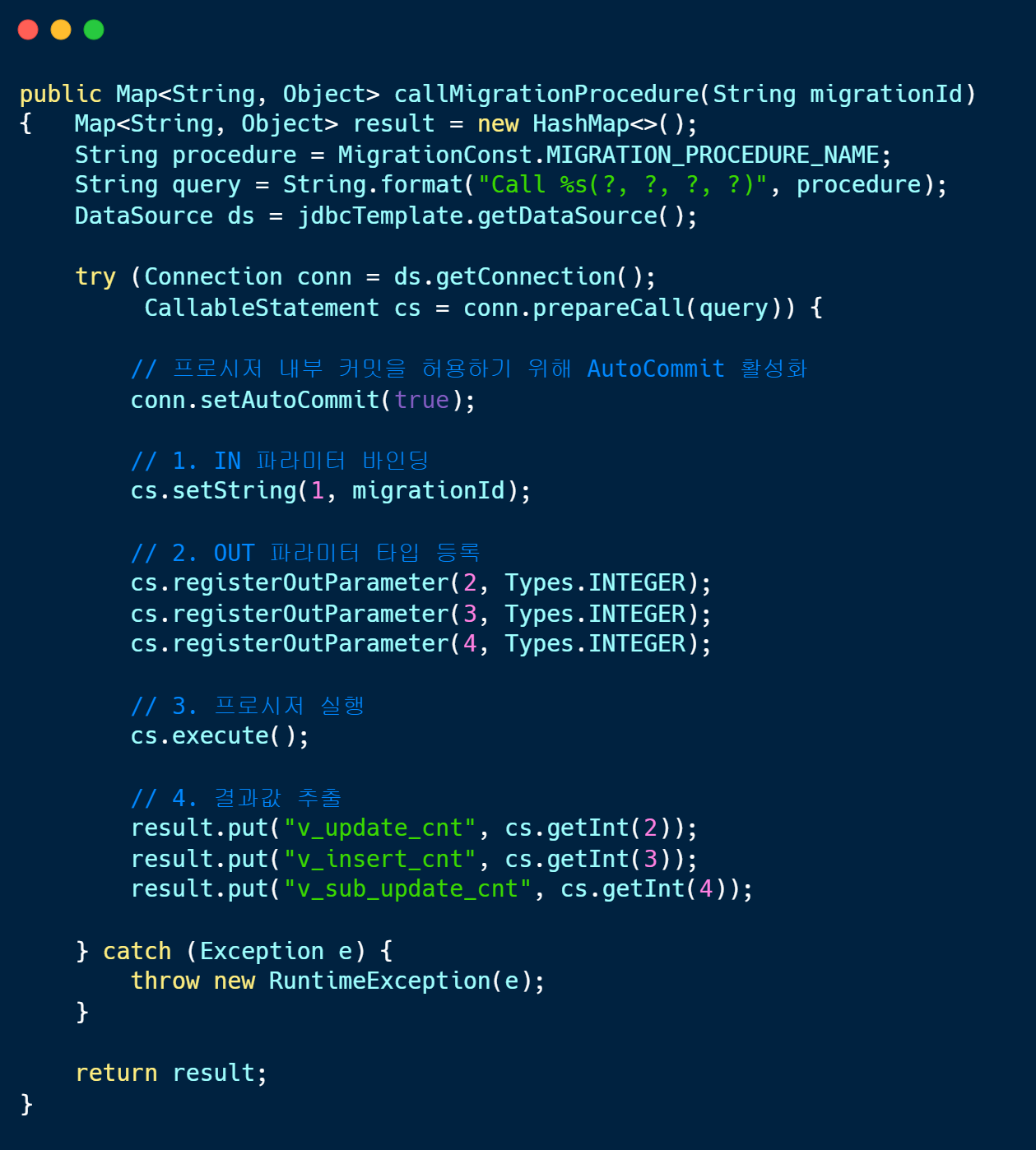
3-2. Java (Spring) 호출 코드 구현
프로시저를 호출하기 위해 JdbcTemplate 기반의 CallableStatement를 사용했습니다. IN 파라미터를 전달하고, 프로시저 내부에서 계산된 결과(처리 건수)들을 OUT 파라미터로 안전하게 반환받아 Map 객체로 변환합니다.
-
문제 해결 경험
4-1. 불필요한 Update 방지: IS DISTINCT FROM 활용
-
문제 상황: 대량의 데이터를 매번 무조건 UPDATE 쿼리로 밀어 넣는 경우, 변경사항이 없는 레코드까지 쓰기 작업이 발생하여 불필요한 WAL(Write-Ahead Log) 누적 및 인덱스 성능 저하가 발생했습니다.
-
해결 방법: PostgreSQL의 ROW() IS DISTINCT FROM ROW() 구문을 적용했습니다. 이 방식은 NULL 값 비교 시 발생하는 예외적인 상황(예: NULL = NULL은 False)까지 방지하며, 대상 필드들이 하나라도 다를 때만 업데이트를 수행하도록 필터링해 성능을 향상시켰습니다.
4-2. 프로시저 내 명시적 COMMIT 제어
-
문제 상황: 대용량 마이그레이션 도중 에러가 나면 복구 리스크가 컸고, 하나의 거대한 트랜잭션으로 묶을 경우 DB 리소스 압박이 심했습니다.
-
해결 방법: PostgreSQL Function 대신 Procedure를 채택한 핵심 이유입니다. 각 비즈니스 단계가 끝날 때마다 프로시저 내부에 COMMIT; 명령을 명시하여 시스템 리소스를 적절히 해제하고 단계별 데이터 정합성을 보장했습니다. Java 단에서도 conn.setAutoCommit(true) 설정을 통해 프로시저 내부의 커밋 제어권을 유지해 주었습니다.
-
성과 및 결론
Stored Procedure 중심의 아키텍처로 전환한 결과, 마이그레이션 성능 지표에서 놀라운 개선 효과를 거두었습니다.
5-1. 처리 속도 개선
기존 Java 애플리케이션 단에서 `Loop + Bulk Insert` 형태로 구동했을 때 대비 전체 마이그레이션 수행 시간이 단축되었습니다.
5-2. 자원 최적화
인프라 비용 측면에서 WAS의 CPU/Memory 점유율이 안정화되었으며, DB 내부에서도 효율적인 인덱스 스캔과 최소화된 튜플 관리 덕분에 디스크 I/O가 안정적인 우하향 곡선을 그렸습니다.
PYS