"OCR 하나만 붙이면 끝나겠지"라고 생각했던 순간부터 실제 문제 해결은 시작됐습니다.
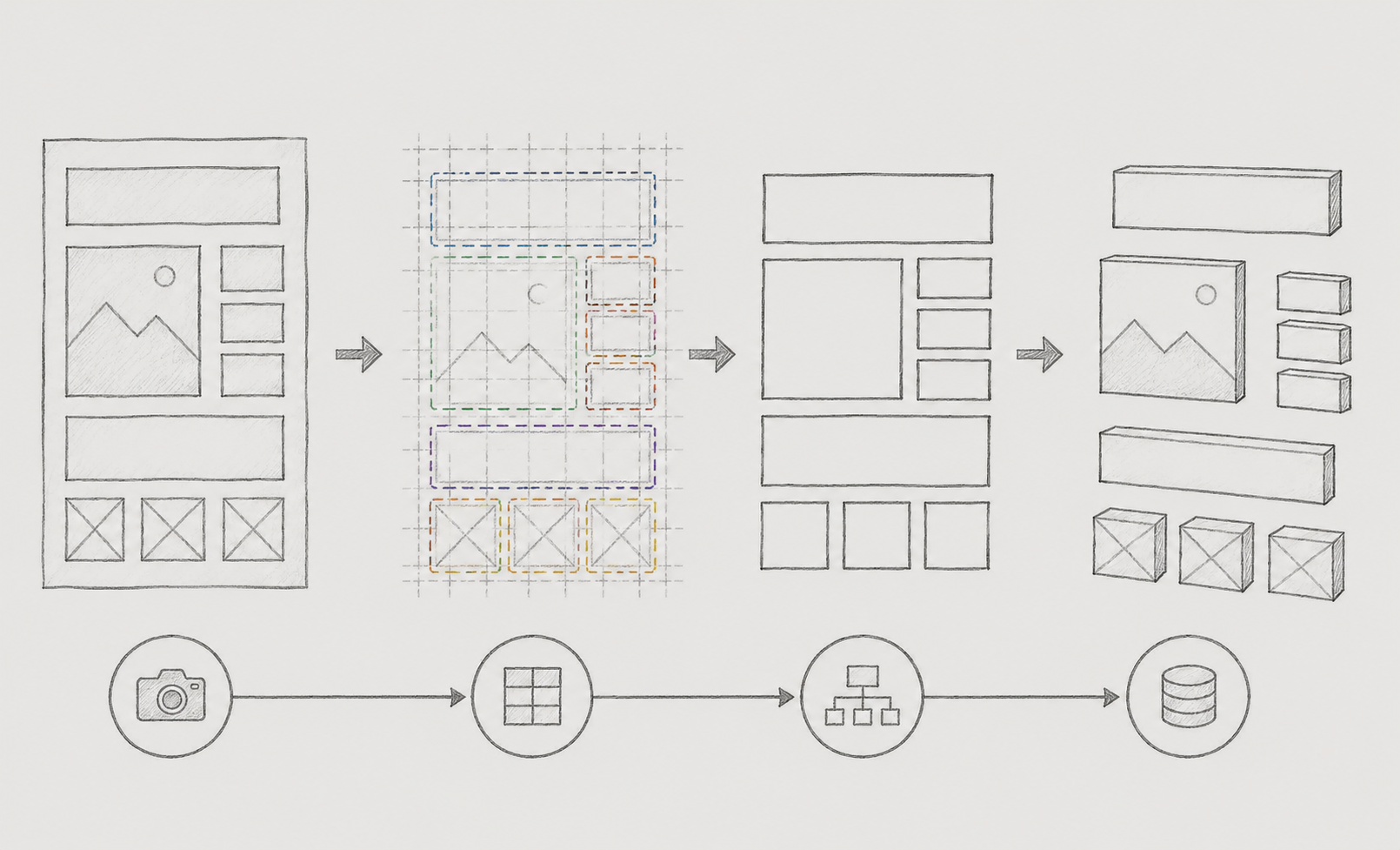
비정형 문서를 구조화하는 파이프라인을 사전 검증하기 위해 테스트 케이스로 수학 문제 PDF를 선택했습니다. 문제 영역과 번호가 명확히 구분되어 있으면서도, 1단·2단 레이아웃이 혼재된 구조를 가지고 있어 레이아웃 분석과 의미 매핑을 동시에 검증하기에 적합한 데이터였기 때문입니다.
하지만 실제 데이터는 예상보다 훨씬 복잡했습니다. 문항 번호와 본문이 픽셀 단위로 밀착되어 있었고, 페이지마다 레이아웃 구조도 달랐습니다. 결국 단순 OCR만으로는 문항 구조를 안정적으로 복원할 수 없다는 사실을 빠르게 확인할 수 있었습니다.
이 글에서는 이러한 문제를 해결하기 위해 Vision 탐지 → 좌표 정렬 → 매핑 → OCR로 이어지는 4단계 파이프라인을 설계하고, 실패를 반복하며 개선해 나간 과정을 정리했습니다.
1. 기술 선택 배경 — 왜 Vision 탐지가 먼저여야 했나
수학 문제 PDF를 구조화하는 과정에서 처음에는 OCR을 먼저 적용하는 접근 방식을 선택했습니다. 당시에는 OCR의 인식률만 충분히 높다면 문항 구조도 자연스럽게 복원될 것이라고 생각했습니다.
하지만 실제 테스트에서는 예상과 전혀 다른 문제가 발생했습니다. 특히 2단 레이아웃이 섞인 문서에서는 OCR이 문서를 사람이 읽는 순서대로 인식하지 못했습니다. 좌측 컬럼과 우측 컬럼의 문항 순서가 뒤섞였고, 문항 번호가 본문 일부와 합쳐져 잘못 인식되는 경우도 반복적으로 발생했습니다.
예를 들어 OCR 결과상으로는 12번 문제 다음에 3번 문제가 등장하거나, 문제 번호가 수식 일부로 잘못 해석되는 사례도 확인할 수 있었습니다.
결국 느낀 점은 OCR은 "글자를 읽는 기술"이지, "문서 구조를 이해하는 기술"은 아니라는 점이었습니다. 즉, 문서 구조를 먼저 안정적으로 정리하지 않으면 OCR 인식률이 아무리 높아도 실제 결과를 그대로 사용할 수 없었습니다.
이후 접근 방향을 완전히 변경했습니다. 우선 문서 구조 자체를 먼저 탐지하고, OCR은 각 영역 내부 텍스트를 읽는 역할만 수행하도록 파이프라인을 재설계했습니다.
특히 다음과 같은 기준을 우선적으로 고려했습니다.
-
레이아웃이 1단이든 2단이든 문항 순서를 안정적으로 복원할 것
-
일부 OCR 실패가 발생하더라도 전체 배치 흐름이 중단되지 않을 것
-
향후 웹 UI 레이아웃 분석 등 다른 도메인에도 확장 가능한 구조일 것
결과적으로 OCR 중심 접근에서 Vision 기반 구조 분석 중심 접근으로 방향을 전환하게 됐습니다.
2. 적용 아키텍처 및 구현 과정
전체 파이프라인은 크게 4개의 단계로 분리하여 설계했습니다. 가장 중요하게 생각한 부분은 각 단계 간 결합도를 낮추는 것이었습니다. 특정 모듈을 교체하거나 수정하더라도 전체 흐름에는 영향을 최소화할 수 있도록 독립적인 구조를 유지하고자 했습니다.
또한 단계별 테스트가 가능하도록 구성하여, 문제 발생 시 어느 단계에서 오류가 발생했는지 빠르게 추적할 수 있도록 설계했습니다.
2.1 데이터 구축 및 YOLOv8 학습
객체 탐지 모델로는 Ultralytics의 YOLOv8을 선택했습니다. 실시간 추론에서도 충분한 mAP를 확보할 수 있는 구조를 가지고 있었고, Ultralytics 생태계를 그대로 활용할 수 있어 모델 학습 · 추론 · 검증 흐름을 비교적 빠르게 구축할 수 있다는 점이 장점이었습니다.
클래스는 problem 박스(문항 영역)와 number 박스(번호 영역) 두 가지로 정의했습니다. 두 영역은 의미적 단위가 명확하게 다르고, 이후 매핑 단계에서 1:1로 연결하기 위해서는 분리 학습이 필수적이었기 때문입니다. 이후부터는 두 영역을 각각 problem 박스, number 박스로 표기합니다.
하지만 실제 프로젝트에서 가장 많은 시간을 사용한 부분은 모델 자체보다 라벨링 규칙 정리 작업이었습니다. problem 영역과 number 영역을 명확하게 분리해야 했고, 경계가 겹치는 경우에는 항상 동일한 기준으로 라벨링해야 했습니다.
실제 학습 과정에서는 라벨링 기준이 조금만 흔들려도 모델이 의도와 다른 방향으로 학습되는 현상이 반복적으로 발생했습니다. 예를 들어 어떤 데이터에서는 문항 번호를 포함하여 넓게 박스를 잡고, 다른 데이터에서는 번호만 타이트하게 박스를 잡으면 모델이 일관된 특징을 학습하지 못했습니다.
결국 모델 성능보다 더 중요한 것은 "일관된 데이터 정의"라는 점을 다시 한번 확인할 수 있었습니다.
2.2 OCR 전처리 — 2배 업스케일과 이진화
Vision 탐지가 끝나고 number 박스를 잘라낸 뒤에는, OCR이 안정적으로 숫자를 읽을 수 있도록 전처리를 거치게 했습니다. 처음에는 원본 해상도 그대로 Tesseract에 넘겼는데, 작은 문항 번호의 인식률이 기대보다 낮게 나왔습니다.
개선을 위해 잘라낸 영역을 정수 배수로 nearest-neighbor 업스케일한 뒤, 그레이스케일 변환과 이진화(Otsu)를 적용하는 방식을 시도했습니다. 배수를 2배/3배 등으로 바꿔가며 비교했을 때, 본 도메인 데이터에서는 2배가 가장 안정적이었습니다.
배수를 더 키우자 오히려 인식이 불안정해졌습니다. 보간 알고리즘을 nearest로 고정해도 픽셀 단위 노이즈가 같이 확대됐고, Tesseract의 내부 정규화 가정과 어긋나면서 작은 숫자의 윤곽이 오히려 흐려졌기 때문이라고 판단했습니다.
또한 PSM(Page Segmentation Mode)을 단일 값으로 고정하지 않고, 단일 블록(PSM 6) 우선 → 실패 시 단일 라인(PSM 7)으로 재시도하는 방식으로 구성했습니다. number 박스는 글자 수가 1~3자로 짧기 때문에, PSM에 따라 결과 편차가 컸기 때문입니다.
이 과정에서 얻은 가장 중요한 교훈은 "입력 데이터 특성과 모델 · 엔진 설정이 서로 일관되게 맞아야 실제 성능 개선 효과를 얻을 수 있다"는 점이었습니다. 단순히 해상도를 키우거나 모드를 바꾸는 것만으로는 인식률이 올라가지 않았습니다.
2.3 좌표 기반 레이아웃 복원 및 매칭 스코어 설계
탐지된 박스를 기준으로 실제 문서 읽기 순서를 복원하기 위한 좌표 정렬 로직을 구현했습니다. 우선 페이지 폭의 x축 중간값(image_width × 0.5)을 기준으로 problem 박스를 좌측 컬럼과 우측 컬럼으로 분리했습니다. 이후 각 컬럼 내부에서는 y축 → x축 순으로 정렬해 실제 사람의 읽기 흐름과 유사한 순서를 구성했습니다.
이 과정을 통해 1단·2단 레이아웃이 혼재된 문서에서도 비교적 안정적으로 문항 순서를 복원할 수 있었습니다.
이후 problem 박스와 number 박스의 연결은 단순 유클리디안 거리 대신, 도메인 특성을 반영한 정규화 가중 점수를 사용했습니다. 수학 문제 레이아웃에서는 문항 번호가 본문의 좌상단에 거의 일정한 거리로 붙어 있다는 특징이 있어, 좌우(x) 정렬이 상하(y) 정렬보다 더 신뢰 가능한 신호였기 때문입니다.
score = 0.55 × (|nx − px| / p_width) + 0.35 × (|ny − py| / p_height) + 0.10 × (1 − y_overlap_ratio)
+ size_penalty # size_penalty = max(0, (n_area / p_area) − 0.08) × 3.0수식에 등장하는 각 변수는 다음과 같습니다.
-
px, py : problem 박스의 좌상단 좌표 (기준점)
-
nx, ny : 매칭 후보 number 박스의 좌상단 좌표
-
p_width, p_height : problem 박스의 가로 · 세로 크기. 거리값을 problem 박스 크기로 정규화하기 위해 사용
-
y_overlap_ratio : problem 박스와 number 박스가 y축으로 겹치는 비율 (0 ~ 1)
-
p_area, n_area : problem · number 박스의 면적. size_penalty 계산용
스코어가 낮을수록 더 좋은 매칭 후보이며, 각 problem 박스마다 가장 점수가 낮은 number 박스를 선택해 1:1로 연결했습니다. 핵심 설계 의도는 다음과 같습니다.
-
dx와 dy를 problem 박스의 가로 · 세로로 각각 정규화하여, 박스 크기가 달라도 비교가 가능하도록 만들었습니다.
-
문항 번호는 본문 좌상단에 정렬되는 경향이 강하기 때문에, x축 차이에 더 높은 가중치(0.55)를 두어 좌우 정렬을 우선시했습니다.
-
y_overlap_ratio를 함께 반영하여, 가까운 거리에 있어도 세로로 전혀 걸쳐 있지 않은 박스는 매칭 후보에서 자연스럽게 멀어지게 했습니다.
-
number 박스가 비정상적으로 클 경우(problem 박스 면적의 8%를 넘는 경우) size_penalty를 부여하여, 큰 박스가 잘못 매칭되는 케이스를 억제했습니다.
결과적으로 단순 유클리디안 거리를 사용했을 때보다, 두 줄에 걸쳐 있는 문항이나 인접한 다른 문항의 번호가 더 가깝게 측정되는 케이스를 안정적으로 줄일 수 있었습니다.
또한 OCR 실패 상황에 대한 Fallback 로직도 매우 중요했습니다. 초기 버전에서는 OCR 실패 시 전체 배치를 중단하도록 구현되어 있었지만, 실제 운영 환경에서는 일부 OCR 실패가 전체 처리 중단으로 이어지는 문제가 발생했습니다.
이를 해결하기 위해 OCR이 의미 있는 번호를 추출하지 못한 경우, 페이지 번호와 정렬 순번을 조합한 임시 식별자를 자동 부여하도록 변경했습니다.
if not real_number: real_number = f"{page_num}-{i + 1}" # 예: "3-7"이 방식 덕분에 일부 OCR 실패가 발생하더라도 전체 배치는 중단되지 않았고, 후속 검수 단계로 데이터를 계속 전달할 수 있었습니다. 결과적으로 시스템 복원력 측면에서 매우 큰 개선 효과를 얻을 수 있었습니다.
아래 표는 위에서 설명한 4단계 파이프라인을 한눈에 정리한 것입니다.
|
단계 |
모듈 |
처리 내용 |
비고 |
|---|---|---|---|
|
① |
Detection |
YOLOv8(Ultralytics) — problem · number 박스 탐지, confidence 임계값 필터링 |
독립 교체 가능 |
|
② |
Geo. Sort |
x축 중간값으로 좌 · 우 컬럼 분리 → 컬럼별 y축 정렬 → 왼쪽 → 오른쪽 병합 |
독립 교체 가능 |
|
③ |
Matching |
problem ↔ number 가중 점수 기반 최소 매칭 → 문항 객체 구성 |
독립 교체 가능 |
|
④ |
OCR |
number 박스 crop → 전처리(2배 업스케일 · 그레이스케일 · 이진화) → Tesseract / 실패 시 Fallback 식별자 부여 |
독립 교체 가능 |
3. 적용 결과
아직 정식 벤치마크 데이터셋을 구축하지 않은 단계였기 때문에, 결과는 운영 환경 기준 관측 데이터 중심으로 정리했습니다.
가장 큰 개선 효과는 문항 순서 복원 정확도였습니다. 기존 OCR 중심 구조에서는 문항 순서 오류율이 상당히 높았고, 특히 2단 레이아웃에서 순서가 뒤섞이는 문제가 빈번하게 발생했습니다. 하지만 Vision 기반 레이아웃 분석을 먼저 수행한 이후에는 이러한 오류가 크게 감소했습니다.
또한 OCR 실패 시 전체 배치를 중단하지 않고 Fallback 구조를 통해 계속 처리할 수 있게 되면서 운영 안정성도 크게 향상됐습니다. 특히 수동 후처리 비율이 감소한 점은 실제 운영 효율 측면에서 매우 큰 의미가 있었습니다. 이전에는 레이아웃 혼재 페이지에 대해 사람이 직접 정렬을 수정해야 하는 경우가 많았지만, 적용 이후에는 대부분 자동으로 처리할 수 있었습니다.
|
평가 항목 |
적용 전 |
적용 후 |
비고 |
|---|---|---|---|
|
문항 순서 오류율 |
~23% |
~4% |
운영 관측 기준 |
|
배치 중단 빈도 |
간헐적 중단 |
거의 0건 |
운영 관측 기준 |
|
레이아웃 혼재 처리 |
수동 후처리 필요 |
자동 분류 |
운영 관측 기준 |
|
파이프라인 복원력 |
단일 실패 → 전체 중단 |
Fallback으로 격리 |
운영 관측 기준 |
4. 한계 및 향후 계획
이번 PoC를 통해 기본적인 Vision 기반 문서 구조화 파이프라인은 충분히 검증할 수 있었습니다. 하지만 여전히 개선이 필요한 부분도 명확하게 존재합니다.
대표적으로 3단 이상의 복합 레이아웃 문서나 수식 전용 박스 처리에서는 아직 안정성이 부족한 상태입니다. 특히 수식만 존재하는 영역은 일반 텍스트 영역과 특징이 다르기 때문에 별도 모델 또는 추가 후처리 전략이 필요할 가능성이 높다고 판단하고 있습니다.
또한 매칭 단계의 가중치(0.55 / 0.35 / 0.10)와 size_penalty 임계값(0.08)은 현재 운영 데이터에서 휴리스틱으로 튜닝된 값입니다. 향후 데이터셋이 충분히 축적되면 이 값들을 검증 셋 기반으로 자동 탐색하거나, 학습 기반 매칭 모델로 대체하는 방향도 검토하고 있습니다.
그리고 OCR 결과와 Vision 탐지 결과 간 의미적 연결 관계를 더 정교하게 구성하는 작업도 앞으로 중요한 과제가 될 것으로 보고 있습니다.
향후에는 현재 검증한 구조를 기반으로 웹 UI 레이아웃 분석 및 화면 기능 가이드 자동 생성 영역까지 확장 적용할 예정입니다. 특히 화면 캡처 기반 컴포넌트 탐지와 UI 구조 분석 분야에서도 현재 구조를 상당 부분 재사용할 수 있을 것으로 기대하고 있습니다.
이번 경험을 통해 단순 OCR만으로는 해결하기 어려운 문제들이 실제 운영 환경에는 매우 많다는 점을 직접 체감할 수 있었습니다. 결국 중요한 것은 "텍스트를 읽는 것"이 아니라 "구조를 이해하는 것"이라는 점을 다시 한번 확인할 수 있었던 경험이었습니다.
-
Ultralytics, "YOLOv8 Documentation", https://docs.ultralytics.com
-
Smith, R., "An Overview of the Tesseract OCR Engine", ICDAR, 2007.
-
Otsu, N., "A Threshold Selection Method from Gray-Level Histograms", IEEE Trans. on Systems, Man, and Cybernetics, 1979.
참고 문헌
Junny