JPA @PostLoad를 활용한 개인정보 마스킹 처리 실무 적용기

1. 배경: 분산된 마스킹 로직이 가져온 위기
관리자 화면에서 사용자 정보를 조회할 때 이름, 전화번호, 이메일 등 민감한 개인정보를 마스킹 처리해야 한다는 요구사항을 접수했습니다. DB에는 원본 데이터를 유지하되 화면과 API 응답에서는 비식별 조치가 이루어져야 했습니다.
초기에는 서비스 레이어에서 DTO로 변환할 때마다 마스킹 로직을 삽입하는 방식을 사용했습니다. 하지만 조회 기능이 늘어날수록 다음과 같은 실무적인 한계가 드러났습니다.
- 로직 중복과 누락: 서비스 메서드마다 마스킹 코드가 중복되었습니다. 개발자가 로직을 빠뜨리면 원본 데이터가 노출되는 사고가 발생할 위험이 증가했습니다.
- 유지보수의 어려움: 마스킹 정책(예: 별표 개수 변경)이 바뀔 때마다 프로젝트 전체의 DTO 변환 코드를 찾아 수정해야 했습니다.
- 비즈니스 로직 오염: 핵심 비즈니스 로직 사이에 보안 처리 코드가 섞여 가독성이 크게 저하되었습니다.
2. 해결책: JPA @PostLoad를 통한 보안 정책의 중앙화
중복을 제거하고 보안 구멍을 원천 차단하기 위해 JPA 엔티티 생명주기 콜백 중 @PostLoad를 선택했습니다. 이 기능은 데이터가 DB에서 조회된 후 엔티티 객체로 로드되는 '직후(After)' 시점에 자동으로 실행됩니다.
선정 이유
- 조회 경로 독립성:
findAll()뿐만 아니라 JPQL, QueryDSL 등 JPA를 통한 모든 조회 경로에서 예외 없이 동작합니다. - 선언적 보안: 보안 로직을 엔티티 내부에 캡슐화하여 서비스 레이어는 핵심 비즈니스 로직에만 집중할 수 있습니다.
3. 실무 적용 및 시행착오 해결
3.1 @PostLoad 구현 예시
엔티티 내부에 마스킹 메서드를 정의하고 @PostLoad 어노테이션을 부여하여 자동화했습니다.
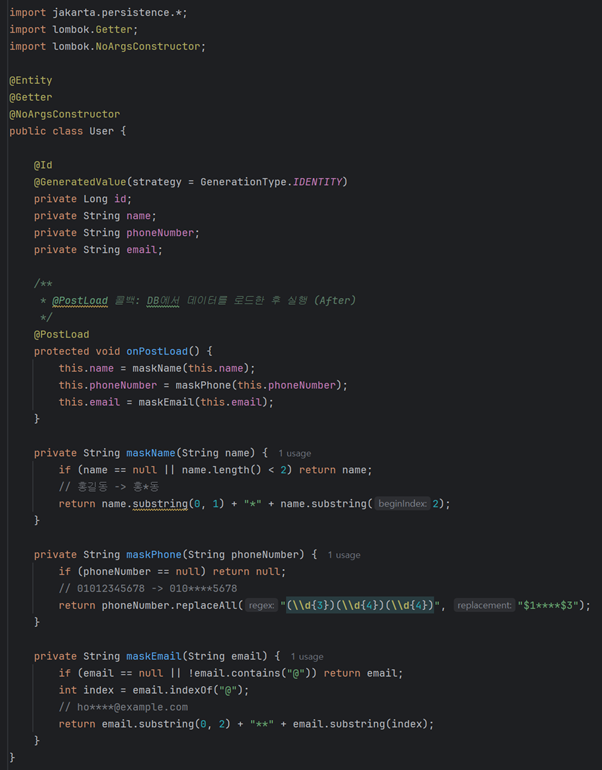
3.2 핵심 이슈: Dirty Checking 방지 전략
적용 과정에서 가장 큰 문제는 변경 감지(Dirty Checking)였습니다. @PostLoad에서 필드 값을 직접 수정하면 JPA는 이를 '수정'으로 간주하여 트랜잭션 종료 시 마스킹된 값을 DB에 덮어쓰려 했습니다. 이를 해결하기 위해 두 가지 전략을 병행했습니다.
- ReadOnly 트랜잭션: 마스킹 조회가 일어나는 서비스에
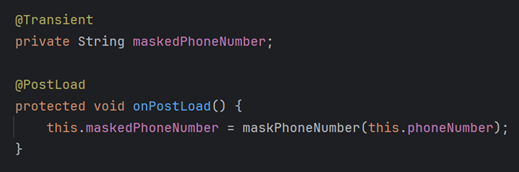
@Transactional(readOnly = true)를 적용해 변경 감지 스냅샷 비교를 차단했습니다. - @Transient 필드 활용(권장): 원본 데이터 오염 우려가 있는 경우에는 원본 필드는 보존하고 마스킹된 값을 담을 가상 필드(
@Transient)를 별도로 두어 안전하게 처리했습니다.
4. 적용 결과: 개발 효율과 보안성 향상
@PostLoad 기반의 마스킹 전략을 도입하고 나서 팀 내 개발 환경에 다음과 같은 뚜렷한 변화가 있었습니다.
- 보안 안정성 확보: 신규 API를 추가할 때 개발자가 마스킹 로직을 신경 쓰지 않아도 시스템이 자동으로 처리합니다. 휴먼 에러로 인한 데이터 유출 가능성을 완벽히 제거했습니다.
- 코드 가독성 및 생산성: 서비스 레이어의 마스킹 관련 코드가 대부분 제거되었습니다. 서비스 로직이 순수해지면서 코드 리뷰 속도가 빨라지고 가독성이 향상되었습니다.
- 유지보수 비용 절감: 마스킹 정책을 변경해도 엔티티 콜백 메서드 한 곳만 수정하면 전체 시스템에 즉시 반영되는 구조를 완성했습니다.
5. 마치며
개인정보 마스킹은 단순한 문자열 처리가 아닌 시스템 전체의 신뢰를 결정하는 보안 정책입니다. JPA의 생명주기를 이해하고 @PostLoad를 적절히 활용한다면 비즈니스 로직을 해치지 않으면서도 강력하고 깔끔한 보안 환경을 구축할 수 있습니다.
민감한 데이터를 다루는 백엔드 개발 과정에서 흩어져 있는 마스킹 로직으로 고생하고 계신다면 엔티티 생명주기 기반의 처리 방식을 적극적으로 고려해 보시기를 추천드립니다.
dwmoon