JavaParser

목차
- 들어가며
- Parser
- JavaParser 기능
- 라이브러리를 사용하며 겪은 문제 및 해결
들어가며
Modular Monolithic 아키텍처 프로젝트에서 메소드 호출 관계를 추출하는 업무를 맡으며 JavaParser를 처음 사용하게 되었습니다. 메소드 호출 관계를 추출하기 위해서는 각 메소드를 식별할 수 있는 식별자가 우선으로 필요했습니다. 메소드 시그니처를 식별자로 설정하고, 메소드 시그니처를 추론하는 것을 JavaParser 라이브러리에 위임하는 방식으로 업무를 진행했습니다.
이 외에도 메소드 호출 구조의 깊이, 영향도 분석, 인지적 복잡도 분석 등 정적 분석에 라이브러리를 활용할 수 있었고, 나아가서는 넘어온 파라미터에서 미사용 필드를 제거하여 Coarse-grained DTO에서 Fine-grained DTO로의 변환에도 활용할 수 있었습니다.
넥스트리에서 JavaParser 라이브러리는 대게 코드 생성에 사용됩니다. 하지만, 프로젝트에서 라이브러리를 사용했던 경험으로는 JavaParser는 Visitor, SymbolSolver와 같은 분석 관점에서 활용될 수 있는 기능들을 많이 제공하고 있습니다. 라이브러리를 소개하는 JavaParser:visited 책에서도 대부분 분석 기능 위주로 라이브러리를 소개하고 있습니다. 위 상황 외에도 정적 분석이 필요한 상황이라면 JavaParser를 사용해 보는 것이 좋은 선택이 될 것 같습니다.
Parser
글의 주제인 JavaParser 라이브러리를 설명하기 이전에 파서(Parser)란 무엇이며, 파서가 수행하는 파싱(Parsing)이란 어떤 기능을 수행하는 것인지 이해가 필요합니다.
컴파일러의 소스 코드 번역 과정은 6단계로 나뉩니다.
- 1단계: 어휘 분석 단계
- 원시 프로그램을 읽어 들여 프로그램 문장을 구성하고 있는 최소 단위인 어휘들을 떼어 내어 이 어휘들이 올바른지 분석하는 일을 합니다.
- 어휘 분석 단계를 통과하면 토큰(token)의 형태로 출력됩니다.
- 토큰은 의미 있는 최소의 문법적 단위를 뜻합니다.
- 2단계: 구문 분석 단계
- 구문 분석 혹은 파싱 이라고 하며, 어휘 분석 단계의 결과물인 토큰을 입력 받아 토큰의 열이 올바른 문장 구조를 갖고 있는지 검사합니다.
- 구문 분석 단계를 통과하면 토큰을 단말 노드로 하는 트리를 출력합니다. 이 트리를 Parse Tree, Concrete Syntax Tree(이하 CST)라고 합니다.
- 일반적으로 Parse Tree는 불필요한 정보인 식별자, 숫자, 식 등을 포함하여 메모리를 낭비하고 컴파일러의 속도를 떨어뜨립니다. 따라서 불필요한 정보를 제거하고, 다음 단계에서 필요한 정보만으로 구성된 트리를 만드는데, 이를 Syntax Tree, Abstract Syntax Tree(이하 AST)라고 합니다.
- 해당 단계를 담당하는 것이 파서 입니다.
- 3단계: 의미 분석 단계
- AST가 어떠한 의미가 있고 어떠한 기능을 하는지 분석하고, 기능이 올바르게 수행될 수 있도록 환경을 조성하는 일을 합니다.
- 4단계: 중간 코드 생성 단계
- 구문 분석 단계에서 만들어진 AST를 이용하여 중간 코드를 생성합니다.
- 5단계: 코드 최적화 단계
- 코드를 더 효율적으로 만들어 코드 실행 시 메모리나 실행 시간을 절약하기 위한 단계입니다.
- 6단계: 목적 코드 생성 단계
- 컴파일 과정의 마지막 단계로 연산을 수행할 레지스터를 선택하거나 데이터에 메모리 위치를 정해주며, 실제로 목적 기계어에 대한 코드를 생성하는 단계입니다.
- 중간 코드 생성에서 만들어진 중간 코드들을 기계 명령어로 바꾸어주는 역할을 합니다.
정리해 보면, 컴파일 과정에서 토큰을 입력받아 AST로 변환해 주는 것이 파서의 역할이며 이러한 과정을 **파싱(구문 분석)**이라고 부릅니다.
JavaParser 기능
파서의 역할에 대해서는 정리가 되었으니, 이제 본격적으로 JavaParser 라이브러리가 제공하는 기능을 살펴보며 기본적인 사용 방법을 알아보겠습니다.
먼저 종속성을 추가하겠습니다.
<dependency>
<groupId>com.github.javaparser</groupId>
<artifactId>javaparser-core</artifactId>
<version>LATEST</version>
</dependency>
dependencies {
implementation('com.github.javaparser:javaparser-core:LASTES')
}
1. Parsing
우선 기본적으로 JavaParser 또한 위에서 설명한 파서와 동일한 기능을 제공합니다. JavaParser는 문자열인 자바 코드를 파싱하여 AST로 변환합니다. 그리고 가장 루트가 되는 클래스인 CompilationUnit을 반환합니다. CompilationUnit은 소스 파일의 전체적인 구조를 가지고 있고, 세부적인 정보를 담고 있습니다. 라이브러리를 사용하여 소스 파일을 탐색, 조작할 때 진입점이 되는 클래스입니다.
파싱 기능을 사용하기 위해 라이브러리가 제공하는 클래스는 대표적으로 두 가지가 있습니다.
- JavaParser: 코드에서 AST를 생성하기 위한 API를 제공합니다.
- StaticJavaParser: 코드에서 AST를 생성하기 위한 빠르고 간단한 API를 제공합니다.
파싱할 코드는 LocalDateTime 클래스를 사용하여 현재 시간을 출력하는 코드입니다. 해당 글에서는 사용 방법을 간단하게 알아보는 것이 목적이므로 StaticJavaParser를 사용하여 파싱해 보도록 하겠습니다.
package ast;
import java.time.LocalDateTime;
public class Target {
public static void main(String args[]){
System.out.print(LocalDateTime.now());
}
}
StaticJavaParser 의 parse() 메소드를 이용해서 CompilationUnit을 얻을 수 있습니다. 소스 코드는 예시에서 사용된 Path 뿐 아니라 File, String, InputStream 등 여러 형태로 넘길 수 있습니다.
public class Analyzer {
private static final Path TARGET_PATH = Path.of(System.getProperty("user.dir"), "src", "main", "java", "ast", "Target.java");
public static void main(String[] args) throws IOException {
CompilationUnit cu = StaticJavaParser.parse(TARGET_PATH);
}
}
결과로 얻어진 CompilationUnit 을 트리 형태로 시각화해보면 다음과 같습니다.
트리를 보면 대상 소스는 크게 패키지 선언, 임포트 선언, 클래스 선언 세 가지 부분으로 나뉘고, 클래스 선언부는 크게 클래스 자체의 정보인 클래스명을 나타내는 부분과 클래스 내부에서 메소드를 선언하는 부분으로 나누어짐을 알 수 있습니다. 그리고 메소드 선언부를 따라 들어가면 메소드의 세부적인 정보를 유형에 따라 저장하고 있음을 확인할 수 있습니다.

2. Comments
JavaParser 라이브러리가 결과물로 내놓는 트리는 일반적인 AST와 차이점이 있습니다. 주석에 관한 정보를 담고 있다는 점입니다. 컴파일 과정에서 주석은 1단계인 어휘 분석 단계에서 사라지는 정보입니다. 어휘 분석 단계에서 정의한 ‘의미 있는 최소의 문법적 단위’인 토큰에 해당하지 않기 때문입니다.
하지만 JavaParser 라이브러리는 주석에 관한 정보를 제공할 뿐 아니라 특정 노드에 달린 주석을 수집하는 기능, 소스 파일 전체의 주석을 수집하는 기능 등을 추가로 제공하기 때문에 사용자는 라이브러리를 통해 유의미한 주석을 수집할 수 있습니다.
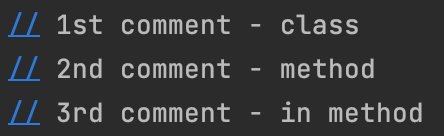
다음은 소스 코드 내 모든 주석을 수집하는 예시입니다.
package comment;
// 1st comment - class
public class Target {
// 2nd comment - method
public static void main(String[] args) {
// 3rd comment - in method
System.out.println("comment parsing test...");
}
}
public class Analyzer {
private static final Path TARGET_PATH = Path.of(System.getProperty("user.dir"), "src", "main", "java", "comment", "Target.java");
public static void main(String[] args) throws IOException {
CompilationUnit cu = StaticJavaParser.parse(TARGET_PATH);
List<Comment> commentList = cu.getAllComments();
commentList.forEach(comment -> System.out.println(comment.asString()));
}
}
3. Visitor
위(1. Parsing) 에서 AST 트리 그래프를 다시 살펴보면 아주 간단한 코드를 파싱했음에도 불구하고 결과물로 출력된 CompilationUnit의 내부는 복잡했습니다. 만약 사용자가 다른 노드에는 관심이 없고, 메소드 선언에 관한 정보를 담고 있는 노드인 MethodCallExpr에만 관심이 있다고 가정해 본다면, 현재 코드에서도 MethodCallExpr까지 닿기는 꽤 복잡한 과정을 거쳐야 합니다. 여기서 소스 코드가 더 복잡하고 길어진다면 어떨까요? 불가능은 아니겠지만 재귀로 트리를 탐색해야 하고, 그 과정에서 오류가 발생할 가능성도 큽니다.
이러한 문제를 해결하기 위해 라이브러리에서는 Visitor를 제공합니다. Visitor는 특정 종류의 노드를 쉽게 찾을 수 있도록 하고, 찾은 노드를 수집할 수 있도록 합니다. 다음의 예시에서는 소스 코드 내 메소드를 선언하는 노드인 MethodDeclaration 을 모두 찾아보겠습니다.
Target.java에서는 public void foo() 메소드와 public void bar() 메소드가 선언되어 있습니다.
package visitor;
public class Target {
public void foo() {
System.out.println("foo");
}
public void bar() {
System.out.println("bar");
}
}
라이브러리에서 제공하는 VoidVisitorAdapter를 상속받아 visit() 메소드를 오버라이딩 해보겠습니다. VoidVisitorAdaptor의 제네릭으로 수집된 정보가 담길 collector 넘겨주고, visit() 메소드의 첫 번째 파라미터로는 코드 내에서 찾고 있는 노드의 타입을, 두 번째 파라미터로는 찾은 정보를 저장할 collector를 넘깁니다.
public class MethodVisitor extends VoidVisitorAdapter<List<MethodDeclaration>> {
@Override
public void visit(MethodDeclaration md, List<MethodDeclaration> collector) {
super.visit(md, collector);
collector.add(md);
}
}
정의한 Visitor 클래스를 사용하여 실제로 메소드 선언부를 수집하고, 간단하게 출력해 보겠습니다. 오버라이딩한 visit() 메소드를 호출하여 MethodDeclaration을 수집했습니다.
public class Analyzer {
private static final Path TARGET_PATH = Path.of(System.getProperty("user.dir"), "src", "main", "java", "visitor", "Target.java");
public static void main(String[] args) throws IOException {
CompilationUnit cu = StaticJavaParser.parse(TARGET_PATH);
MethodVisitor visitor = new MethodVisitor();
List<MethodDeclaration> methodDeclarationList = new ArrayList<>();
visitor.visit(cu, methodDeclarationList);
methodDeclarationList.forEach(md -> System.out.println(md.getDeclarationAsString()));
}
}
4. SymbolSolver
JavaParser SymbolSolver는 변수, 파라미터 등을 호출 시 소스 코드에서 해당 변수, 파라미터 등의 선언부를 찾아 실제 타입을 알려주는 기능을 제공합니다. 메소드 호출부의 경우에는 호출되는 메소드의 메소드 시그니처를 찾을 수도 있습니다. 메소드 호출부의 메소드 시그니처를 추론하는 예시를 통해 어떻게 타입을 추론할 수 있는지 알아보겠습니다.
우선 SymbolSolver 사용을 위해서는 의존성 추가가 필요합니다.
<dependency>
<groupId>com.github.javaparser</groupId>
<artifactId>javaparser-symbol-solver-core</artifactId>
<version>LATEST</version>
</dependency>
dependencies {
implementation('com.github.javaparser:javaparser-symbol-solver-core:LATEST')
}
아래와 같이 Foo라는 클래스를 정의하고, Target 클래스에서 Foo 클래스의 bar() 메소드를 사용해 보도록 하겠습니다.
package symbolsolver;
public class Foo {
public void bar() {
System.out.println("sample bar() method.");
}
}
public class Target {
private Foo foo = new Foo();
public void typeSolverTest() {
foo.bar();
}
}
JavaParser를 이용하여 bar()메소드 호출부의 시그니처를 추론해 보도록 하겠습니다.
JavaParserTypeSolver에 메소드를 추론할 수 있는 정보인 소스 파일의 루트 경로를 제공한 후, JavaSymbolSolver에 등록합니다. StaticJavaParser의 설정을 가져와 JavaSymbolSolver를 등록한 후 파싱을 진행합니다.
public class Analyzer {
private static final Path SOURCE_ROOT_PATH = Path.of(System.getProperty("user.dir"), "src", "main", "java");
private static final Path TARGET_PATH = Path.of(System.getProperty("user.dir"),"src","main", "java", "symbolsolver", "Target.java");
public static void main(String[] args) throws IOException {
JavaSymbolSolver javaSymbolSolver = new JavaSymbolSolver(new JavaParserTypeSolver(SOURCE_ROOT_PATH));
StaticJavaParser.getParserConfiguration().setSymbolResolver(javaSymbolSolver);
CompilationUnit cu = StaticJavaParser.parse(TARGET_PATH);
List<MethodCallExpr> methodCallExprList = cu.findAll(MethodCallExpr.class);
methodCallExprList.forEach(methodCallExpr -> {
System.out.println(methodCallExpr.resolve().getQualifiedSignature());
});
}
}

JavaParser에게 타입의 정보를 제공하는 TypeSolver는 다양한 유형으로 나뉩니다.
- JarTypeSolver: JAR 파일 내부의 클래스를 찾습니다. 파라미터로 JAR 파일의 경로를 지정합니다.
- JavaParserTypeSolver: 소스 파일에 정의된 클래스를 찾습니다. 파라미터로 소스의 루트 경로를 지정합니다. 패키지에 해당하는 디렉토리에서 소스 파일을 찾습니다. 위 예시에서는 Foo 클래스는 symbolsolver 패키지 내에 위치했습니다. SymbolSolver는 “지정된 루트 경로/symbolsolver/Foo”가 존재하는지 찾게 됩니다.
- ReflectionTypeSolver: java.lang.Object와 같이 JAR 파일이 없어도 java 언어의 일부처럼 쓰이는 클래스들이 있습니다. 이러한 클래스의 타입을 추론하기 위해 사용됩니다.
- MemoryTypeSolver: 메모리에 기록된 클래스를 반환합니다. 주로 테스트 용도로 사용됩니다.
- CombinedTypeSolver: 여러 TypeSolver를 SymbolSolver에 등록하기 위해 사용됩니다.
5. Transform / Generate
JavaParser 홈페이지(https://javaparser.org/)를 확인해 보면, 라이브러리의 대표적인 기능으로 소개되고 있는 것은 코드 분석, 변환, 생성 세 가지입니다. 지금까지는 이 중 분석을 중심으로 소개했습니다. 이제부터 남은 대표 기능 변환과 생성 두 가지를 살펴보도록 하겠습니다.
파싱이 코드를 AST의 형태로 변환하는 기능이었다면, 변환과 생성은 반대로 AST를 코드의 형태로 변환하는 기능입니다. AST를 코드의 형태로 변환할 때, 코드는 다음의 두 가지 형식으로 변환될 수 있습니다.
- pretty printing: 표준적인 형식으로 변환.
- lexical preserving printing: 원래 코드가 가졌던 레이아웃을 유지한 형태로 생성. 파싱한 AST를 다시 코드로 생성할 때 주로 사용.
첫 번째로 pretty printing 형식으로 아래 Target.java와 동일한 코드를 생성해보겠습니다.
package generate;
// code generate
public class Target {
private String foo;
public void bar() {
}
}
CompilationUnit에 필요한 노드를 채워가는 방식으로 코드를 생성할 수 있습니다.
public class GeneratorUsingPrettyPrinting {
public static void main(String[] args) {
CompilationUnit compilationUnit = new CompilationUnit();
// package
compilationUnit.setPackageDeclaration("generate");
// class
ClassOrInterfaceDeclaration classOrInterfaceDeclaration = new ClassOrInterfaceDeclaration();
classOrInterfaceDeclaration.setName("Target");
// comment
LineComment comment = new LineComment("code generate");
classOrInterfaceDeclaration.setComment(comment);
// field
classOrInterfaceDeclaration.addField("String", "foo", Modifier.Keyword.PRIVATE);
// method
classOrInterfaceDeclaration.addMethod("bar", Modifier.Keyword.PUBLIC);
compilationUnit.setTypes(new NodeList<>(classOrInterfaceDeclaration));
System.out.println(compilationUnit);
}
}

두 번째로 lexical preserving printing 형식으로 코드를 생성해보겠습니다. 기존의 코드를 파싱하여 CompilationUnit으로 변환한 후, 다시 코드로 생성하는 방식으로 진행하겠습니다.
첫 번째 예시에서 사용했던 Target.java에 일반적으로 사용되지 않는 형태의 공백을 추가해보겠습니다.
package generate;
// code generate
public class Target {
private String foo;
public void bar() {
}
}
pretty printing 형식과 lexical preserving printing 형식 모두를 출력하여 비교해보겠습니다.
public class GeneratorUsingLexicalPreservingPrinting {
private static final Path TARGET_PATH = Path.of(System.getProperty("user.dir"),"src","main", "java", "generate", "Target.java");
public static void main(String[] args) throws IOException {
CompilationUnit cu = StaticJavaParser.parse(TARGET_PATH);
LexicalPreservingPrinter.setup(cu);
System.out.println("-- pretty printing --");
System.out.println(cu);
System.out.println("-- lexical preserving printing --");
System.out.println(LexicalPreservingPrinter.print(cu));
}
}
둘을 놓고 비교해보면, lexical preserving printing 형식은 사용자가 입력한 그대로 공백까지 유지해서 코드를 생성함을 알 수 있습니다.


JavaParser를 사용하며 겪은 문제
프로젝트에서 JavaParser를 사용하면서 모든 것이 매끄럽게 진행된 것은 아니었습니다. 제가 겪었던 JavaParser의 문제와 이를 해결했던 경험을 공유하고자 합니다.
1. SymbolSolver
Moduler Monolithic 아키텍처의 특성상, 프로젝트가 여러 개로 나누어져 있고 타 프로젝트를 dependency로 사용하는 방식을 채택하고 있기 때문에 타 프로젝트의 메소드는 시그니처를 추론하기 위해서는 JarTypeSolver에 타 프로젝트의 모든 jar파일 경로를 등록해주어야 했습니다. 나누어져 있는 프로젝트의 수가 많았을뿐더러 업무를 진행할 당시에는 모든 프로젝트의 소스에 접근할 수 없었기 때문에 모든 프로젝트의 jar 파일을 등록한다는 것은 불가능했고, 다른 방법을 찾아야 했습니다.
찾은 해결책은 모든 dependency를 담고 있는 하나의 Fat-JAR를 만들어 JarTypeSolver에 등록하는 방식이었습니다. 분석 대상 프로젝트의 타입 추론은 JavaParserTypeSolver에게, 타 프로젝트의 타입 추론은 JarTypeSolver에게 위임하는 방식으로 문제를 해결했습니다.
2. Lombok Annotation
메소드 시그니처 추론에서 두 번째로 문제가 되었던 부분은 JavaParserTypeSolver를 사용하면 롬복 어노테이션 @Getter @Setter로 생성되는 getter setter 메소드를 라이브러리가 추론하지 못한다는 것이었습니다. 실제 getter setter 메소드가 생성되는 시기는 컴파일 과정 중이므로 소스 파일 자체를 읽어 타입을 추론하는 JavaParserTypeSolver는 getter setter 메소드를 읽지 못해 타입을 추론할 수 없었습니다.
찾은 해결책은 분석 대상 프로젝트를 delombok 한 소스 파일을 제공하는 방법이었으나, 대부분의 프로젝트에서 롬복 어노테이션이 사용되는 상황에서 JavaParser 라이브러리 또한 이를 추론할 수 있도록 TypeSolver를 제공해야할 것 같습니다.
출처
- 박두순, 김강현 공저, 컴파일러 구성(한국방송통신대학교출판문화원, 2017)
- Nicholas Smith, Danny van Bruggen, and Federico Tomassetti, JavaParser: Visited