Git basic

Git 이란 무엇일까?
도서관에서 책을 대여하기 위해선 어떻게 해야하는가? 도서관을 이용해본 적이 없더라도 조금만 고민을 해본다면 쉽게 대답할 수 있을 것이다.

여기 넥스트리 도서관이 있다. 넥스트리 도서관에는 방대한 양의 책들이 존재한다 이 중에서 나는 한 권의 책을 골라 대여를 하고 싶다. 그러기 위해선 먼저 도서관을 방문해야 한다. 어떤 책을 읽을지 천천히 둘러볼 수도 있고 읽고 싶은 책이 있다면 그 책의 위치를 찾아볼 수도 있을 것이다.
책들은 하나의 일관된 시스템 속에 정리정돈 되어있다. 간단한 예로 다음과 같은 기준으로 책을 정리하는 도서관이 있다고 하자.
801.84 바75ㅋ
이 책을 어디서 어떻게 찾으면 될까? 감이 잡히질 않아 도서관 사서에게 도움을 요청하였다. 역시 사서답게 수 초가 걸리지 않아 내가 원하는 책을 찾아 가져다 주었다.
이제 사서에게 나의 회원카드를 보여주고 책을 대여한다.
Git은 도서관이다.
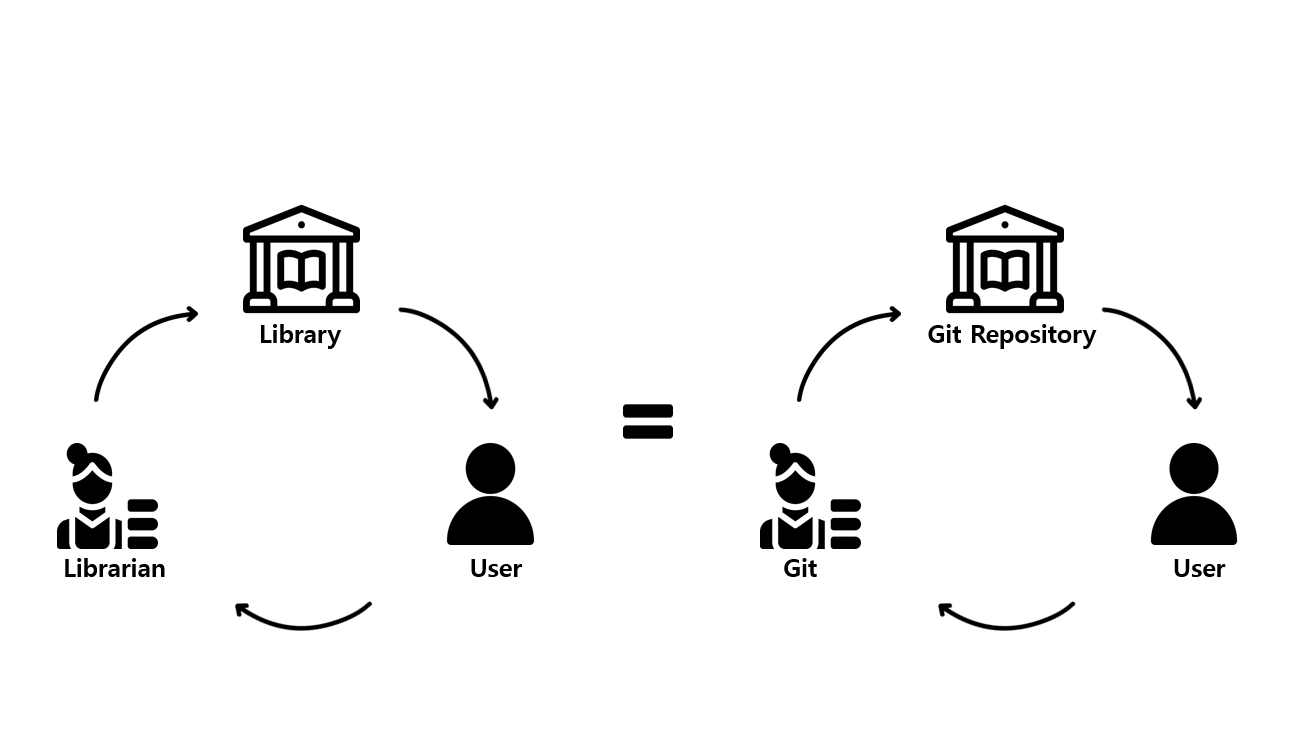
Git 은 하나의 도서관과도 같다. Git Repository 라는 도서관에 방문하여 원하는 책을 고르듯 branch / commit 을 선택하여 파일을 가져온다. 이 일련의 과정이 마치 도서관에서 책을 대여하는 것과 같다. 그런데 한 가지 의문이 든다. 위 그림을 보면 Git Repository 와 Git을 구분지어 놓았다. Git의 역할은 무엇일까?
도서관 사서, Git
Git은 Git Repository에 일하는 도서관 사서이다. 도서관 사서가 도서관의 모든 책을 관리하고 이용자가 원하는 책을 대여하며 반납된 책은 정리하여 책장에 가져다 놓듯, Git 은 우리의 Repository를 관리하고 수정이 필요한 파일을 우리에게 가져다주며 수정이 완료되어 보관을 요청한 파일을 정리하여 Repository에 가져다 놓는다.
그렇다면 Git은 수정 중인 파일과 수정이 완료된 파일을 어떻게 알 수 있을까?
Git 이 데이터를 관리하는 방법
Git은 도서관 사서와 같아서 우리가 요청한 파일을 가져다 주고 수정이 끝난 파일은 Repository에 보관 해준다고 하였다. Git이 알파고 같은 AI라서 그렇게 할 수 있는 것이 아니다. Git이 데이터를 관리하는 방법을 알게 된다면 Git을 나만의 도서관 사서로 더욱 편리하게 사용할 수 있게 된다.
Git을 알기 위해 도서관 사서의 역할에 대해 조금 더 자세히 살펴보자.
-
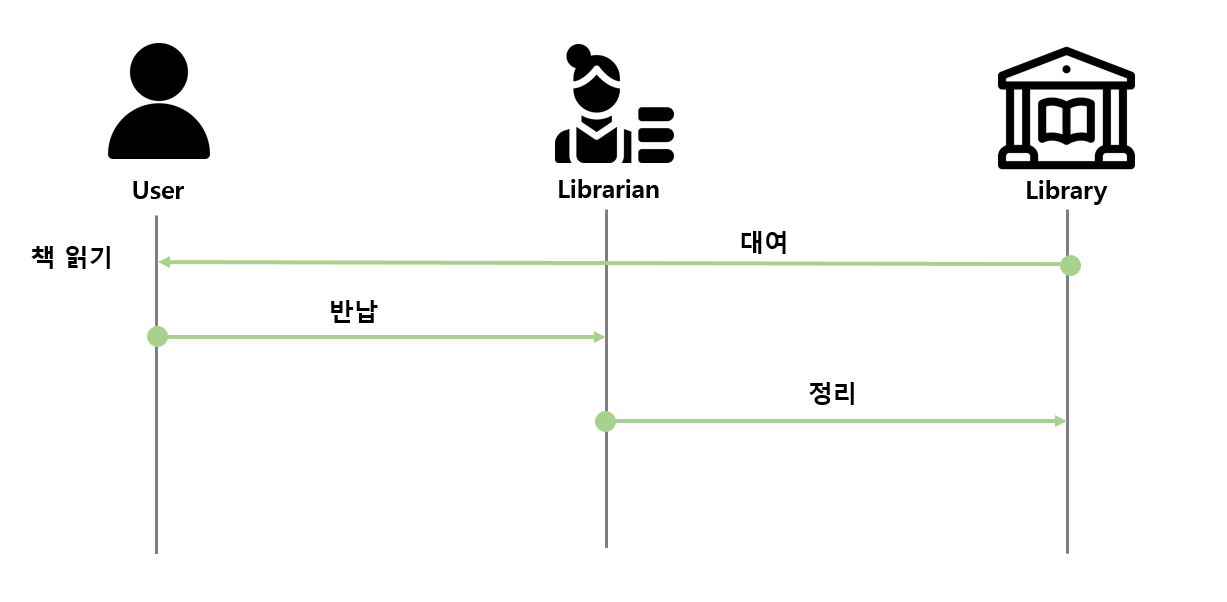
대여 & 책 읽기
도서관 사서는 이용자에게 책을 대여해준다. 만약 이용자가 책을 대여한 동안 장난삼아 책의 단어 몇 개를 지워도 사서는 모를 것이다. 이제 반납 기간이 다 되어 이용자는 책을 반납한다. -
반납
이용자가 책을 다 읽어서 반납하는지 재미가 없어서 읽다 말았는지 도서관 사서에겐 중요하지 않다. 사서는 책이 손상되거나 이전과 다른 부분은 없는지 검사를 한다. 만약 책이 손상되었거나 대여 전의 상태와 같지 않다면 이용자에게 대여 기간 동안 책에 무슨 일이 있었는지를 묻게 될 것이다. -
정리
정상 반납 처리가 된 책은 00월 00일 00시에 책이 반납 처리 되었다고 시스템에 업데이트하여 한 곳에 모아 두었다가 특정 시점이 되었을 때 각 책장을 돌아다니며 정리한다. 그런데 반납했던 이용자가 책 사이에 중요한 메모지를 끼워두었다며 반납했던 책을 다시 가져다 줄 수 있는지 물어온다. 사서는 기꺼이 책을 다시 가져다 줄 것이다.
Git이 데이터를 관리하는 방법도 이와 같다.
대여 / 반납 / 정리의 과정을 Modified / Staged / Committed 라는 세 단계로 처리한다.
Git이 데이터를 관리하는 세 단계
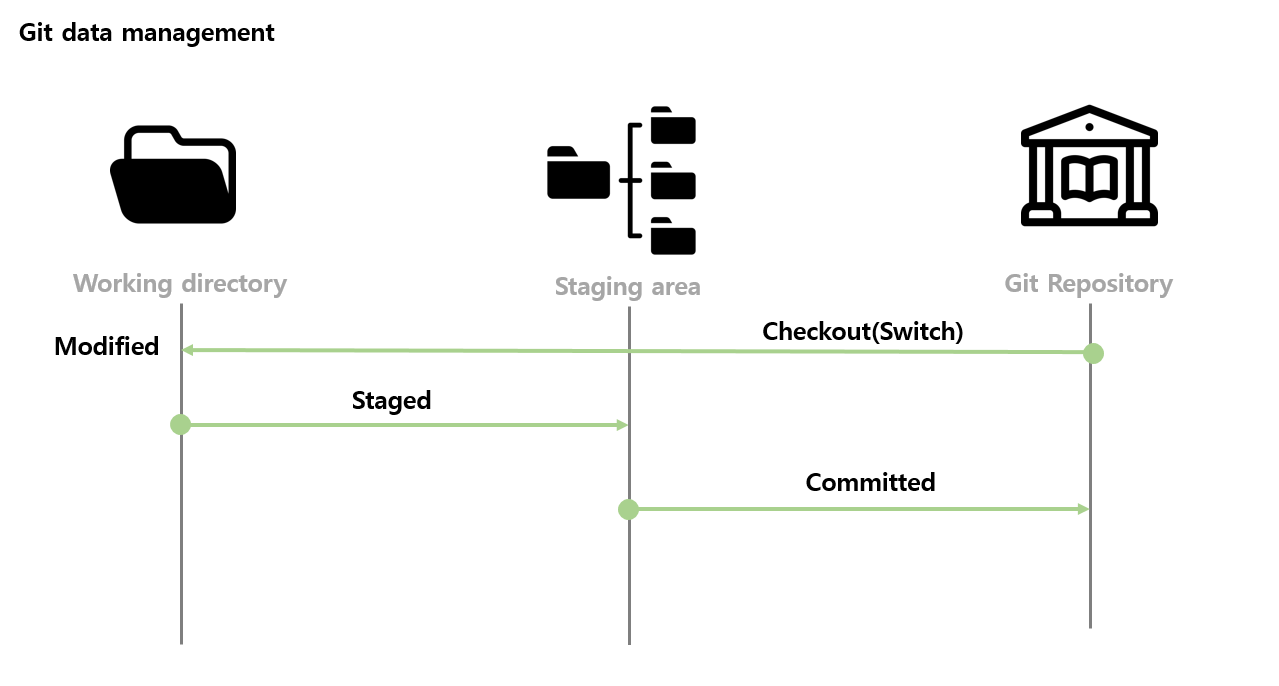
Git 은 단 세 단계로 데이터를 효과적으로 관리한다.
-
Checkout(Switch) & Modified
이 단계는 ’대여’에 해당된다. Git 은 이용자가 Checkout(Switch)하길 원하는 데이터를 찾아서 가져다 준다. Checkout된 데이터에 대해서 이용자가 무엇을 하든 관여하지 않는다. 데이터의 일부를 수정하거나 삭제하거나 아예 새로운 데이터로 만들 수 있다. 이 때 데이터가 위치하는 장소는 Working directory이다. -
Staged
’반납’에 해당되는 단계이다. 이용자가 수정, 삭제, 생성 등의 임의의 작업을 한 데이터에 대해서 Git에 보관 처리를 요청하는 것이다. 이때 Git은 자신이 기존에 알고 있던 데이터와 Staged 상태가 된 데이터에 대해 비교를 하고 바뀐 부분이 있는지 파악한다. 이제 데이터는 Working directory 에서 Staging area로 이동된다. -
Committed
Staged 된 데이터를 Git Repository에 정리하는 단계이다. 00월 00일 00시에 누가 Commit 했는지 이력을 남긴다. 특이점이 있거나 데이터의 변환점을 상술하고자 한다면 Commit message를 남길 수도 있다. 이렇게 정상 Commit이 된 데이터는 Staging area 에서 Git Repository로 등록된다. 혹시나 이용자가 committed 된 데이터를 다시 보고자 한다면 Git은 데이터를 다시 찾아 이용자에게 가져다 준다.
Git 사용하기
Git의 개념과 Git이 파일을 관리 방법 우리가 찾는 파일을 가져다 주는 과정에 대해서 도서관 에 비유하여 알아보았다. 이번엔 Git을 직접 이용하여 도서관에서 책을 대여, 반납, 정리한다는 것이 어떤 의미인지 확인해보자.
Git 설치
Git은 Git 공식 사이트에서 Download 할 수 있다. 사용의 편의성을 위해 GUI Clients 도 제공하지만 Git의 모든 기능을 온전히 사용하기 위해선 CLI 에 익숙해지는 것이 좋다.
처음엔 조금 어려울 수 있으나 아래의 내용을 하나씩 따라해보면 CLI에 금방 적응할 것이다.
Everyday git
Git 공식 사이트(https://git-scm.com/)에는 우리가 Git을 사용하며 필요로 하게 될 모든 정보가 다 들어있다. 특히 다음의 순서를 따라 들어가 보면 매일 매일 Git을 사용하기 위한 아주 유용한 명령어들 20가지를 설명하고 있다.
Documentation > Reference > Everyday Git
Git 공식 사이트에서 추천하는 명령어들을 토대로 Git을 어떻게 사용하면 되는지 알아보자
Git Repository 만들기
당연한 이야기지만 책을 빌리려면 도서관이 존재해야 한다. 마찬가지로 우리의 프로젝트를 Git으로 관리하기 위해선 Local directory에 Git Repository가 존재해야 Git으로 버전 관리를 할 수 있다.
그렇다면 Git Repository는 어떻게 만들 수 있을까?
git init / git clone
Git Repository를 만들기 위한 방법엔 두 가지가 존재한다.
- Git으로 관리할 프로젝트 경로에 최초 생성하는 방법
- 다른 컴퓨터에 이미 존재하는 Git Repository를 가져오는 방법
첫 번째 방법에 해당되는 것이 git init 이다.
$ git init
이 명령어는 현재 프로젝트 내에 .git 이라는 하위 폴더를 생성한다. 이 폴더 내에 Git Repository가 존재하게 되지만 이 명령만으론 아직 프로젝트 내의 어떤 파일도 관리를 하지 않는다.
다음은 git clone 의 동작에 대해서 알아보자
$ git clone <REPOSITORY_URL>
명령어를 보다시피 <REPOSITORY_URL> 로부터 파일들을 복사하겠다고 이해하면 쉽다.
또한 REPOSITORY_URL에 이미 Git Repository가 존재하고 있기 때문에 우리의 컴퓨터에 clone을 받아오면 그동안 누군가가 관리해온 파일들의 이력도 함께 확인이 가능하다.
파일 추가하기
어떤 식으로든 Local directory에 Git Repository를 생성했다면 다음 명령어를 입력해보자.
$ git status
위 명령어를 입력하면 현재 git의 상태가 출력된다.
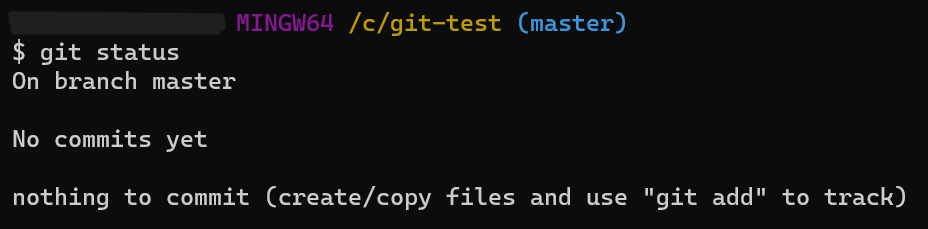
출력된 메시지의 의미는 다음과 같다.
여기서 track 은 Git이 파일을 관리하는 상태에 대한 의미이다. Git은 자기가 아는 파일인지 아닌지에 대해서 Tracked / Untracked 로 명명한다.
자 메시지를 이해했으면 Git이 하라는대로 해보자. 먼저 새로운 파일을 만들고 다시 git status 명령어를 입력해보자
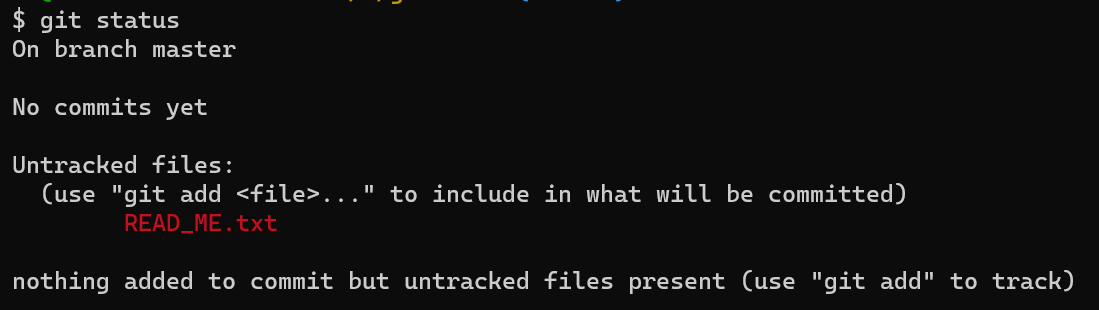
메시지 내용이 추가되었다.
앞서 말한 Untracked 라는 단어가 보이는 걸 보니 Git이 모르는 파일이 있다는 내용같다.
방금 새로 생성한 READ_ME.txt 파일이다. 이 파일을 git add 하여 committed 영역에 포함시키라고 한다.
역시 Git이 하라는대로 해보자.
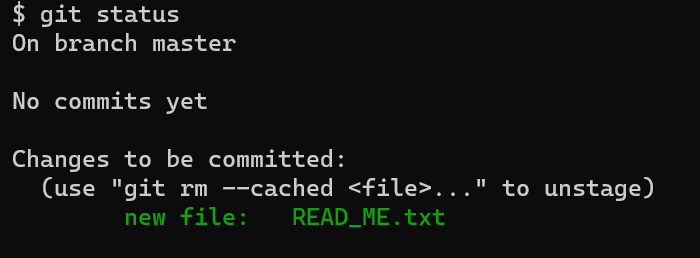
git add 명령어를 사용했더니 changes to be committed 항목으로 새로운 파일이 추가됬음을 를 보여준다. 유능한 도서관 사서인 Git이 우리가 어떤 파일을 반납하려는지 알고 있다는 것이다.
추가한 파일 커밋하기
앞서 Git은 세 단계를 거쳐 데이터를 관리한다고 했다. git add는 세 단계 중 두번째인 Staged 에 파일이 올라간 단계이다. 즉 반납 처리는 했으나 반납한 책을 아직 책장으로 정리하여 다음 사람이 볼 수 있도록 하지 않은 것이다.
커밋은 Git Repository에 데이터를 완전히 저장하는 단계이다.
git commit 명령어를 통해 반납 과정을 완료해보자.
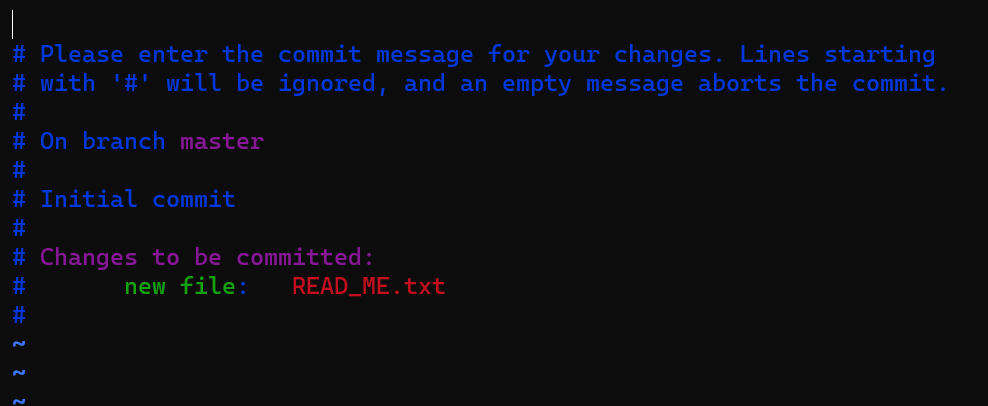
git commit 명령어만 사용하면 당황스럽게도 vim editor 화면이 보일 것이다. 아직 vim editor 까지는 마음의 준비가 안 되었을 수 있다. commit 과정을 한 단계 단축시켜줄 option 을 추가해보자
$ git commit -m '커밋 메시지 입력'
commit message로는 대게 해당 commit 이 어떤 작업을 위한 것이였는지에 대해 작성한다. 이렇게 하면 commit message만 보고도 해당 commit이 어떤 데이터를 갖고 있을지 쉽게 유추할 수 있다.
그런데 만약 commit message를 엉뚱하게 작성했거나 오타가 포함되어 있다면 어떻게 해야할까?
우리는 Git이 파일 관리에 뛰어나다는 것을 기억해야한다. 이런 경우를 위해 Git은 commit 사항에 대해 수정 옵션을 지원한다.
$ git commit --amend -m '수정 커밋 메시지 입력'
위 명령어를 참고하여 commit message를 수정해보자
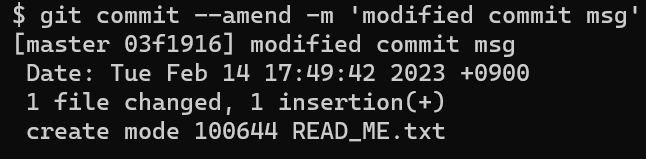
commit을 하면 Git은 해당 commit에 대한 정보를 출력해준다. 출력된 commit 정보를 통해 추후 커밋 이력을 조회할 수도 있다.
Commit History
커밋 이력을 보는 것은 중요하다. 어떤 파일이 어떻게 수정되었는지, 언제 삭제되었는지, 어떤 변화를 겪었는지 커밋 이력을 보면 그 대략을 알 수 있다.
다음 명령어를 입력해보자.
$ git log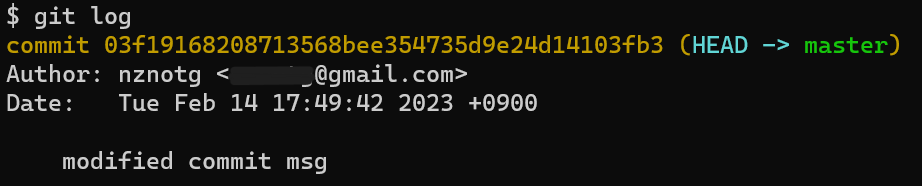
조금 전에 commit을 한 이력이 보인다. 새로운 파일을 만들고 커밋을 한 번 더 하면 어떻게 될까?
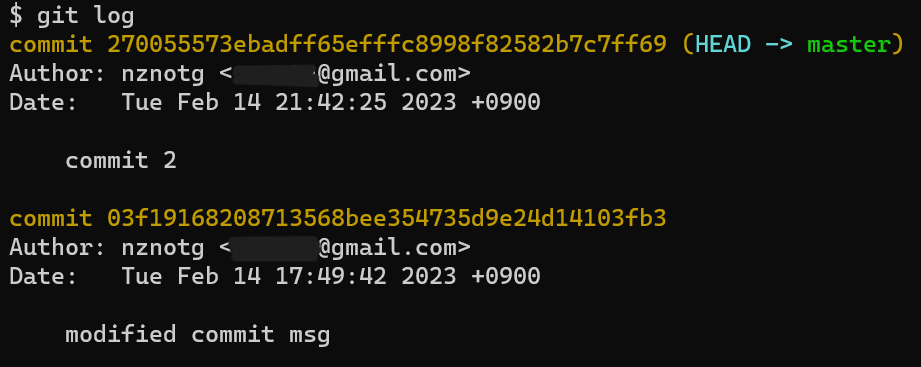
두 번째 커밋 이력이 확인된다. 또한 Git은 누가, 언제 commit을 했는지 기록하여 보여준다.
아직은 커밋 이력이 2개밖에 되지 않기 때문에 커밋 이력을 보는 이점이 무엇인지 와닿지 않는다.
만약 10명의 개발자가 1년의 개발 기간동안 매일 매일 무언가를 수정하여 커밋했다고 가정해보자.
1주일 전 수정된 내용을 살펴보는데만 해도 복잡해질 것이다. 복잡한 log들이 한 줄로 간략하게 게다가 그래프로 표시된다면 좋지 않을까?
그렇다면 다음 option이 추가된 git log 명령어를 입력해보자
$ git log --decorate --all --graph --oneline
조금 길고 복잡해 보인다. 그러나 한 번 손에 익으면 1년치 commit history도 쉽게 볼 수 있는 편리한 option이다. 각 opiton이 의미하는 바는 다음과 같다.
--decorate: branch의 이름을 어떻게 출력할지 정하는 옵션--decorate=short|full|auto|no
default 값은 short.--all: 현재 branch 뿐만 아니라 모든 branch의 commit 사항을 보여주도록 정하는 옵션--graph: commit list를 graph로 보여주는 옵션--oneline: 짧은 체크섬과 branch, commit message 를 한 줄로 보여주는 옵션
이 복잡한 git log 명령어를 입력하면 다음과 같이 여러 commit 들을 graph로 출력하여 보여준다.
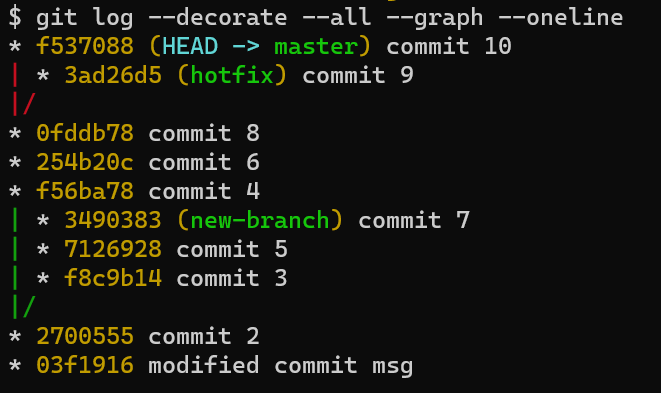
당장은 graph로 보는 것이 더 어렵게 느껴질 수 있다. 그러나 지난 commit 이력을 살펴볼 줄 아는 것은 생각보다 중요하다. 현재의 commit이 가리키는 위치를 보고 데이터 수정을 계속 진행할지, 다른 branch와 merge / rebase 할지 판단을 할 수 있기 때문이다.
가장 중요한 것은 Committed 상태 만들기
간단하게 add , commit, log 에 대해서 살펴보았다.
이 중에서 가장 중요한 것은 commit이다. 책을 대여 했으면 반납을 해야하듯, 파일을 수정 했으면 commit을 해야한다.
commit 에는 단순히 누가, 언제 라는 정보보다 훨씬 중요한 데이터의 스냅샷이 담겨있다. commit이 중요한 이유도 이 스냅샷 때문인데 Git이 기존에 알고 있던 commit 데이터와 새로운 commit 데이터가 어떻게 다른지 이 스냅샷으로 판단할 수 있기 때문이다. 따라서 commit을 중심으로 Git의 데이터는 흘러간다.
다음으로 Merge 개념에 대해 살펴보면서 commit에 담긴 데이터가 왜 중요한지 살펴보자.
Merge
위 graph를 보면 master / hotfix / new-branch 세 개의 Branch로 분기되어 있는 것을 확인할 수 있다.
실제로 세 개의 branch는 각각 서로 다른 file list를 가지고 있다.
이처럼 1번 branch 에서 작업한 내용이 2번 branch에 없으면 예상했던 최종 결과물과 실제 결과물이 달라질 것이고 결국 우리가 작업한 내용이 쓸모 없어진다.
이를 위해 Git은 데이터 병합, Merge 기능을 제공한다.
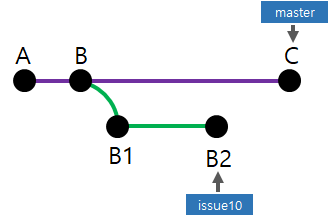
commit A에서 시작된 데이터는 commit B를 지나 분기되어 issue10 - B2 와 master - C 라는 서로 다른 데이터를 갖게 되었다. 특정 시점이 되어 issue10 - B2 에서 수정을 마무리하여 master -C 와 병합하려고 한다. 이때 Git의 Merge는 일방적으로 issue10 - B2 데이터를 master - C 데이터에 병합하지 않는다.
B2 와 C의 공통 부모 commit을 찾아 부모 커밋을 토대로 C / B2 를 비교하여 새로운 commit을 생성한다.
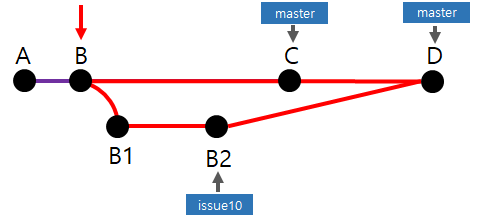
새로운 commit D가 생성되었다. commit D에는 B를 기준으로 master - C 의 내용과 issue10 - B2 의 내용이 병합되어있다.
3개의 commit을 기준으로 병합한다고 하여 이를 3-way Merge라고 한다.
이제 실제로 git merge 명령어를 입력해보자. 먼저 hotfix 데이터를 master 에 병합해 보겠다. 이를 위해선 merge를 할 branch로 switch 해준다.
$ git switch master
$ git merge hotfix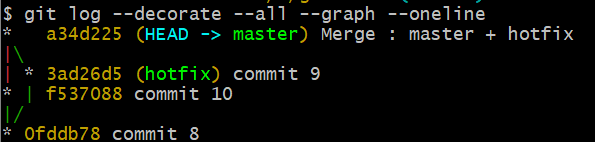
master 와 hotfix 가 서로 연결되어 하나의 commit이 된 것을 확인할 수 있다.
앞서 말한 3-way Merge를 통해 공통된 부모 commit을 기준으로 각 branch에 있는 데이터들을 병합하여 새로운 commit a34d225 를 만든 것이다.
commit을 제대로 하지 않았다면 원치 않는 최종 결과물을 얻게된다. 마치 대여한 책의 하이라이트 부분에서 누군가 고의로 책을 찢어놓은 것과 같다. 따라서 수정을 했으면 commit을 해야하고 Branch를 작업 분류에 따라 잘 분기하여 데이터를 관리하는 것이 장기적으로 유용하다.
Conflict
만약 분기된 각각의 branch에서 같은 파일을 서로 다르게 수정했다면 Git은 conflict message를 출력한다.
공통된 부모 commit을 기준으로 각 branch 에서 수정된 내용을 병합할 때, 같은 파일을 서로 다르게 수정한 것에 대해서 Git은 자동 병합을 해주지 않고 개발자에게 이양한다. 대신 자기가 찾아낸 같은 파일 내에 어떤 부분이 어떻게 다른지를 보여준다. 아래의 이미지를 보자.

hotfix branch를 master branch 에다 병합하려고 했는데 CONFLICT 문구가 출력되었다. 해당 문구는 auto merge failed 의 해결책을 알려주는 문구이다. 그 의미는 다음과 같다.
Git이 알려준대로 f2.txt 파일을 열어보면 다음과 같이 당황스러운 문자열이 추가되어 있다.
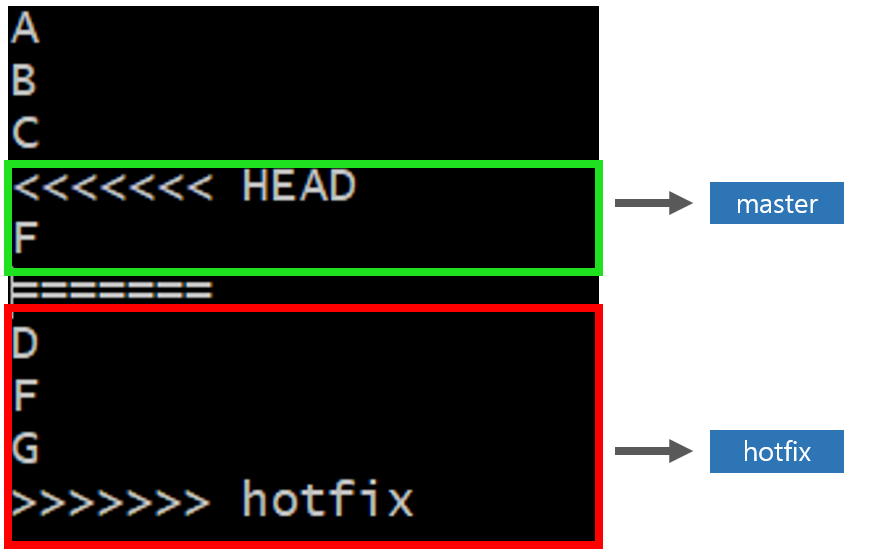
‘===’ 를 기준으로 위(HEAD)는 master branch에 있는 f2.txt 파일의 내용이고
아래(hotfix)는 hotfix branch에 있는 f2.txt 파일의 내용이다.
Git이 알려준 각 브랜치가 갖고 있는 공통된 파일의 차이점을 보고 어떤 게 내가 원하는 데이터인지를 판단하여 해당되는 내용만 남기고 수정해주면 된다. master에 있는 내용을 지우고 hotfix의 내용만 남겨보았다.

이제 다시 Git이 하라고 한 commit을 해주면 된다. git status 를 통해 파일이 정상적으로 Tracked 되었는지 확인해보자
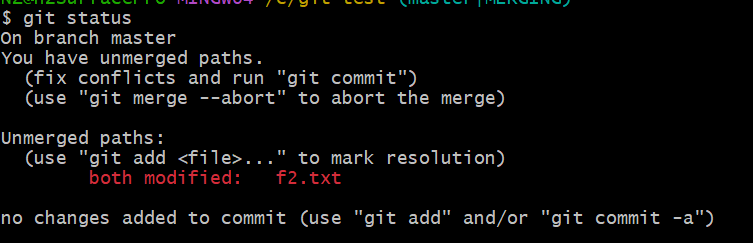
both modified 라고 출력된 것을 보니 Git이 정상적으로 파일이 수정된 것을 인식하였다.
이제 commit을 진행하여 Merge conflict 해결을 마무리 하자.
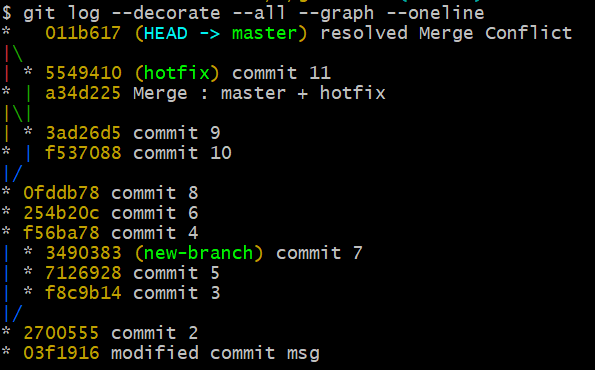
분기되있던 hotfix branch의 graph가 새로운 commit 으로 이어졌다. Conflict가 해결된 것이다.
Remote Repository
지금까지 일어난 일은 모두 Local directory에 있는 Git Repository에서 일어난 것이다. 그러나 내가 수정한 데이터를 다른 사람과 공유하고 함께 수정을 해나가기 위해선 Local Repository만으론 불가능하다.
Local Repository가 서울 도서관이라면 Remote Repository는 대한민국 중앙 도서관인 것이다.
Local Repository와 Remote Repository 는 여러개가 존재할 수 있다. 다만 이 글에서는 n : 1 의 관계로 Local Repository와 Remote Repository를 설명하고자 한다.
각 Local Repository 에서 수정 / 생성 / 삭제 등을 거친 데이터들을 Remote Repository에 모아 거대한 하나의 데이터를 만든다. Remote Repository에는 N명의 개발자가 작업한 결과물이 동기화 되어 있다. Remote Repository에 데이터를 모으고 모인 데이터를 가져오는 방법은 무엇인지 알아보자.
Fetch & Merge / Pull
Remote Repository에서 데이터를 가져온다는 것은 Local Repository에 없지만 Remote Repository에는 있는 데이터를 가져와 병합한다는 의미를 가진다. 이를 Fetch & Merge 또는 Pull 이라고 한다.
Fetch는 Remote Repository의 데이터를 가져오기만 한다. Local Repository에 병합하지는 않는다. 수동으로 Merge 해줘야 한다.
반대로 Pull 은 Fetch & Merge 를 한 번에 처리한다.
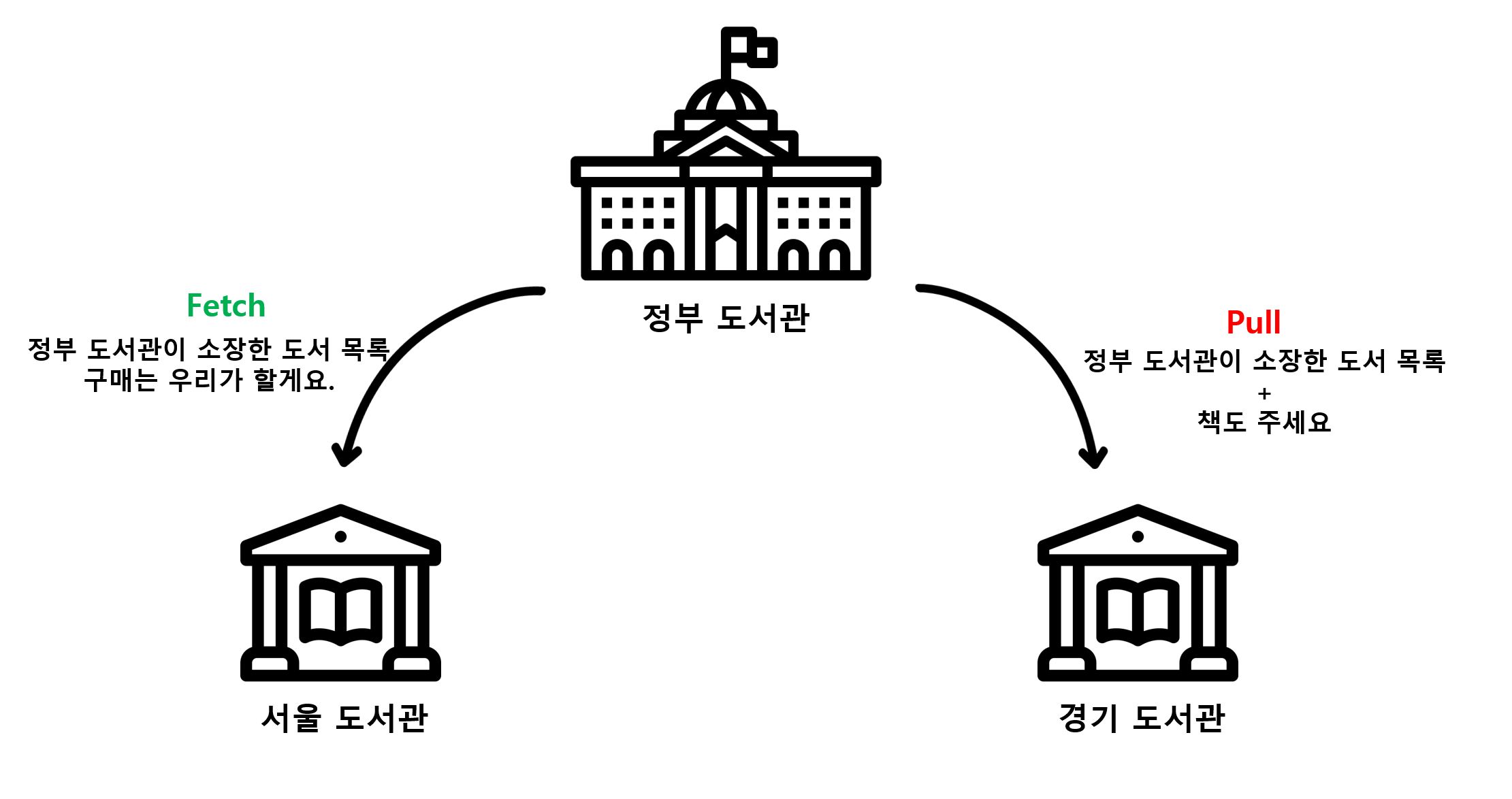
Fetch & Merge 와 Pull 중 어떤 것을 쓰라 라고 강제할 필요는 없다. 상황에 따라 유동적으로 이용하면 된다. Remote Repository 와의 병합을 상세하게 진행 해야하는 상황에선 Fetch & Merge를 이용한다. 간단한 병합이고 Conflict 에 대한 위험이 적으면 Pull을 이용하면 된다.
우리는 좀더 세밀한 병합을 할 수 있는 Fetch & Merge 에 대해서 알아볼 것이다.
우선 Remote Repository에서 데이터를 가져와보자.
Fetch - Remote Repository 로부터 데이터 가져오기
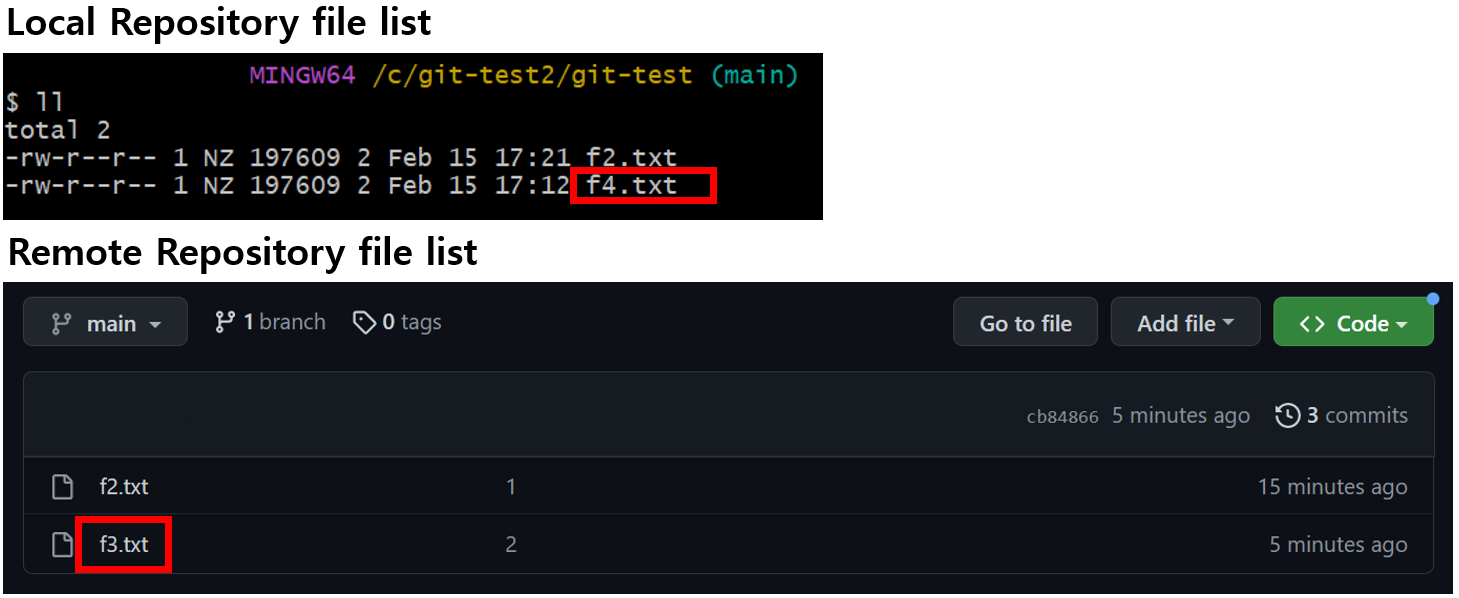
보다시피 Local Repository 와 Remote Repository 의 파일 리스트가 다르다. Remote Repository로부터 데이터를 가져와보자.
$ git fetch origin <Branch_Name>
Fetch는 Remote Repository의 최신 commit 데이터를 가져와 임시 Branch인 FETCH_HEAD에 저장한다.

임시 Branch로 저장된 FETCH_HEAD 의 데이터를 볼 수 있는 방법은 2가지이다.
먼저 FETCH_HEAD로 checkout 해보자.
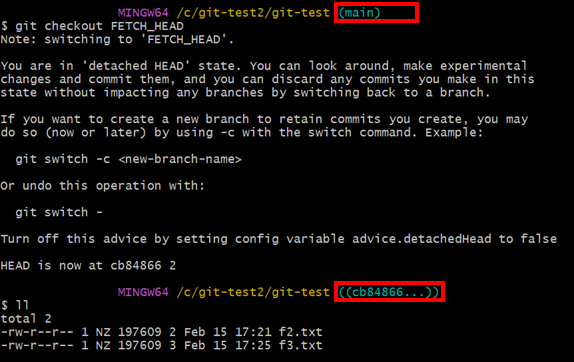
말한대로 FETCH_HEAD도 임시’Branch’이기 때문에 checkout 이 가능하다. main 에서 cb84866… 으로 checkout 된 것을 확인할 수 있다. file list 역시 Remote Repository의 내역과 동일하다. 그러나 이 상태로 파일을 하나 하나 열어 Local과 비교하기엔 너무 비효율적이다. 이때 이용할 수 있는 명령어가 git diff 이다.
git diff - 데이터 비교하기
$ git diff HEAD..FETCH_HEAD
위 명령어를 입력하면 최신 commit인 HEAD를 기준으로 Remote Repository의 데이터를 가지고 있는 FETCH_HEAD 의 데이터를 비교하는 내용을 출력해준다.
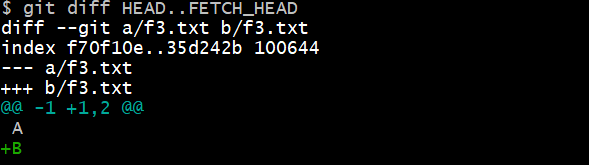
비교를 위해 main에 f3.txt 파일을 만들고 그 내용을 Remote Repository와는 조금 다르게 작성하였다.
a/f3.txt: 최신 commit인 HEAD 의 파일이다.b/f3.txt: Remote Repository의 데이터를 가진 FETCH_HEAD의 파일이다.
+B 인 부분은 HEAD엔 없는 데이터를 FETCH_HEAD가 가지고 있다는 것이다.
diff 를 통해 데이터를 비교 해보니 그대로 Merge 해도 큰 문제가 발생하지 않는다.(혹은 쓸모없는 데이터가 병합되지 않는다.)
이제 merge를 해보자.
$ git merge FETCH_HEAD
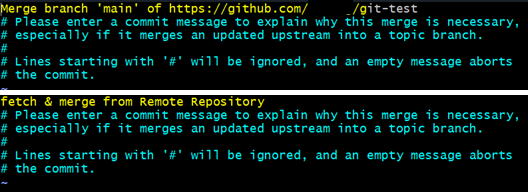
같은 파일이 수정된 경우 Conflict 없이 정상 병합이 되었다면 다음과 같이 Commit message 를 작성하게 된다. 새로운 commit이 생성된다는 것이다. 그 이유는 아래 git log 를 보면 알 수 있다.

Remote Repository의 aba478a (origin/main) 8과 Local Repository의 HEAD 가 병합되어 740e055 라는 최신 commit이 새로 생성되었다. graph의 형태를 보니 Merge 섹션에서 알게된 3-way Merge 가 적용된 것을 알 수 있다.
반대로 Local Repository 에서 업데이트된 데이터를 Remote Repository에도 추가하고 싶다면 어떻게 하면 될까?
Push - Remote Repository 업데이트 하기
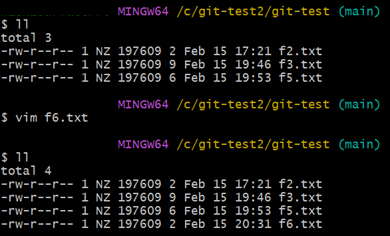
push를 하려면 Git에게 Local Repository 가 업데이트 되었음을 알려줘야 한다. 테스트를 위해 f6.txt 라는 파일을 새로 만들었다.
도서관 사서 Git을 이용해보자 이 과정은 지금까지의 학습한 내용을 그대로 반복하는 것과 같다.
먼저 git status 로 새로 만든 파일을 Git이 인식하고 있는지 확인한다.
$ git status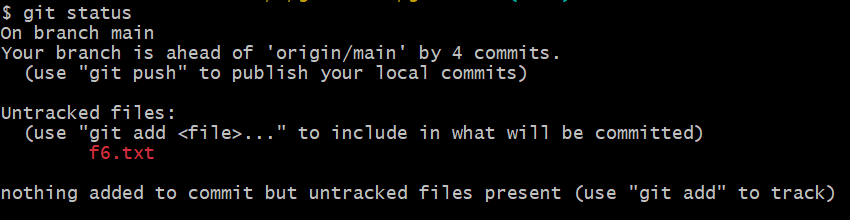
Untracked files 라고 출력된 것을 보니 Git은 아직 f6.txt 를 관리하지 않고 있다. git add 명령어를 통해 Git이 새로 만든 파일을 Tracked(추적, 관리) 하게 하자.
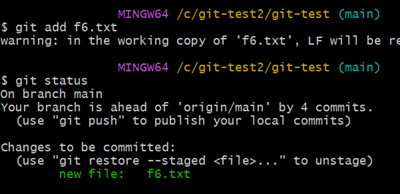
이제 Git이 f6.txt 파일을 new file 로 인식하였다.
Changes to be committed 라는 출력 문구처럼 git commit 하여 Git이 Git Repository에 해당 파일을 정리하여 완전히 관리할 수 있도록 하자.
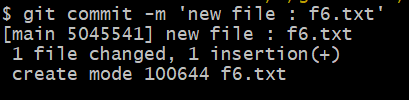
새로운 commit이 생성되었다. git log [option] 명령어로 확인해보자.

fetch & merge 섹션에서 확인했던 commit에서 추가되어 f6.txt 파일에 대한 새로운 commit을 확인할 수 있다.
그리고 밑으로 origin/main 이라는 Remote Repository도 보인다. 우리가 목표로 하고 있는 곳이다.
이제 push 명령어를 통해 origin/main 에 최신 commit을 업데이트하자.
$ git push origin main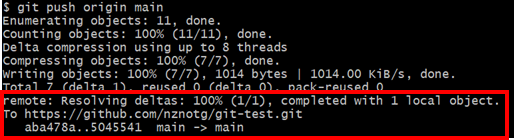
명령어 입력 후 우리가 알아야 할 정보는 위 이미지에 표시한 내역이다. 자세히 보니 무언가 익숙한 것이 보인다.

git merge HEAD..FETCH_HEAD 명령어와 같은 구조로 보이는 log에서 확인할 수 있는 체크섬이다.
결국 우리가 입력한 push 명령어는 Remote Repository의 최신 커밋인 aba48a 와 Local Repository의 최신 커밋 5045541을 Remote 영역에서 merge 하는 것이다.
마무리
Git에 대한 정보가 넘쳐나고 있다. 이럴 수록 처음부터 마지막까지 일관된 내용으로 정리된 글을 찾아 읽어야 모르는 상황에서 무얼 모르는지도 모르게 되버리는 상태가 되지 않는다.
Git 공식 사이트에선 Pro Git 이라는 양질의 책 pdf를 무려… 무료 다운로드 받을 수 있도록 제공하고 있다. 책은 500여 페이지에 달하며 그 내용은 아주 기본적인 것부터 Git의 심화 버전까지 책 한 권만으로도 제목 그대로 Pro Git 에 도달할 수 있도록 도와준다.
이 글 역시 책 Pro Git을 토대로 Git의 개념과 동작 원리를 이해하는데 중점을 두고 있다. Git 을 다루는데, 특히 CLI 로 Git을 다루는데 어려움이 있는 Git 입문자분들이 조금의 어려움이라도 해소가 됬다면 Git 공식 사이트로 달려가 Pro Git 책을 다운받아 읽어보자.
참조