Recently, the term “AI agent” has been coming up very frequently. At first, it felt like just another trend, but as I experienced various customer environments, I realized that there is definitely a growing demand for “a business agent engine that operates safely in our environment.”
Against this background, we began to consider implementing an Ops agent as a single backend service, targeting DevOps tasks that are closely related to our work. During the actual development process, we proceeded with the implementation with the help of coding agents like OpenAI Codex.
However, when I actually try to create it, questions arise that I quickly run into.
“Allow them to make autonomous judgments, but how far will you allow it?” “How will you stop it when mistakes happen?” “Can the intermediate process be reliably observed?”
It started simply with 'question → tool invocation → answer', but as actual requests became more complex, the following issue recurred.
- The checks go well, but the actions do not flow naturally from them.
- It's unclear whether there was a mid-judgment or if it was just following the prescribed recipe.
- The output looks plausible, but it subtly deviates from the execution result.
- It is difficult to analyze the cause with just logs when digging into the same problem again.
This article is a record of the current architecture and mechanism整理 as well as why it was designed this way, based on the trial and error process.
Principles to Adhere to in Development
First, we made the principles clear. If the principles waver, the implementation may seem quick, but in the end, it only increases rework (refactoring).
- Hardcoding domains in the main body (runtime/flow/resolver) is prohibited
- Behavior control should prioritize declarative externalization of contracts/policies over code branching
- Actions should be autonomous, but only within guardrails
- Both results and processes must be verifiable/observable
The key is not to oppose 'autonomy' and 'control'. Autonomy is the flexibility of judgment, and control is a mechanism to reduce the radius of failure.
Architecture Summary
The patterns organized in implementation are as follows.
LLM + Tools + State + Control + Guardrails
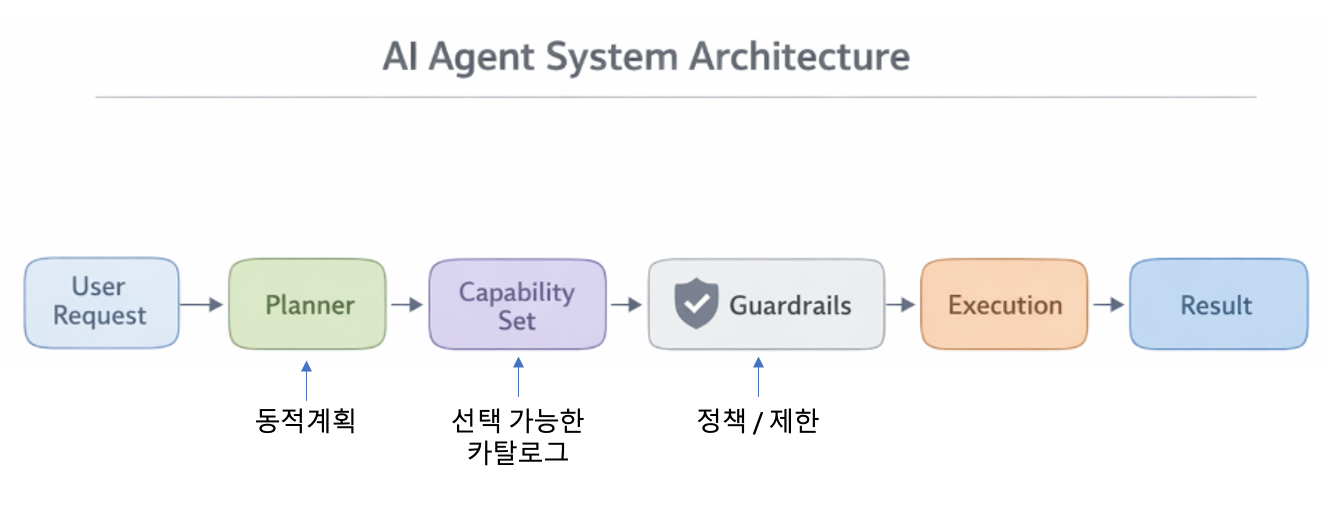
And the operation method is viewed along the following four axes.
Dynamic Plan + Strict Validation + State Transition contract + observation/FeedBack
State Transition based execute (State Machine) Diagramram
1) Dynamic Programming: 'What to do' is not fixed
User requests do not always come perfectly structured. For example, 'Check the development environment deployment status and take action' covers a wide range from status confirmation to mitigation measures.
The important thing here is not to hardcode all steps from the beginning. Instead, the Planner looks at the current request and context to create a plan and select the necessary capabilities.
However, allowing to choose 'anything' is risky, so the selectable abilities are limited to a catalog. In other words, it is dynamic but not unlimited.
For example, you can perform actions by selecting from a pre-prepared catalog, such as the ability to query Kubernetes.
2) Strict Verification: Plans must be filtered out before execution
Plans are not executed immediately after they are created. Contract verification is performed in the preflight stage.
The validation point is roughly like this.
- Is it in the list of allowed capabilities?
- Have the required prerequisites been included?
- Is the execution style (loop/recipe/conditional, etc.) aligned with the contract?
- Is the argument reference interpretable?
The reason this step is important is that it can change 'runtime failure' to 'pre-execution rejection/correction'. Issues such as non-existent capabilities or missing required arguments should be filtered out at this stage to reduce costs.
3) State Transition Contract: Specifies the step-by-step gates
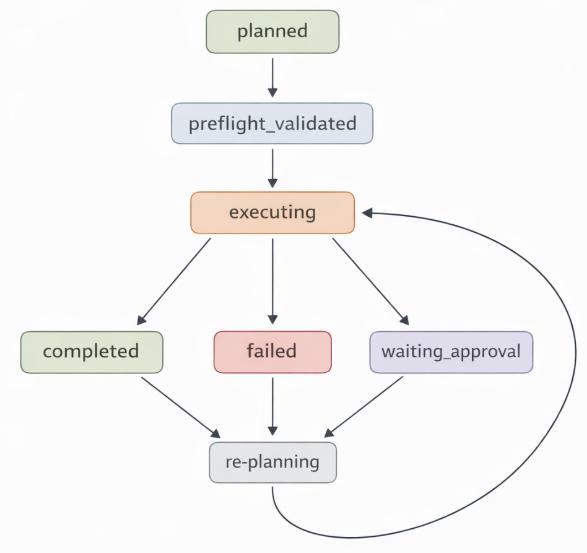
Treats a single request not as a one-off execution but as a state machine.
Example flow:
- planned
- preflight_validated
- executing
- completed / waiting_approval / failed / rejected
The key here is to specify in the contract 'when' you can move to the next state. In particular, requests that include actions may end with read-only observation, which can go against user expectations.
So, as I develop and test, I gradually strengthen the following agreements.
- If there is an anomaly signal and the user has included an intention to act, encourage re-planning the action branch.
- The high-risk measure is transferred to waiting_approval
- Immediately reject if the approval information integrity verification fails
4) Observation/Feedback: It seems late just looking at the results
In order to optimize the summary analysis of request units, a logging system should be established and continuously improved in line with feature upgrades.
- request-analysis: state transition path, failure cause, LLM call count, etc.
- request-answer: final response
The advantage of this method is that it is low-cost and allows for quick root cause analysis during operation. The disadvantage is that it is difficult to completely replay intermediate stream events.
Nevertheless, it is still sufficiently valid for the current purpose (efficiency/quality analysis). In particular, to enable rapid problem analysis, you must be able to answer the following questions quickly.
- Why was it failed/rejected?
- At which capability was it blocked?
- Why has the LLM invocation increased?
- Does the final response match the execution result?
Does a 'contract-based' approach conflict with autonomy?
I've been contemplating this a lot, and to conclude, there is no conflict. Rather, they are complementary.
- Autonomy: which combination of capabilities to choose, in what order to replan
- Contract: what is prohibited/mandatory, and which state transitions are allowed
Without a contract, autonomy can easily become reactive. Without autonomy, the contract becomes just a static workflow.
Realistically, I believe that 'autonomous orchestration on a contract-based guardrail' is the most balanced structure.
To summarize the current progress
Improvements:
- State transition/failure cause/call count analysis has become possible
- The boundary of read-only/approval/action has become clearer
- Some redundant loops and unnecessary calls have been reduced.
Remaining points:
- We need to increase the satisfaction rate before taking action for requests like 'Please take action'.
- The consistency of the response format (especially section boundaries) needs to be tightened.
- We need to increase the versatility of the contract-based replanning loop.
In other words, we are moving from 'operating' to 'operating consistently as expected.'
Conclusion
When creating an agent, it's easy to only talk about model performance. However, what's more important in an operational agent isStructural ReliabilityI think so.
- Plans should be flexible according to the situation.
- Execution must be verified in advance
- State transitions must be controlled by contract
- The process must be observable, not just the results.
The Ops Agent has gone through the following steps aiming to become a universal agent.
- Fixed stage of the scenario
Initially, we focused on executing a predefined flow centered around scenarioId/scenarioType in a stable manner. The advantage was predictability, while the limitation was low flexibility for new requests.
- Contract-centric control stage
Next, we began to explicitly manage 'what can and cannot be done' by attaching capability catalogs, preflight validation, approval gates, and response contracts. At this stage, reliability increased, but there were still cases where the plan was close to a recipe.
- Current: Guardrails + Contract-based Autonomous Orchestration
We currently focus on dynamic planning, controlling execution through strict validation and state transition contracts (e.g., planned → validated → executing → waiting_approval/completed). Additionally, we are progressively enhancing the replanning loop by tracking failure causes and recurring patterns through observation logs.
There is still a long way to go. However, I believe that by starting from a fixed scenario and going through contract-based control, we have moved closer to 'explainable execution' with the current guardrails and contract-based autonomous orchestration.
It's more about continuous improvement than completion, but we are striving to establish a solid foundation, and we plan to validate on a small scale and expand securely based on the same principles in the future.
Andy