데이터베이스 테이블 파티셔닝 및 인덱스 설정의 중요성
1. 개요
한 기업의 차세대 ISS 프로젝트는 선박 데이터 모니터링과 육상 데이터 모니터링이라는 두 가지 기능으로 구분할 수 있다.
선박에서 수집된 센서 데이터는 1초, 10초, 1분 등 다양한 주기를 갖는 데이터로 전환되어 선박 데이터베이스에 저장된다.
이러한 선박 데이터는 육상으로도 전송되어 육상 데이터베이스에 저장되는데, 그중 1분 데이터는
history_minute
라는 테이블에 영구 보관된다.
2024년부터 시작해서 현재까지 약 430GB에 달하는 분 데이터가 육상
history_minute
테이블에 저장되었고, 현재 약 4.5억 건이 넘는 데이터를 보유하고 있는 상황이다.
필자는 육상 history_minute 테이블에서 선박별 분 데이터를 조회하여 센서 데이터 이상치를 감지하는 기능을 개발하던 중 어려움을 겪었다.
한 번에 조회해야 할 분 데이터는 대략 30,000~40,000건의 데이터이고, 선박 수만큼 반복하여 실행해야 했기에 DB 성능 및 부하를 고려하여 조회 쿼리를 만들어야 했다.
이러한 상황에서는 조회 성능을 향상하여 데이터 조회 시간을 효과적으로 단축하는 것이 필요했는데, 이때 적용할 수 있는 것이 바로 테이블 파티셔닝과 인덱스였다.
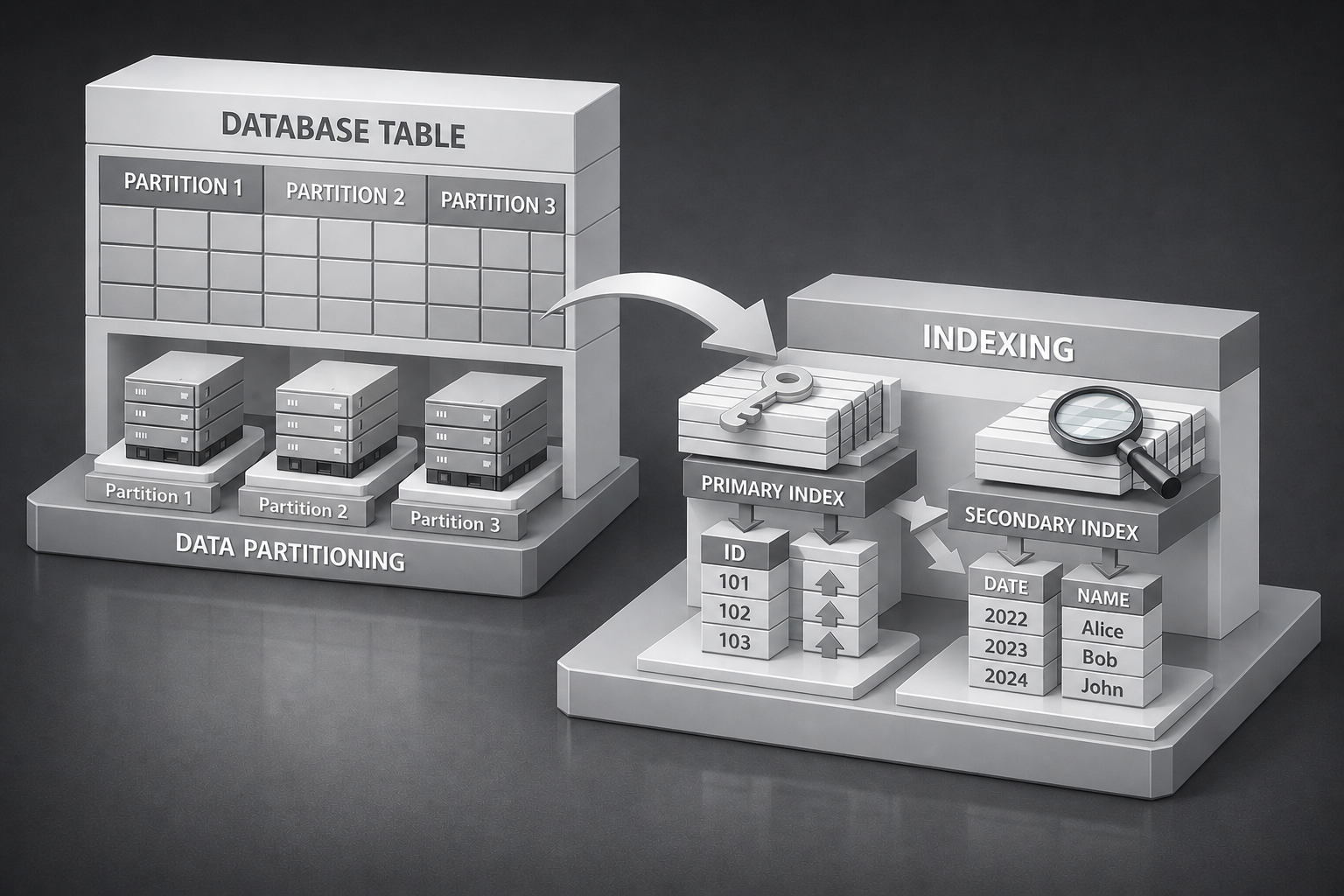
2. 테이블 파티셔닝 (Table Partitioning)
테이블 파티셔닝은 하나의 논리적 테이블을 물리적으로 여러 조각으로 분리해서 저장하는 기법이다. 대표적인 파티셔닝 기법으로는 범위 파티셔닝과 목록 파티셔닝이 있다.
1) 범위 파티셔닝 (Range Partitioning)
범위 파티셔닝은 특정 컬럼의 값 범위를 기준으로 데이터를 분할하는 기법으로, 일정 시간 간격으로 쌓이는 시계열 데이터에 적합한 방식이다.
예시)
CREATE TABLE history_minute (column1, column2…) PARTITION BY RANGE (time);
CREATE TABLE history_minute_202604 PARTITION OF history_minute FOR VALUES FROM 1775001600000 TO 1777593600000;2) 목록 파티셔닝 (List Partitioning)
목록 파티셔닝은 특정 컬럼의 값 목록을 기준으로 데이터를 분할하는 기법으로, 특정 컬럼의 값이 범위가 아닌 이산적인 값으로 서로 구분될 수 있을 때 사용한다.
예시)
CREATE TABLE history_minute (column1, column2…) PARTITION BY LIST (sourceid);
CREATE TABLE history_minute_generator PARTITION OF history_minute FOR VALUES IN ('Generator01', 'Generator02', 'Generator03'…);
history_minute
테이블의 경우 분 데이터의 timestamp를 통한 범위 파티셔닝을 적용하여 월별 파티션으로 분할하였다.
이때 파티션 테이블은 서비스단에서 해당 DB의 파티셔닝 프로시저를 주기적으로 호출하여 생성되며,
이를 통해 50GB 내외의 파티션 테이블로 분 데이터를 분할할 수 있었다.
3. 인덱스 (Index)
인덱스는 테이블의 특정 컬럼에 대해 별도로 만들어 두는 정렬된 자료구조이다.
예시)
CREATE INDEX history_minute_time_idx ON history_minute (time);
history_minute
테이블에 인덱스가 없는 경우, DB는 약 4.5억 건이라는 다량의 데이터를 전부 읽으면서 조건을 비교해야 하는 상황이 발생하여 서버에 엄청난 부하를 안겨줄 수 있다.
이를 방지하기 위해 인덱스는 필수적으로 존재해야 한다.
다만 인덱스 생성 시 고려해야 할 점이 있었다.
- 인덱스 생성 시 INSERT/UPDATE/DELETE 성능 저하 발생
- 인덱스에 대한 추가적인 저장 공간이 발생
현재 history_minute 테이블에 추가로 새로운 인덱스
(vesselid, time desc, sourceid)
를 생성할 경우, 운영 중인 서버에 부하 및 성능 저하가 발생한다는 위험 부담과 DB 저장 용량이 얼마나 늘어날지 모른다는 불확실성이 있었다.
실제로 개발 서버에서 테스트해 본 결과, 약 20GB 정도의 파티션 테이블에서 인덱스 하나만 추가해도 용량이 10% 증가하는 것을 볼 수 있었다.
따라서 최적의 인덱스는 아니지만 이미 존재하는 복합 인덱스
(sourceid, vesselid, time)
를 사용하여 조회 쿼리를 작성하였다.
이를 통해 불필요한 DB 저장 공간을 낭비하지 않고, 조회 시간을 수분에서 수초~수십 초로 단축할 수 있었다.
deeeneee