1. 들어가며
의료 시스템 MSA 전환 프로젝트에 참여하면서 맞닥뜨린 문제는 데이터 이원화였습니다. 신규 MSA 시스템(PostgreSQL)과 기존 레거시 시스템(Oracle)이 나란히 운영되어야 했고, 두 시스템이 동시에 서비스 중인 상황에서 데이터 일관성을 실시간으로 유지해야 하는 요구사항이 있었습니다.
배치 동기화는 수십 분의 지연이 발생해 의료 도메인에서는 적합하지 않았고, DB 트리거 방식은 레거시 Oracle에 운영 부담을 더했으며, 애플리케이션 이중 쓰기는 트랜잭션 원자성을 보장하기 어려웠습니다. 여러 방식을 검토한 끝에, 소스 DB 내부의 트랜잭션 로그를 직접 읽어 비동기로 전파하는 CDC(Change Data Capture) 방식을 채택하게 되었습니다.
2. 아키텍처: Debezium과 커스텀 동기화 애플리케이션
Debezium은 PostgreSQL의 WAL(Write-Ahead Log)을 직접 구독하여 INSERT/UPDATE/DELETE 이벤트를 실시간으로 Kafka에 발행하는 오픈소스 CDC 플랫폼입니다. 소스 DB에 트리거나 코드 변경 없이 WAL 로그만 읽는 방식이라 레거시 시스템을 건드리지 않아도 되었고, 커넥터가 재시작되더라도 마지막으로 처리한 로그 위치(LSN)부터 이어받을 수 있다는 점이 이 프로젝트 요구사항에 잘 맞았습니다.
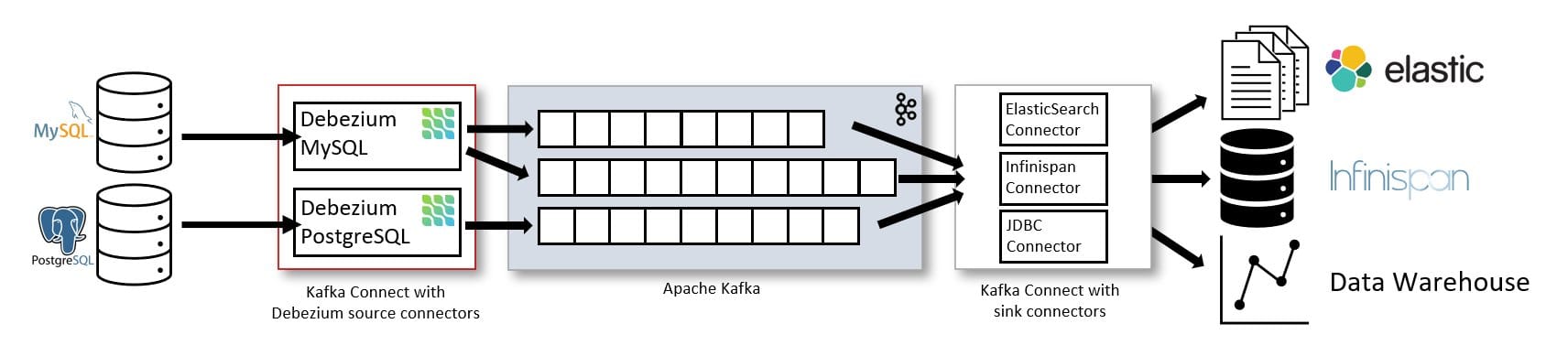
[그림 1] Debezium 공식 아키텍처 — 출처: debezium.io/documentation/reference/3.5 (Apache License 2.0)
|
구분 |
기술 |
역할 |
|---|---|---|
|
Source DB |
PostgreSQL |
데이터 변경 원천 (WAL 기반 CDC) |
|
CDC 엔진 |
Debezium 3.x |
WAL 감지 → Kafka 이벤트 발행 |
|
이벤트 버스 |
Apache Kafka |
at-least-once 전달 보장 (중복 발행 가능 → Consumer 멱등성 처리 필요) |
|
동기화 앱 |
Data-Sync (Spring Boot) |
이벤트 소비, Oracle 반영, 정합성 해시 저장 |
|
Target DB |
Oracle |
레거시 시스템 최종 동기화 대상 |
표준 Sink Connector 대신 커스텀 Spring Boot 애플리케이션(Data-Sync)을 직접 개발한 데는 크게 세 가지 이유가 있었습니다.
스키마 변환 - 레거시 Oracle의 복합 PK·비표준 컬럼명·타입 변환(timestamptz → TIMESTAMP WITH LOCAL TIME ZONE 등)은 표준 Connector 설정만으로는 대응하기 어려웠습니다.
오류 처리 - 오류 유형별로 재시도 주기와 알림 방식을 다르게 가져가야 했고, 이를 위해서는 커스텀 코드의 유연성이 필요했습니다.
정합성 검증 - 동기화 완료 후 데이터 해시를 비동기적으로 저장해 두 시스템 간 정합성을 주기적으로 검증하는 요구사항도 있었습니다.
3. 내구성 검증: 장애 대응 테스트
설계가 완성된 후, 실제 운영 투입 전에 시스템이 장애 상황에서도 데이터를 잃지 않는지 확인하고 싶었습니다. 개발 환경 Kubernetes 클러스터에서 시나리오별로 독립적으로 진행했으며, 매번 PostgreSQL에 20,000건의 데이터를 입력한 뒤 Oracle까지 유실 없이 적재되는지 검증했습니다.
|
시나리오 |
장애 조건 |
복구 메커니즘 |
결과 |
|---|---|---|---|
|
Kafka Partition Leader 장애 |
전송 중 리더 브로커 강제 중단 |
Kafka Controller가 ISR 내 다른 브로커를 리더로 선출, Debezium 자동 재연결 |
✓ 유실 없음 |
|
Kafka Cluster 전체 장애 |
전체 브로커 Pod 삭제 후 재배포 |
Kafka Connect 오프셋 토픽(PVC 보존)과 PostgreSQL Replication Slot이 협력하여 마지막 LSN부터 WAL 이어받기 |
✓ 유실 없음 |
|
Debezium Connector 장애 |
CDC 처리 중 Connector 강제 종료 |
Replication Slot에 기록된 마지막 LSN부터 자동으로 WAL 읽기 재개 |
✓ 유실 없음 |
|
Kafka 클러스터가 완전히 재배포된 후에도 데이터 유실이 없었던 것은 Kafka Connect 오프셋 토픽과 PostgreSQL Replication Slot이 함께 작동한 덕분입니다.
|
|---|
4. 마치며: 한계와 배운 점, 그리고 앞으로
◆ 초기 설계의 한계
동기화에 필요한 컬럼 정보를 Data-Sync 내부 메타데이터 테이블에 직접 저장한 방식은 한계가 명확했습니다. 특정 서비스의 컬럼 하나가 추가될 때마다 Data-Sync에도 변경이 필요한 구조가 되었고, MSA에서 지향하는 서비스 독립성이 데이터 동기화 레이어에서 훼손되고 있었습니다. 이 문제를 해소하기 위해 Confluent Schema Registry와 Avro 포맷 도입을 검토하고 있습니다. Debezium 3.x에서 이미 공식 지원하는 기능으로, 이를 적용하면 Debezium이 스키마를 이벤트와 함께 Schema Registry에 자동 등록하고, Data-Sync가 동적으로 해석할 수 있어, 각 서비스가 Data-Sync와 독립적으로 스키마를 변경할 수 있게 됩니다.
◆ Debezium 3.x의 주요 변화 (2024~2025)
|
버전 |
핵심 변화 |
운영 관점 의미 |
|---|---|---|
|
3.1 (2025.04) |
Management Platform 공식 릴리즈 (Kubernetes UI) |
curl로 Pod에 직접 접속하던 운영 방식 → GUI로 대체 가능 |
|
3.4 (2025.12) |
PostgreSQL 17 Failover Slot · PG 18 지원 · Kafka 4.1 · OpenLineage 통합 |
DB failover 시 Slot 자동 이전 · pg_replication_slots 모니터링 필수 |
|
AI 통합 |
LLM·벡터 DB 연동 AI 모듈 추가 (Debezium Server Sink) |
CDC가 데이터 복제 도구를 넘어 AI 파이프라인 레이어로 진화 중 |
|
레거시 시스템을 건드리지 않으면서 데이터 흐름을 통제할 수 있다는 점이 이 방식의 가장 큰 장점이었습니다. MSA 전환처럼 두 시스템이 공존해야 하는 상황뿐 아니라, 캐시 갱신, 검색 인덱싱, 이벤트 기반 아키텍처 등 다양한 맥락에서도 응용해 볼 수 있는 접근이라는 생각이 들었습니다. 이번 프로젝트가 CDC를 처음 접하는 분들이나 유사한 데이터 동기화 문제를 고민하는 분들에게 조금이나마 도움이 되었으면 합니다. |
|---|
참고 문헌
[1] Debezium 공식 문서, debezium.io/documentation/reference/3.4
[2] Debezium 3.1~3.4 릴리즈 노트, debezium.io/blog
[3] Confluent Schema Registry, docs.confluent.io/platform/current/schema-registry
Juno